Generalized additive modeling
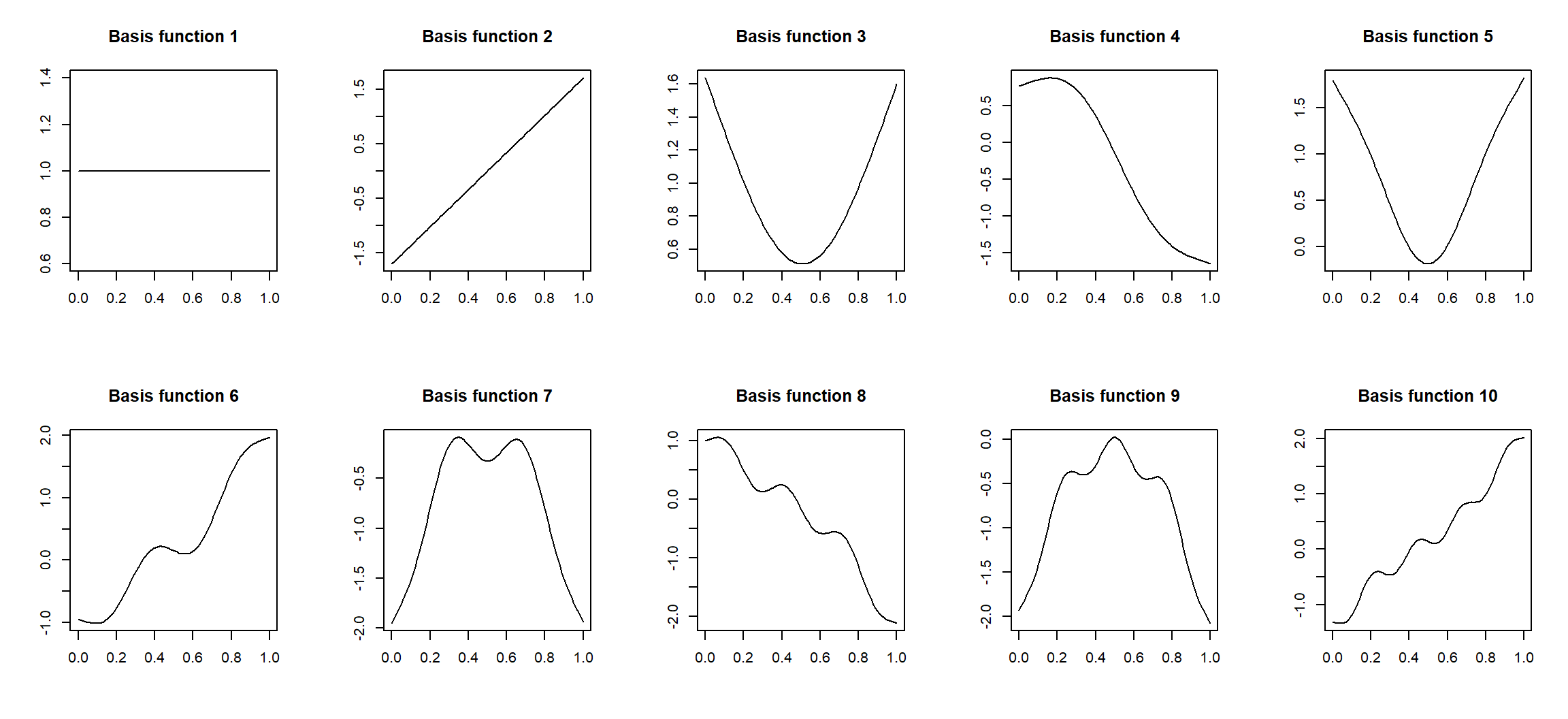
First ten basis functions
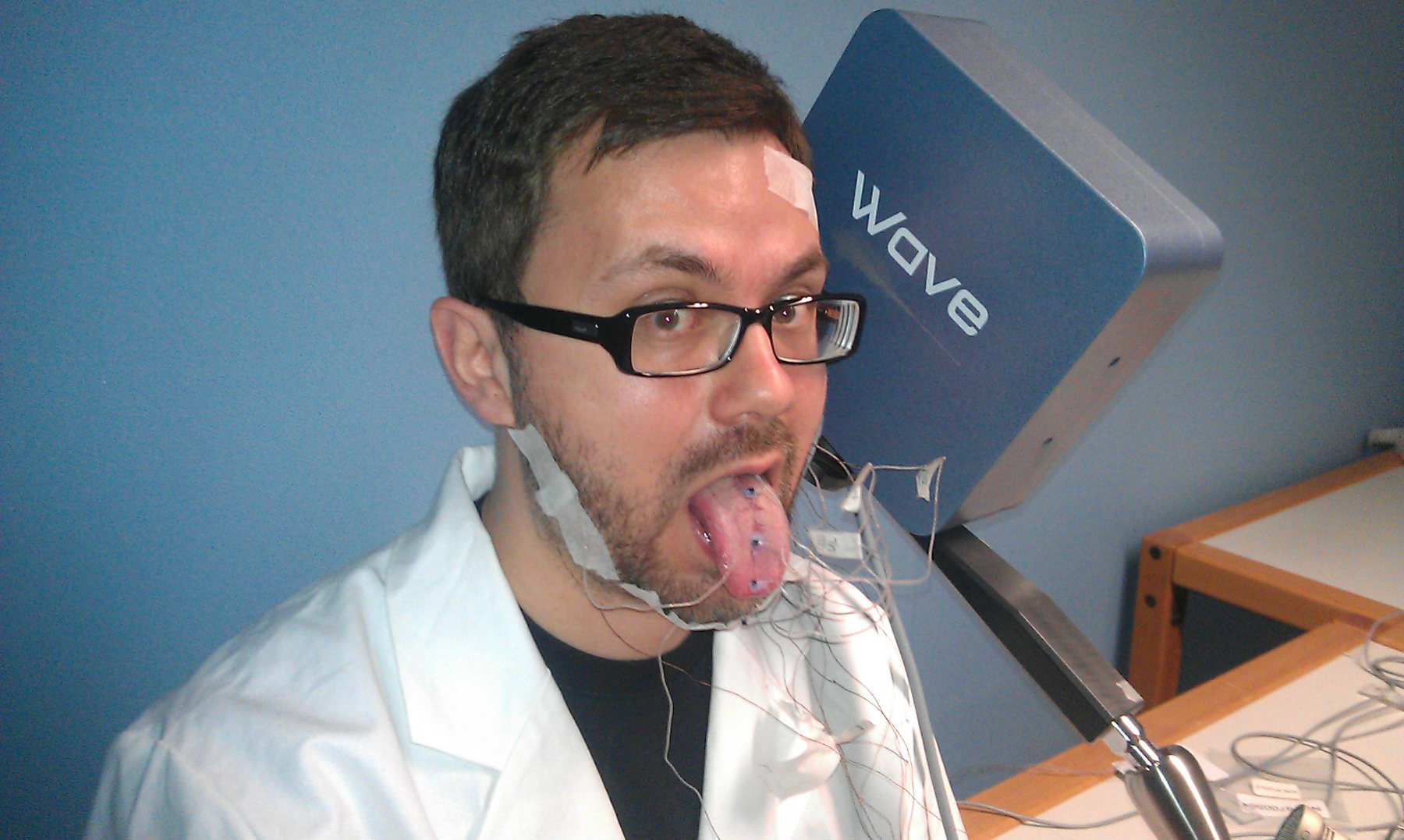
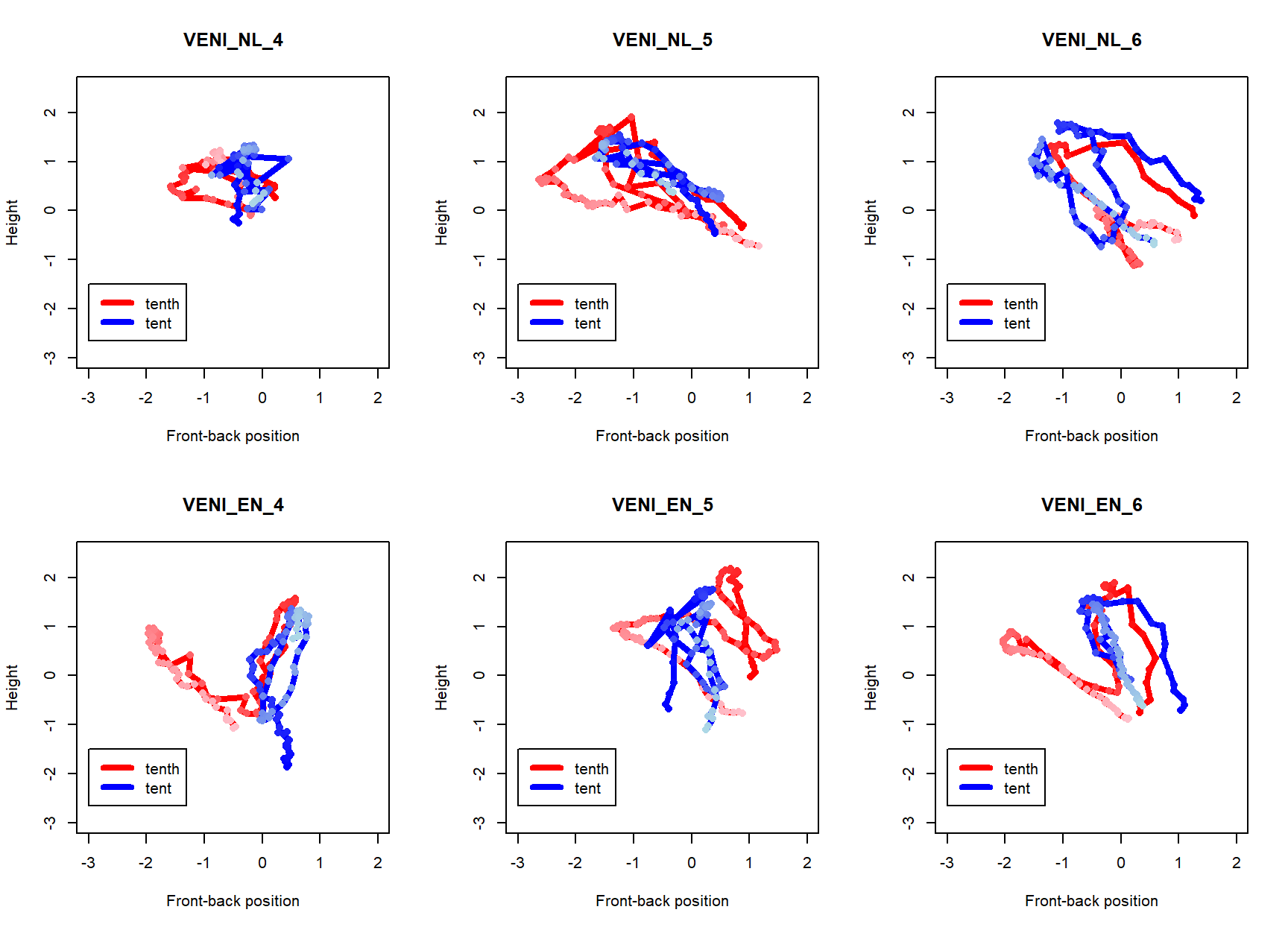
Articulography
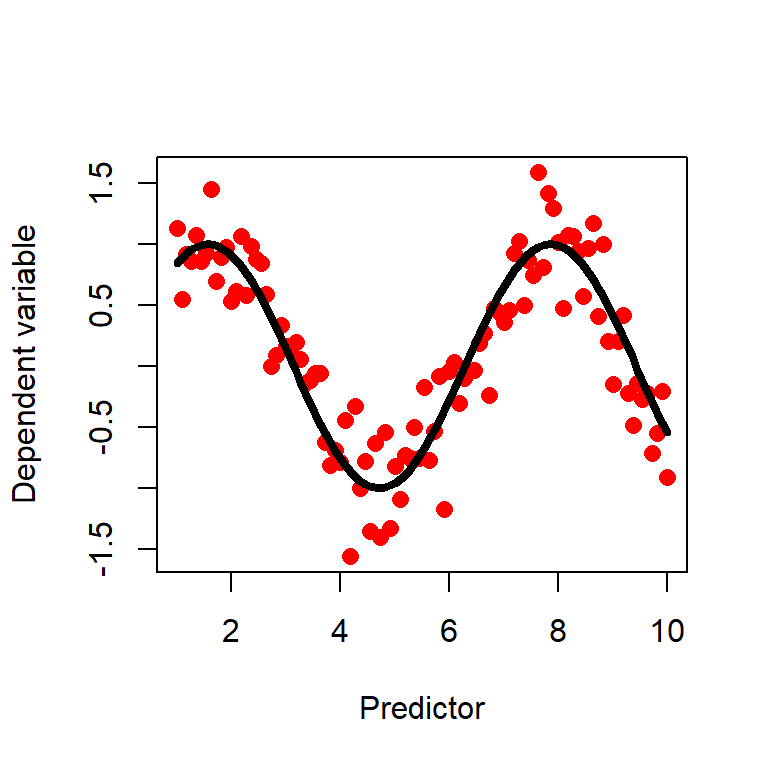
Data: much individual variation and noisy data
Visualizing the non-linear time pattern of the model
(Interpreting GAM results always involves visualization)
plot(m0, rug=F, scheme=1, main='Partial effect', ylab='TTfront', ylim=c(-1,1))
plot_smooth(m0, view='Time', rug=F, main='Full effect', ylim=c(-1,1))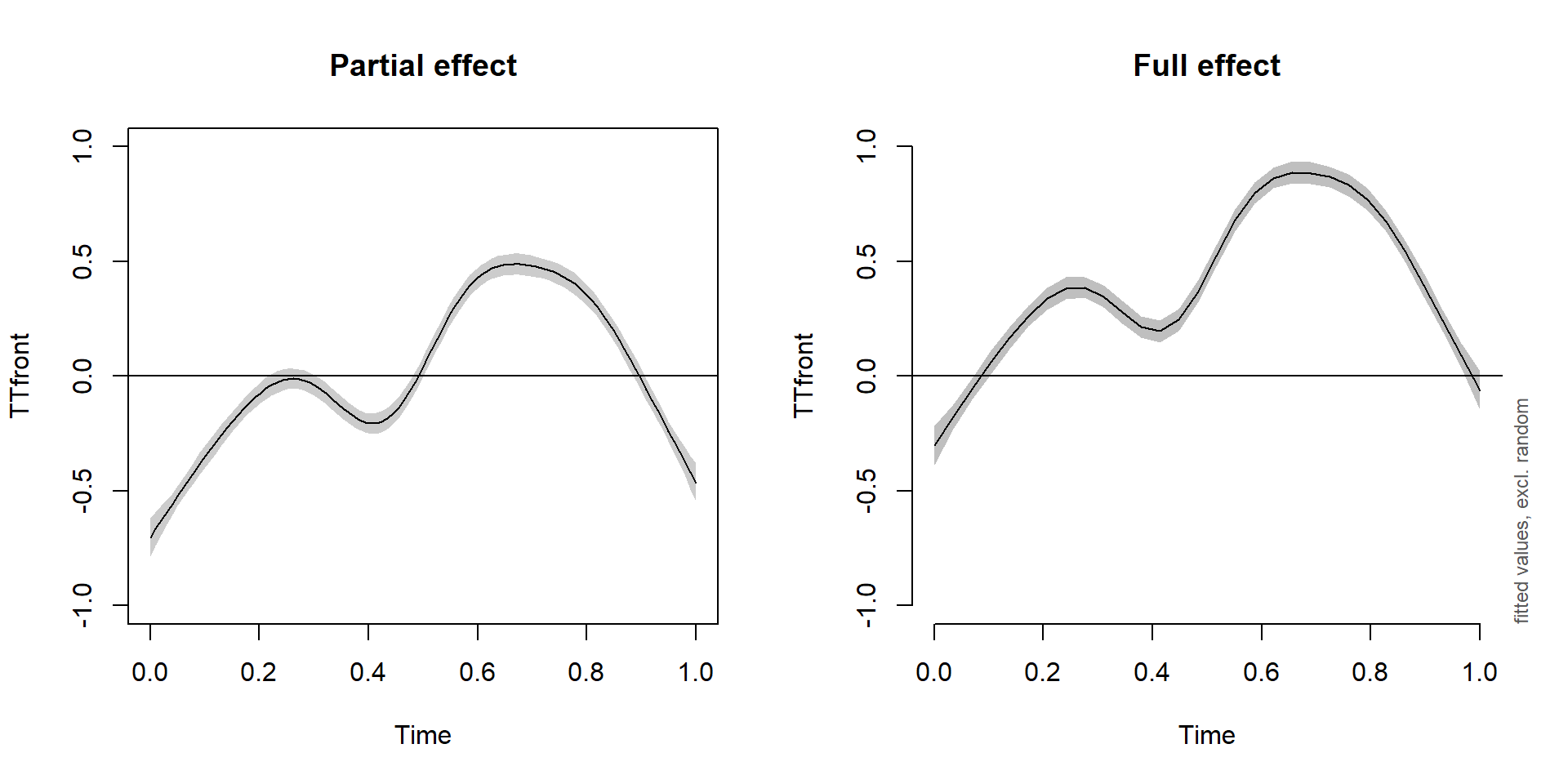
Effect of increasing \(k\)
plot_smooth(m0, view='Time', rug=F, main='m0 (k=10)')
plot_smooth(m0b, view='Time', rug=F, main='m0b (k=20)')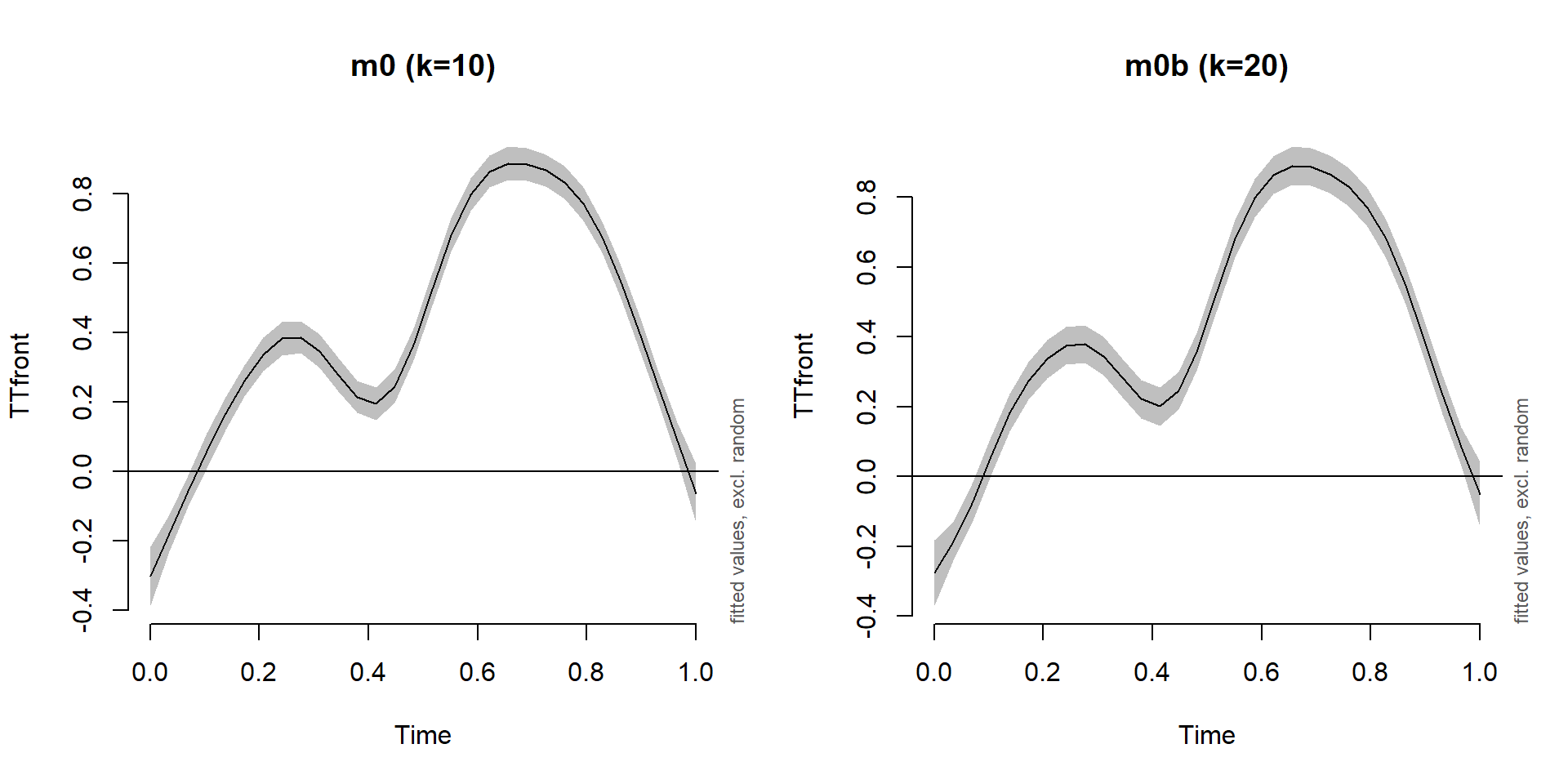
Effect of including a random intercept
plot_smooth(m0, view='Time', rug=F, main='m0', ylim=c(-0.5,1.5))
plot_smooth(m1, view='Time', rug=F, main='m1', ylim=c(-0.5,1.5))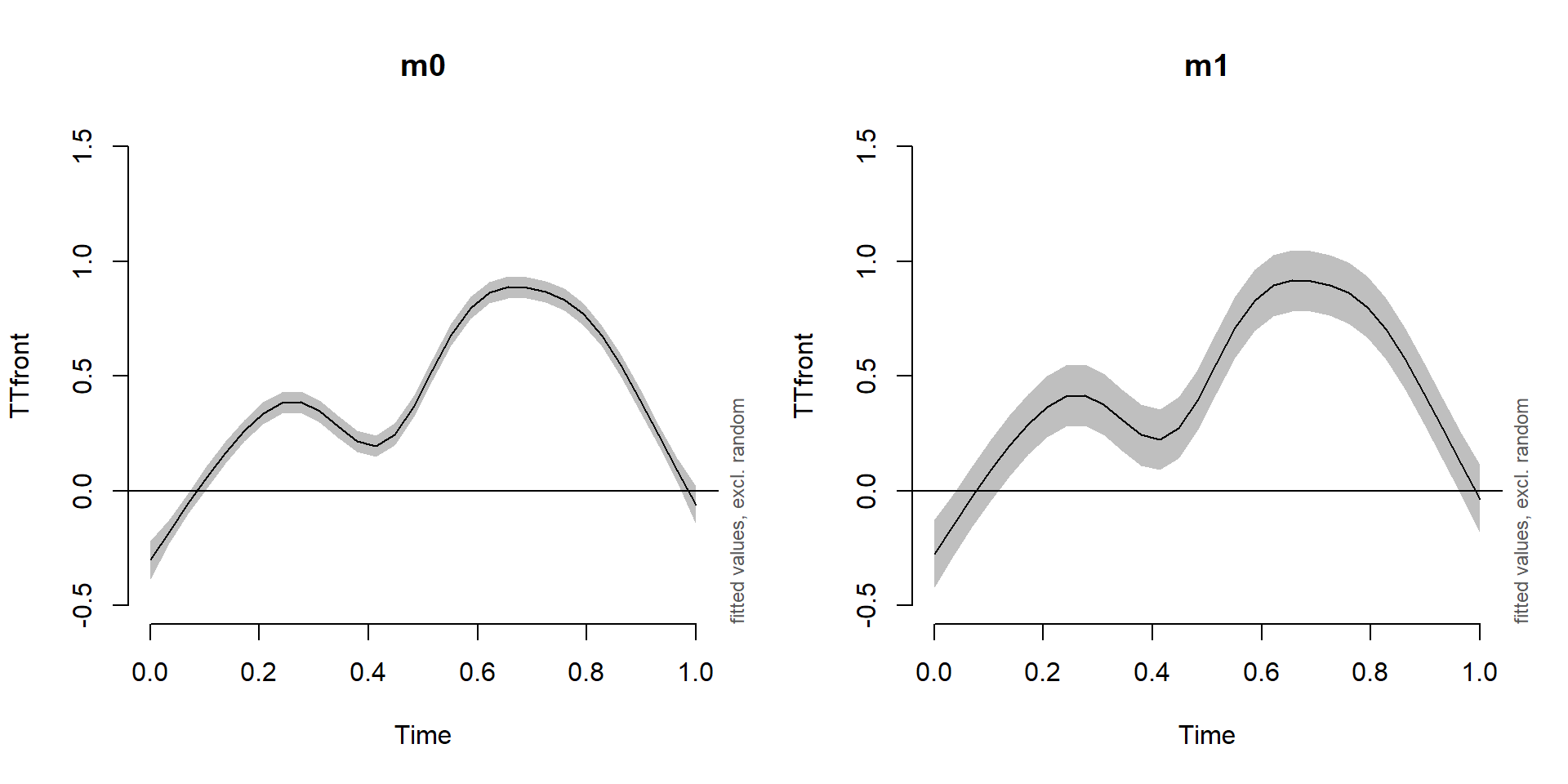
Effect of including a random slope
plot_smooth(m1, view='Time', rug=F, main='m1', ylim=c(-0.5,1.5))
plot_smooth(m2, view='Time', rug=F, main='m2', ylim=c(-0.5,1.5))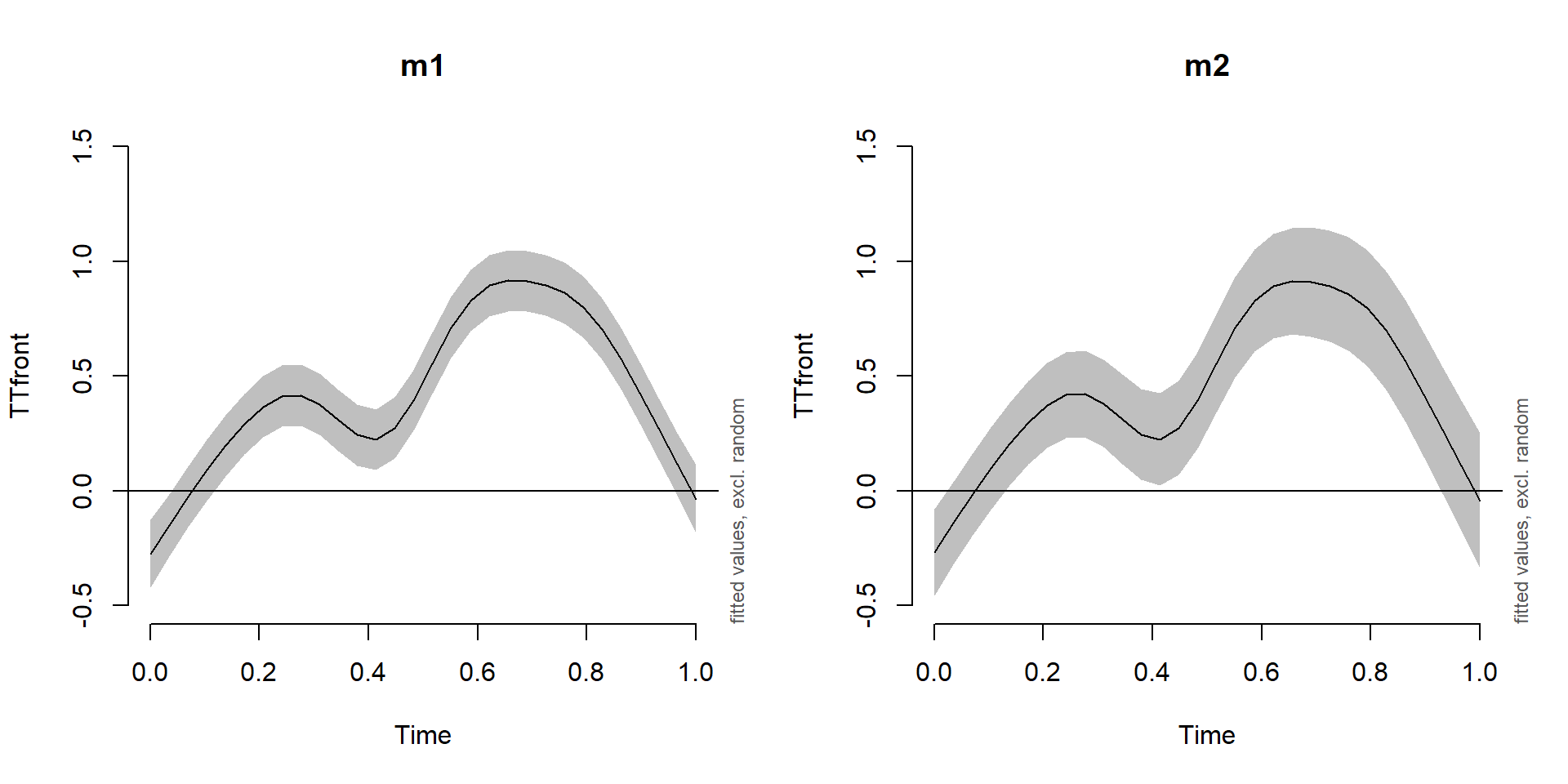
Visualization of individual variation
plot(m3, select=2)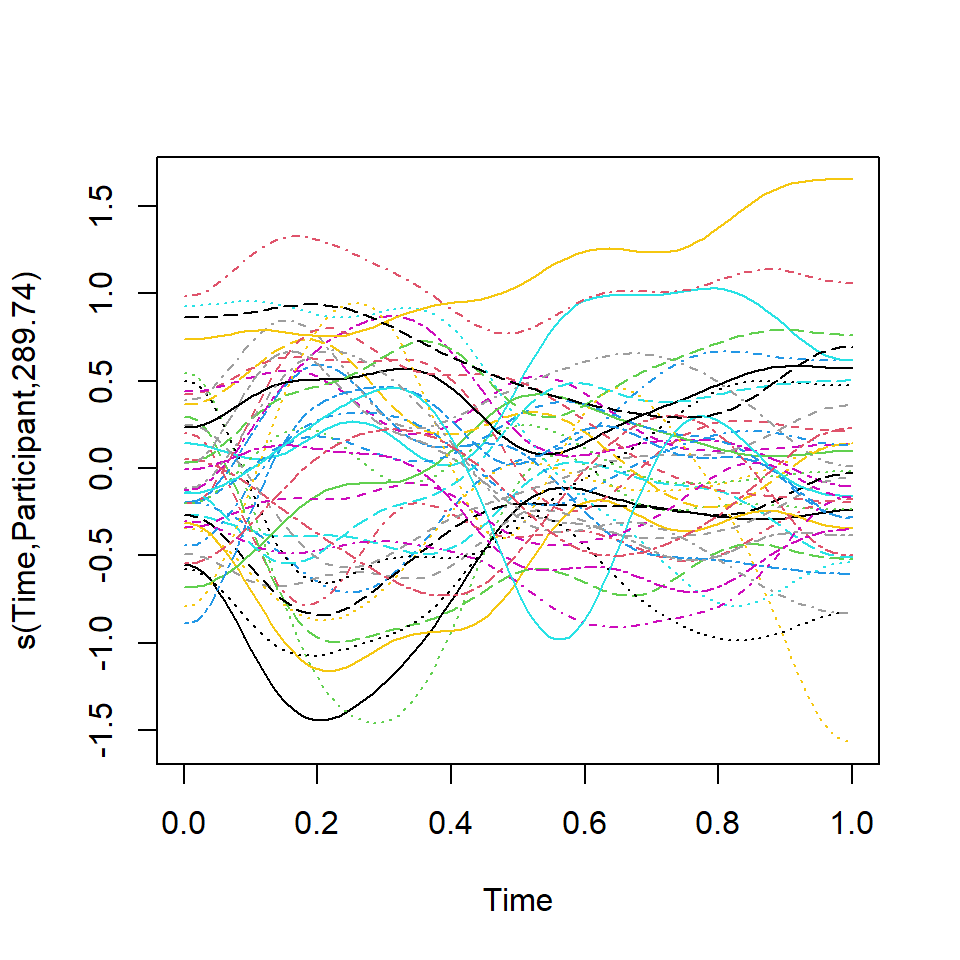
Effect of including a random non-linear effect
plot_smooth(m2, view='Time', rug=F, main='m2', ylim=c(-0.5,1.2))
plot_smooth(m3, view='Time', rug=F, main='m3', ylim=c(-0.5,1.2))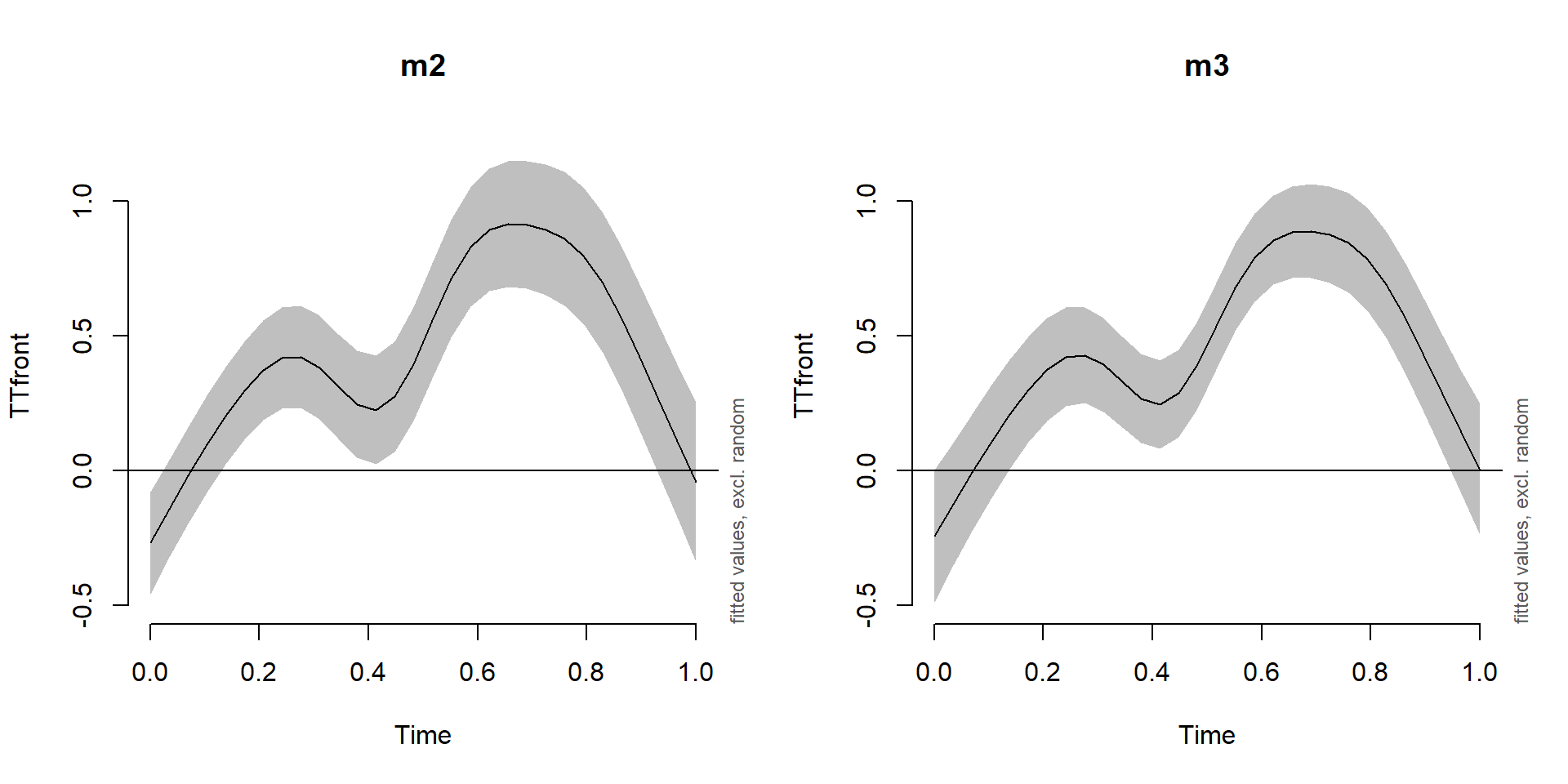
Visualizing the two patterns
plot_smooth(m4, view = "Time", rug = F, plot_all="Word", main = "m4", ylim = c(-0.5,2)) 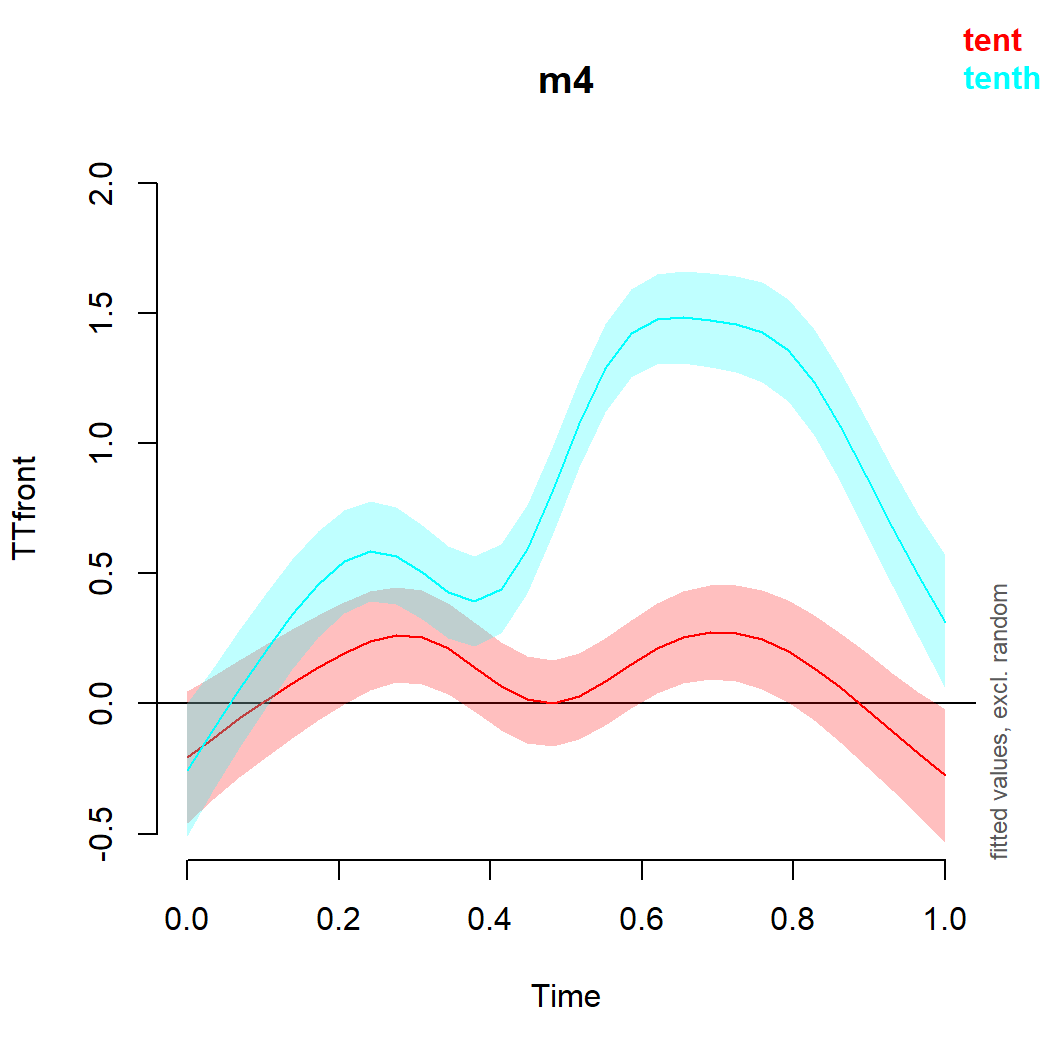
Visualizing the difference
plot_diff(m4, view='Time', comp=list(Word=c('tenth','tent')), ylim=c(-0.5,2))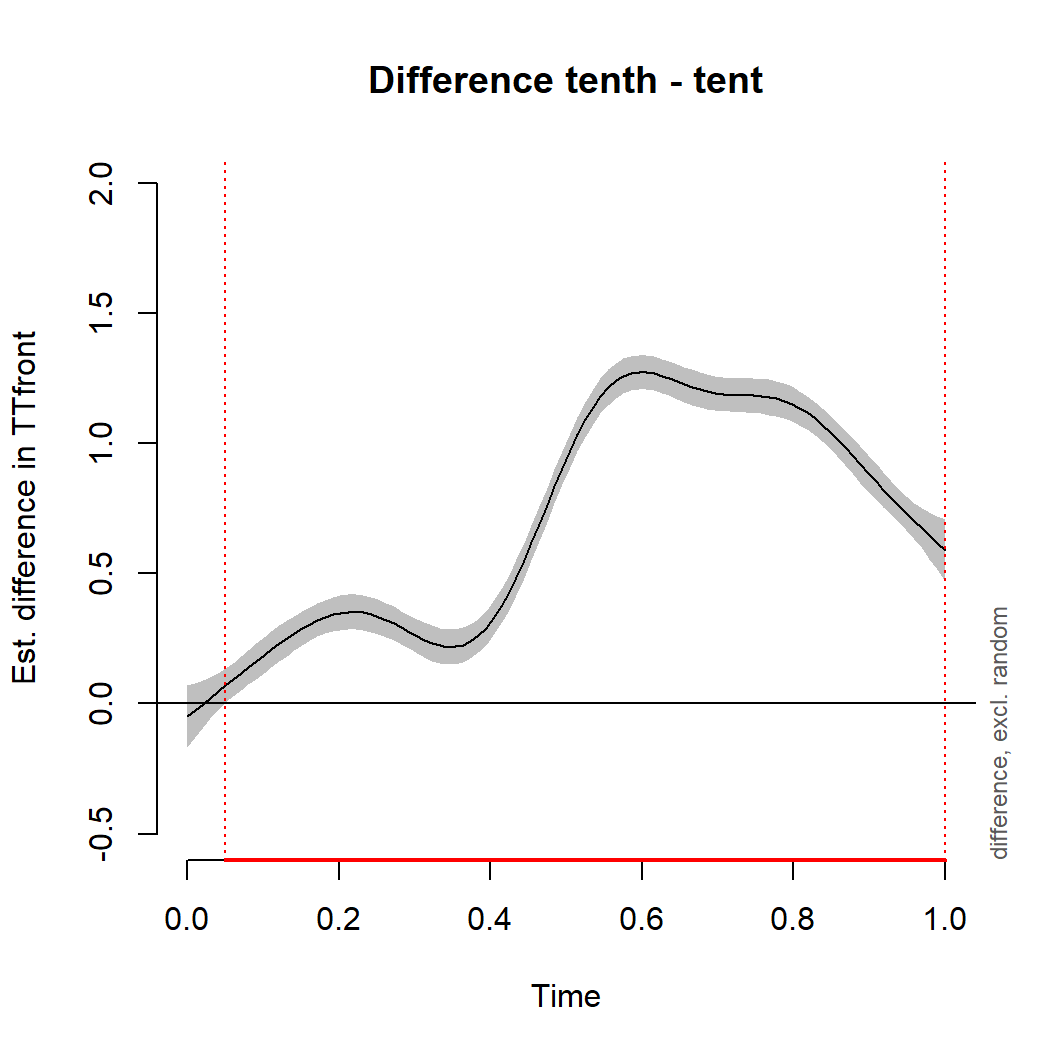
More uncertainty in the difference
plot_diff(m4, view="Time", comp=list(Word=c("tenth","tent")), ylim=c(-0.5,2),
main="m4: difference") # anti-conservative
plot_diff(m5, view="Time", comp=list(Word=c("tenth","tent")), ylim=c(-0.5,2),
main="m5: difference") # overly conservative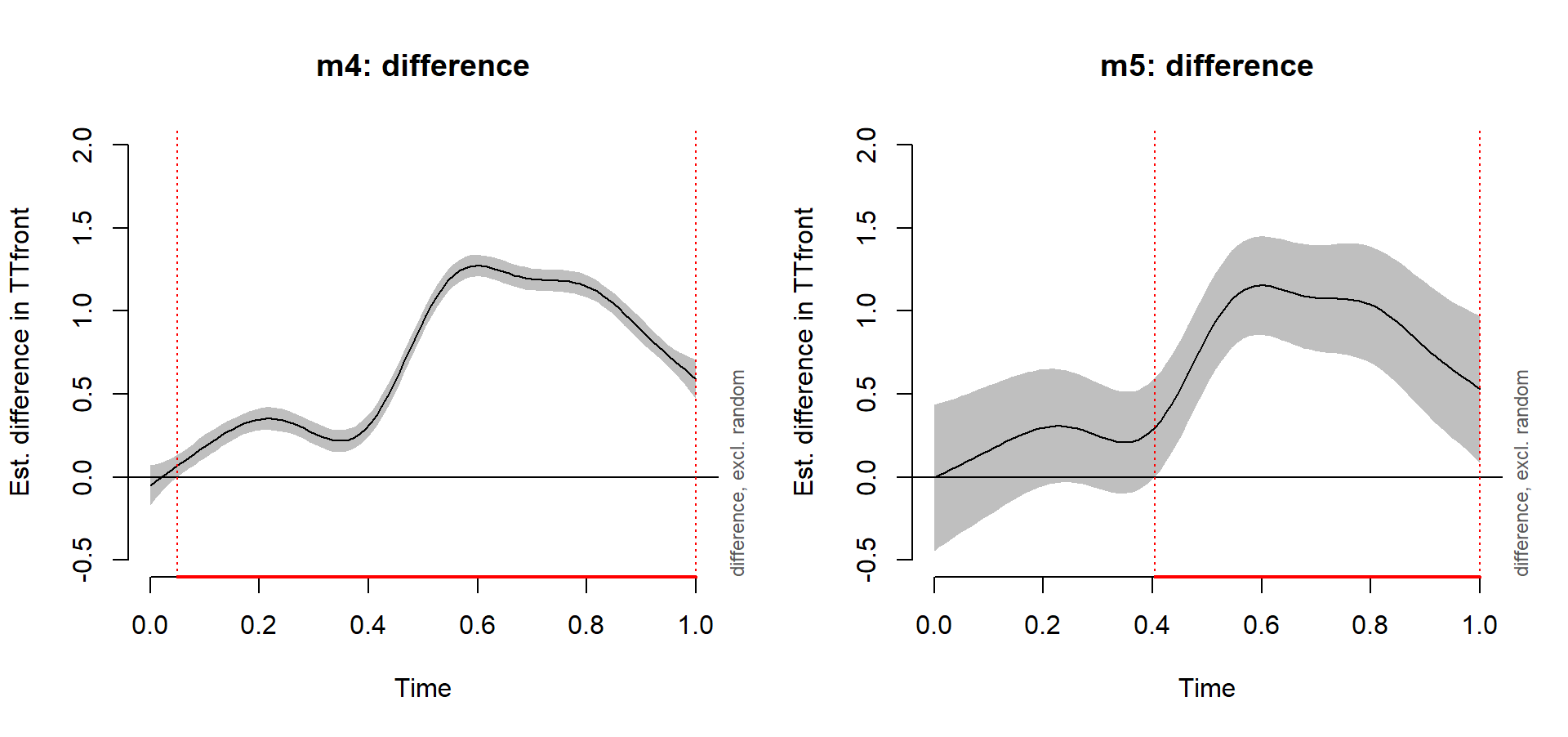
Autocorrelation in the data is a problem!
(residuals should be independent, otherwise the standard errors and p-values are wrong)
m5acf <- acf_resid(m5) # show autocorr.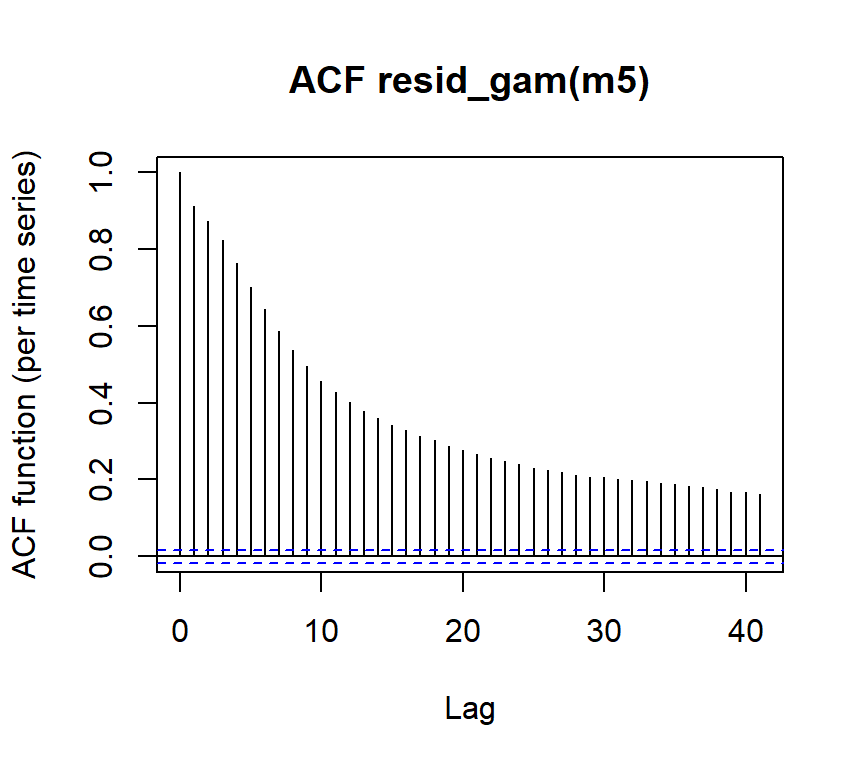
- See also supplementary material
Autocorrelation has been removed
par(mfrow=c(1,2))
acf_resid(m5, main='ACF of m5')
acf_resid(m6, main='ACF of m6')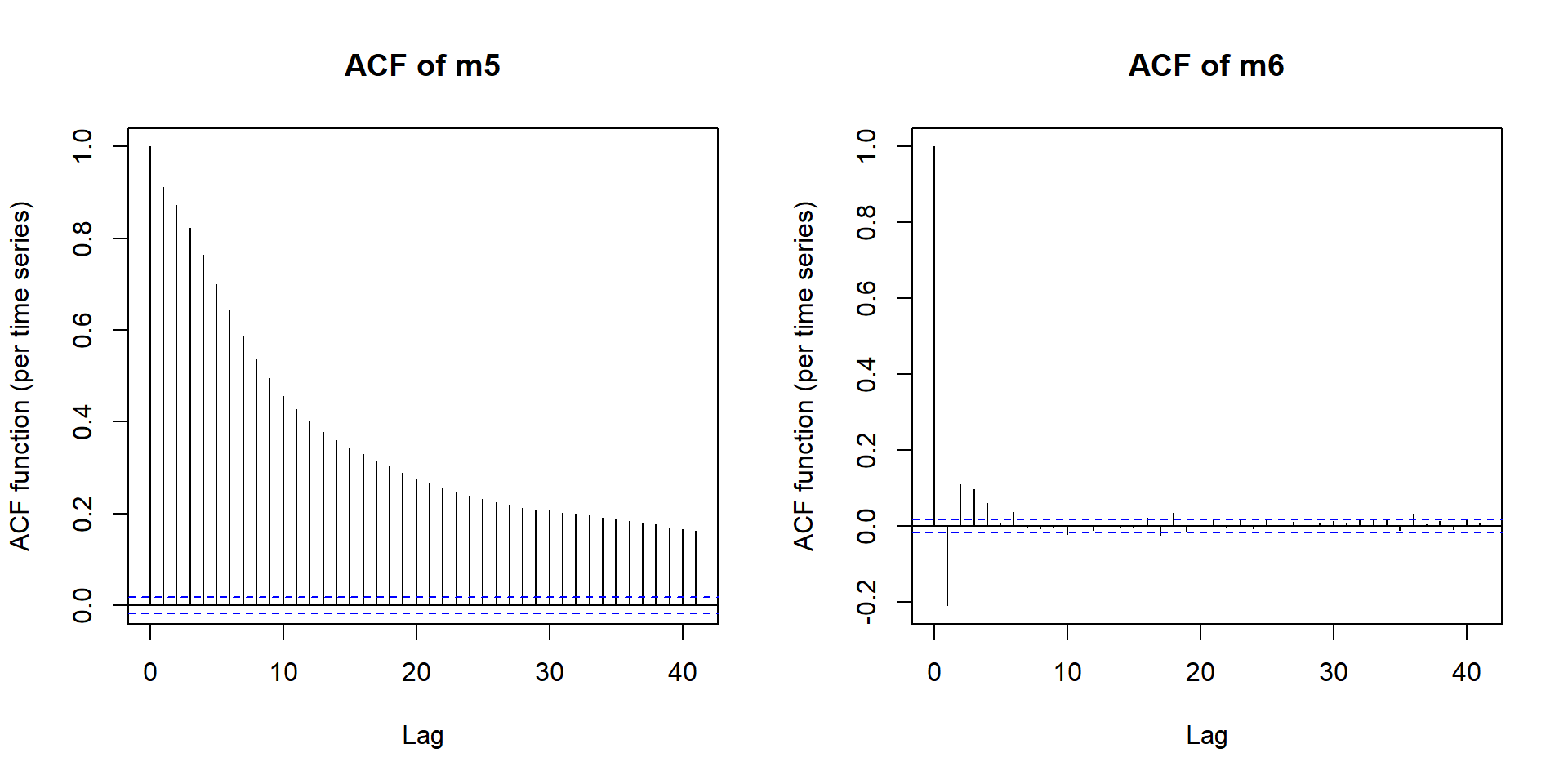
Visualizing the patterns
(note that the difference curves are overly conservative)
plot_smooth(m7, view='Time', rug=F, plot_all='WordGroup', main='m7', ylim=c(-1,2))
plot_diff(m7, view='Time', comp=list(WordGroup=c('tenth.EN','tent.EN')), main='EN difference', ylim=c(-1,2))
plot_diff(m7, view='Time', comp=list(WordGroup=c('tenth.NL','tent.NL')), main='NL difference', ylim=c(-1,2))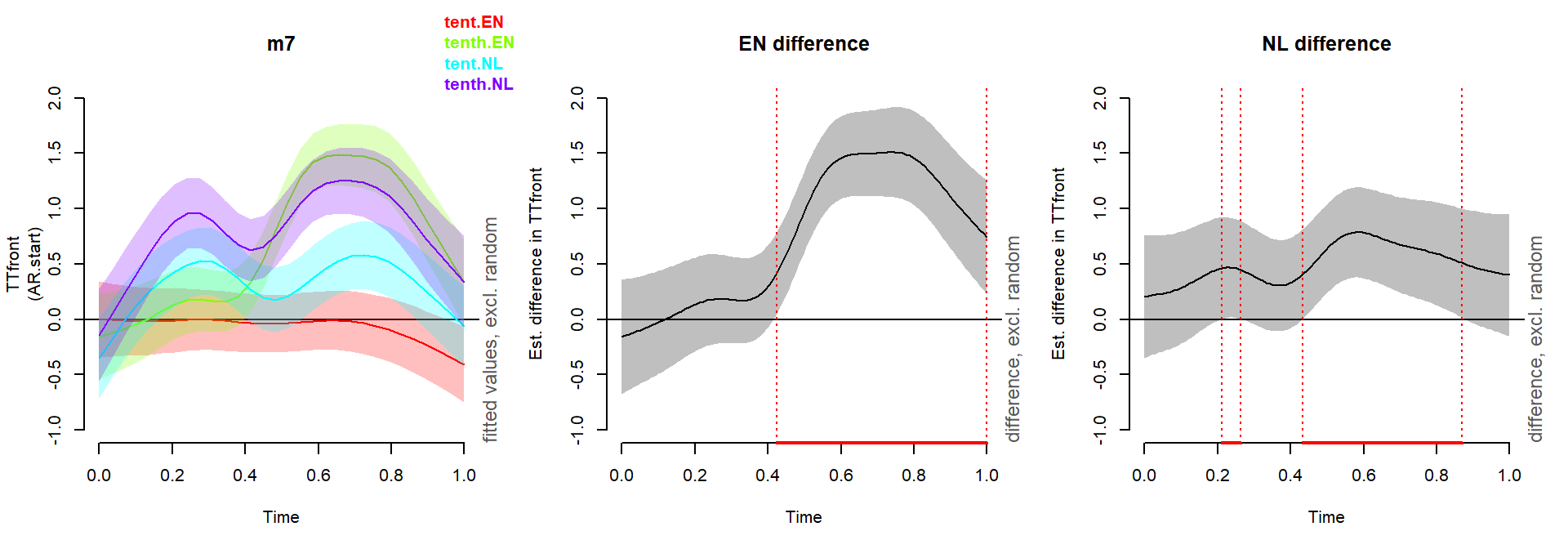
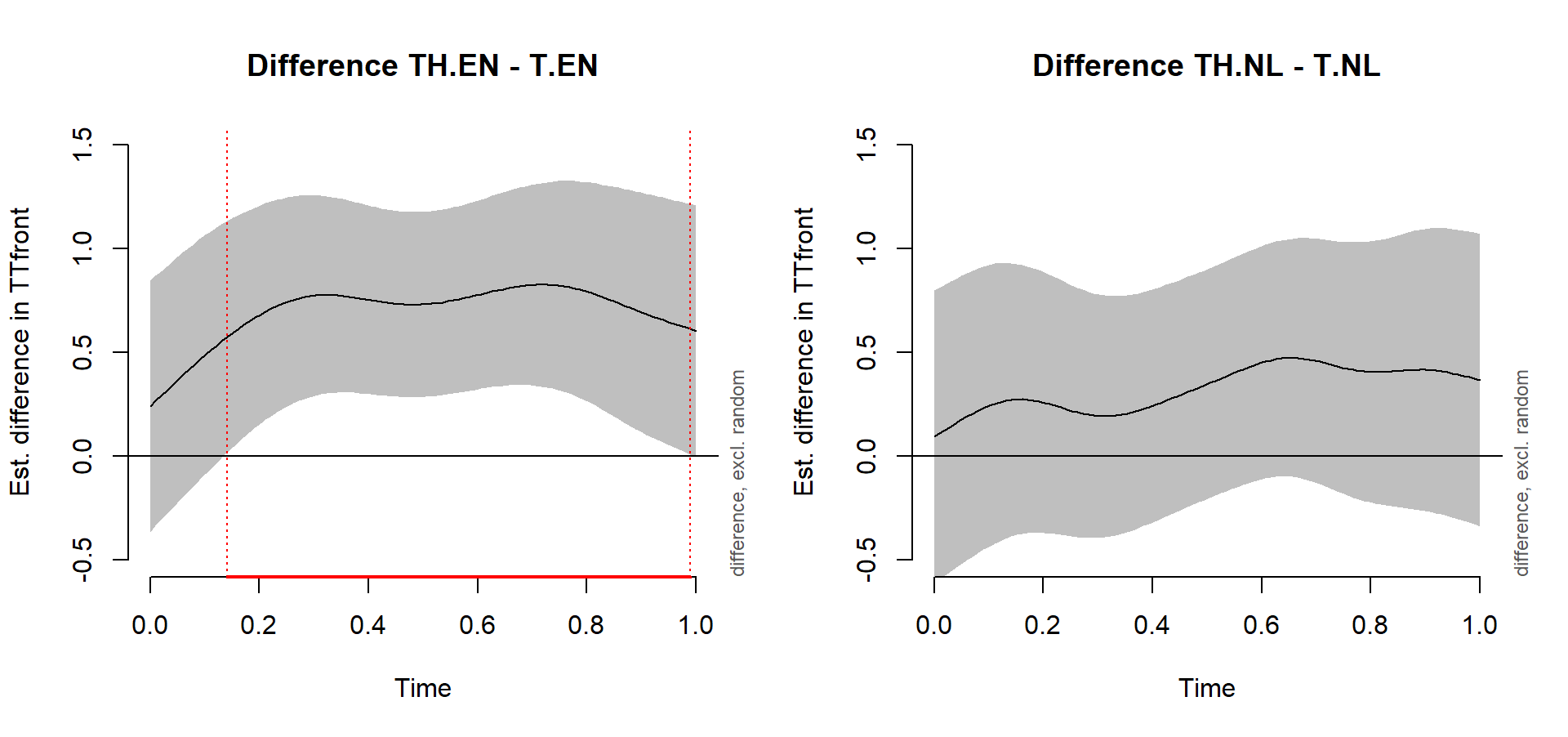
L1-based differences
(note that the CIs of the difference curves are overly conservative)
plot_diff(model, view = 'Time', ylim=c(-0.5, 1.5), comp = list(SoundGroup = c('TH.EN', 'T.EN')))
plot_diff(model, view = 'Time', ylim=c(-0.5, 1.5), comp = list(SoundGroup = c('TH.NL', 'T.NL')))