# Addition (this is a comment: preceded by '#')
5 + 5[1] 10# Multiplication
5 * 3[1] 15# Division
5 / 3[1] 1.6667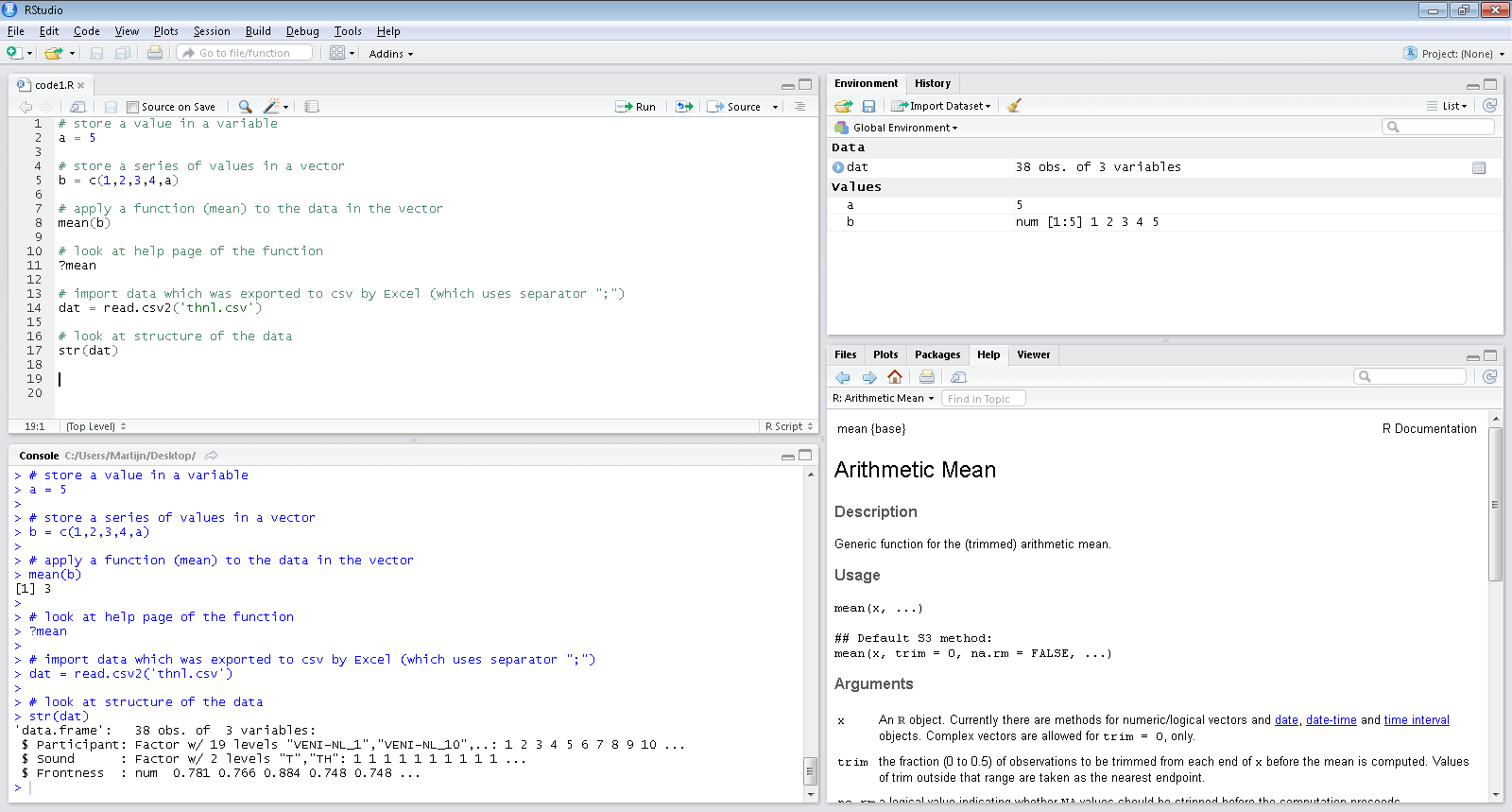

par(mfrow=c(1,2)) # set graphics option: 2 graphs side-by-side
boxplot(dat$Diff, main='Difference') # boxplot of difference values
boxplot(dat[,c("Frontness.T","Frontness.TH")]) # frontness per group
hist(dat$Diff, main='Difference histogram') 
qqnorm(dat$Diff) # plot actual values vs. theoretical quantiles
qqline(dat$Diff) # plot reference line of normal distribution
plot(dat$Frontness.T,dat$Frontness.TH, col='blue')
counts <- table(dat$Sex) # frequency table for sex
barplot(counts, ylim=c(0,15))
counts <- table(dat$Sex,dat$DiffClass)
barplot(counts, col=c("pink","lightblue"), legend = rownames(counts), ylim=c(0,10))