
Logistic mixed-effects regression
Gender in Dutch

- Gender in Dutch: 70% common, 30% neuter
- When a noun is diminutive it is always neuter (the Dutch often use diminutives!)
- Gender is unpredictable from the root noun and hard to learn
Testing lexical competition using eye tracking
- Cohort Model (Marslen-Wilson & Welsh, 1978): competition between words is based on word-initial activation
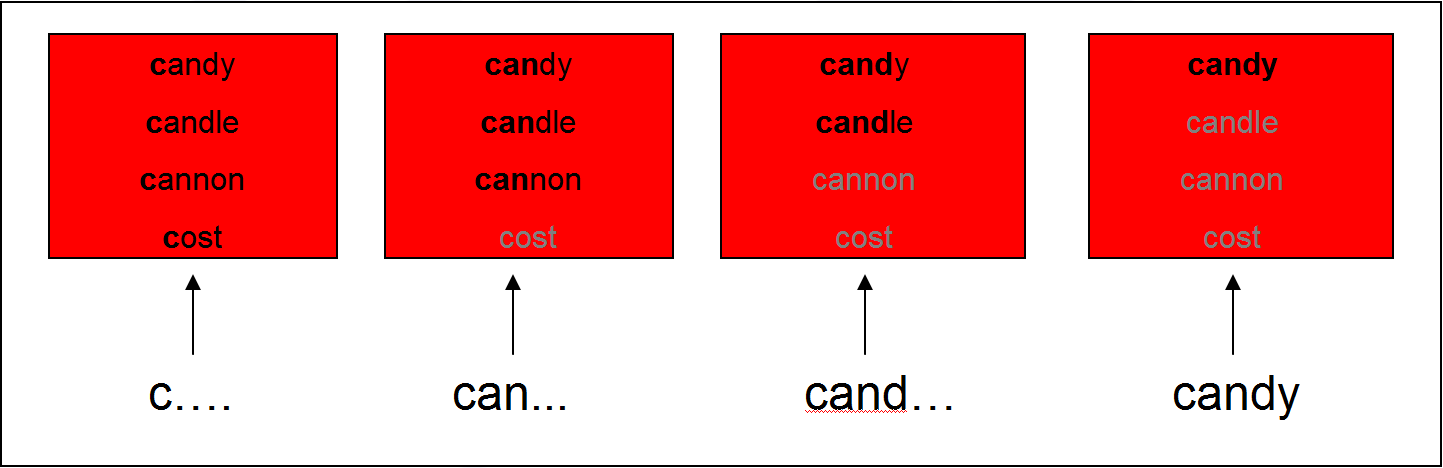
- This can be tested using the visual world paradigm: following eye movements while participants receive auditory input to click on one of several objects on a screen
Support for the Cohort Model
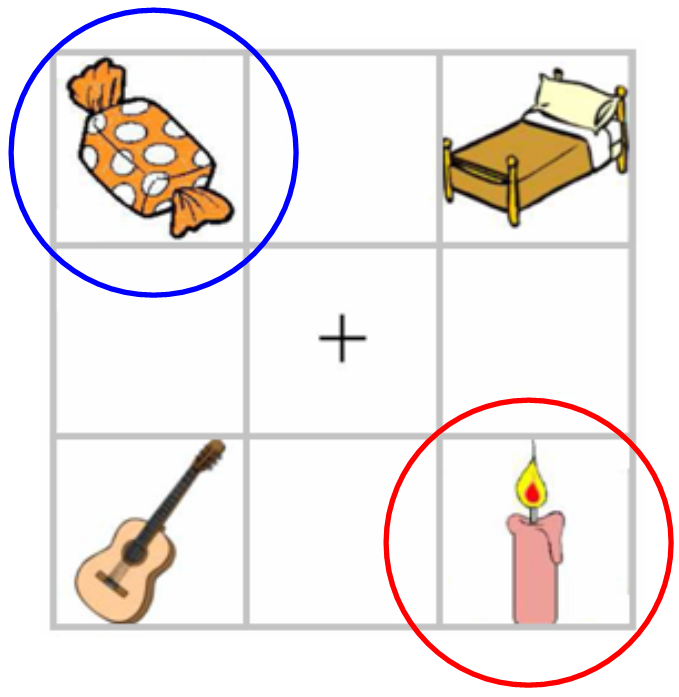
- Subjects hear: “Pick up the candy” (Tanenhaus et al., 1995)
- Fixations towards target (Candy) and competitor (Candle): support for the Cohort Model
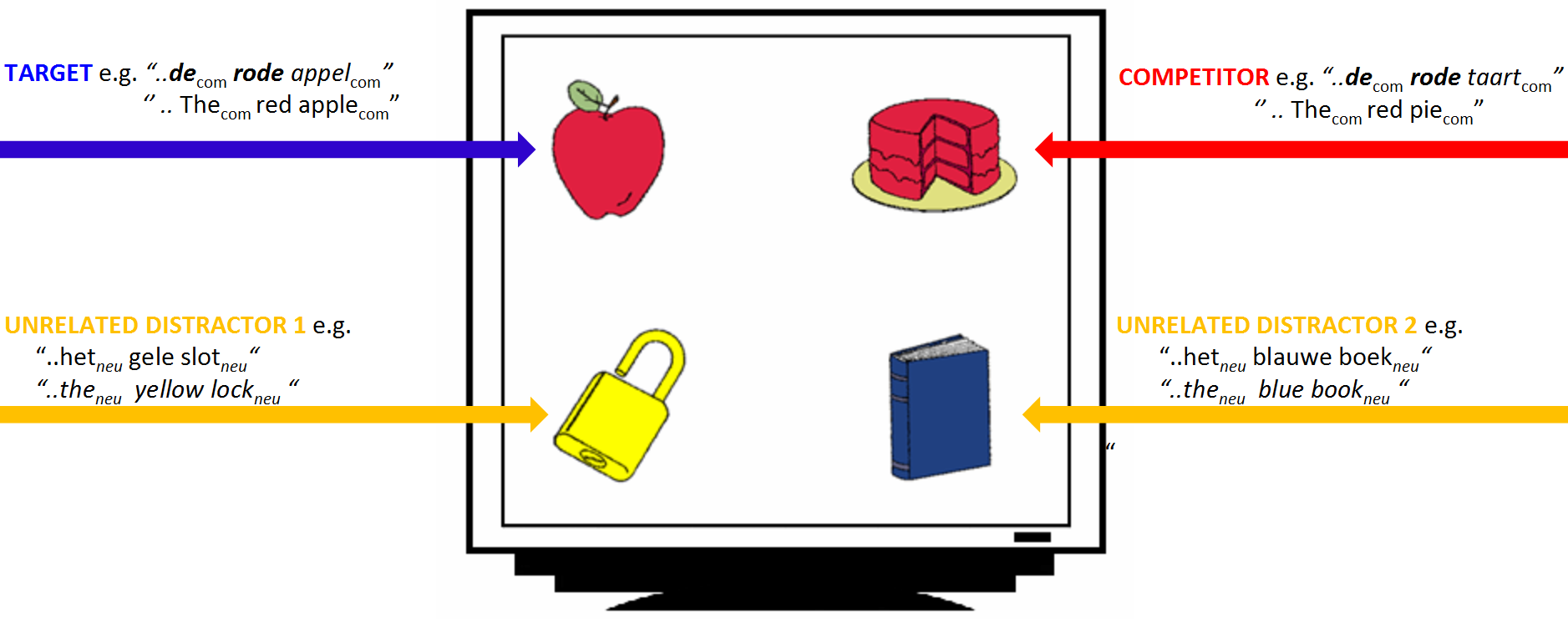
Experimental design
- 28 Dutch participants heard sentences like:
- Klik op de rode appel (‘click on the red apple’)
- Klik op het plaatje met een blauw boek (‘click on the image of a blue book’)
- They were shown 4 nouns varying in color and gender
- Eye movements were tracked with a Tobii eye-tracker (E-Prime extensions)
Experimental design: conditions
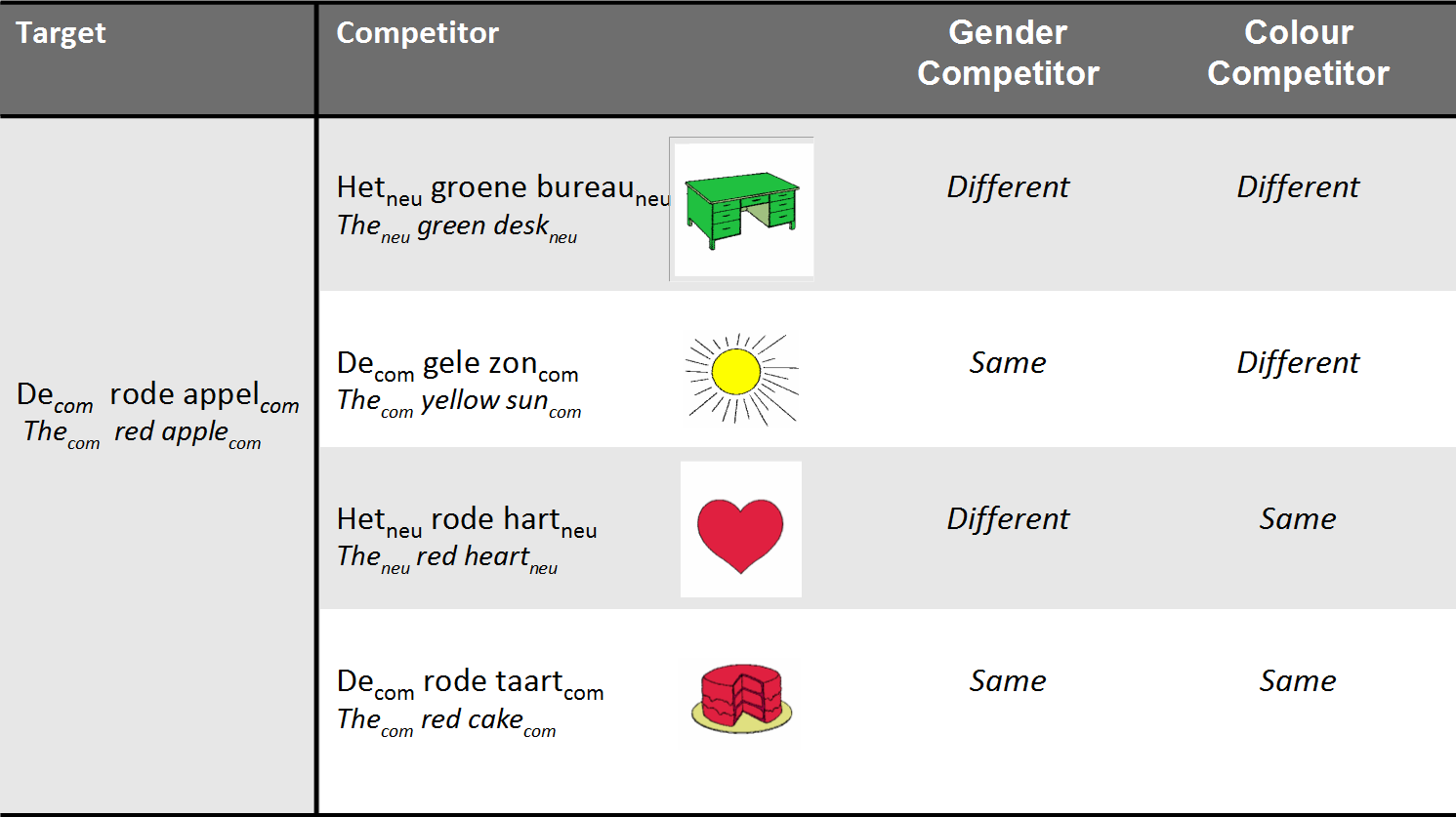
- Subjects were shown 96 different screens
- 48 screens for indefinite sentences (“Klik op het plaatje met een rode appel.”)
- 48 screens for definite sentences (“Klik op de rode appel.”)
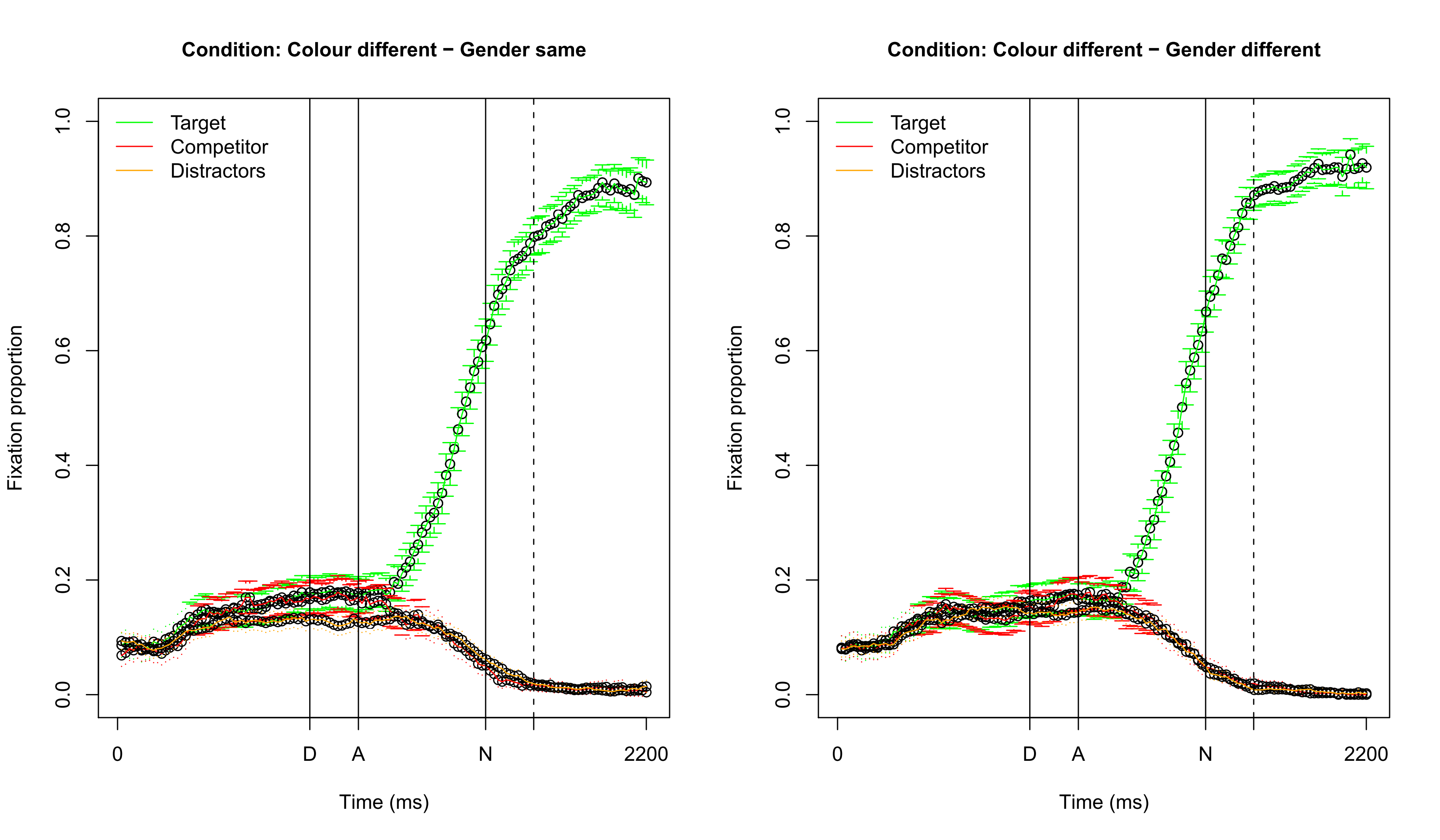
Visualizing fixation proportions: different color
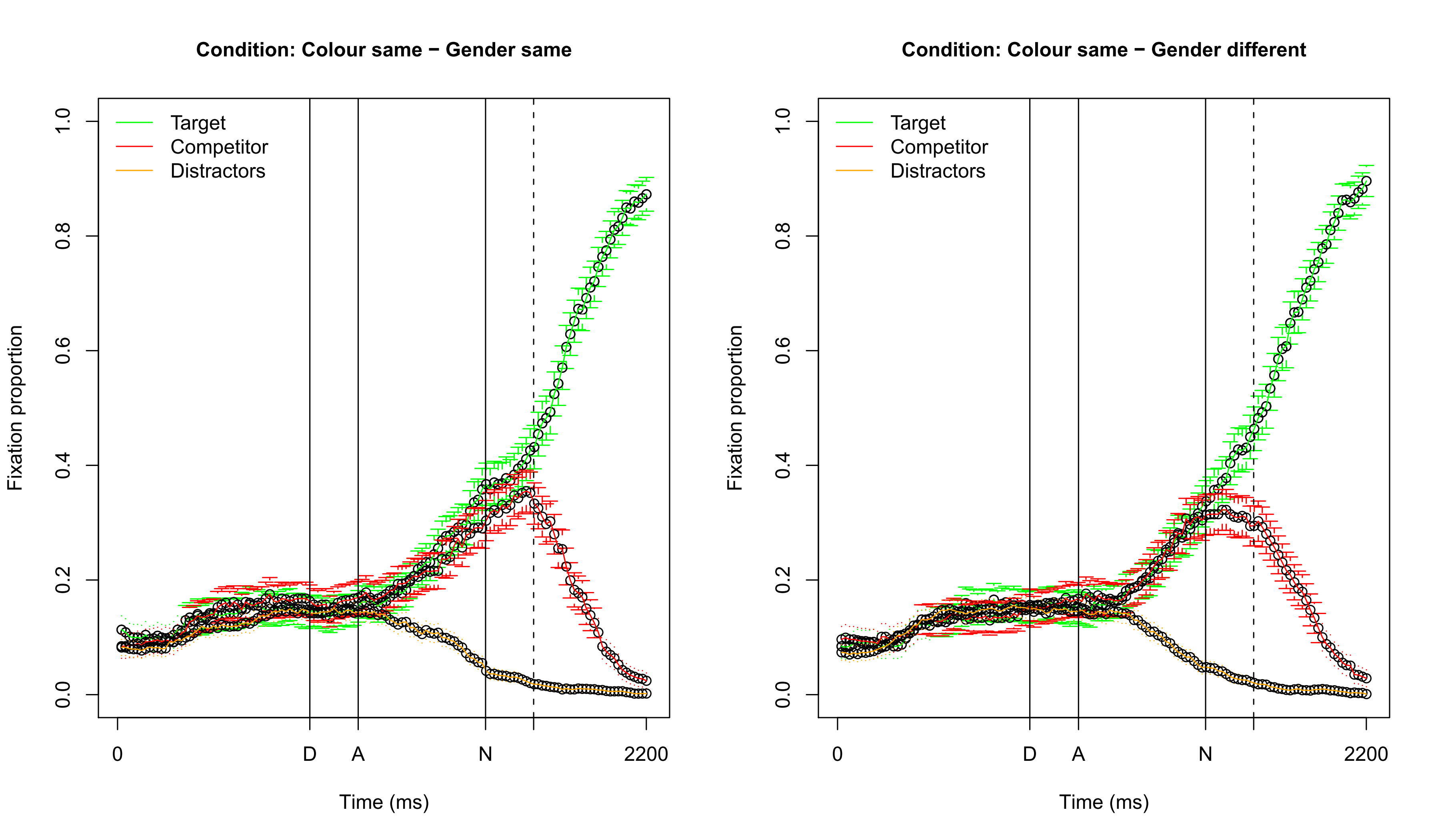
Visualizing fixation proportions: same color
Interpreting logit coefficients I
fixef(model1) # show fixed effects(Intercept)
0.848 plogis( fixef(model1)["(Intercept)"] )(Intercept)
0.7 - On average 70% chance to focus on target

By-item random intercepts

By-subject random intercepts

Visualizing fixation proportions: common (OK)

Visualizing fixation proportions: neuter (not OK)

Visualizing the interaction: interpretation
par(mfrow=c(1,2))
visreg(model6, "SameGender", by="TargetNeuter", overlay=T) # from library(visreg)
visreg(model6, "SameGender", by="TargetNeuter", overlay=T, trans=plogis)
- Common noun pattern as expected, but neuter noun pattern inverted
- Unfortunately, we have no sensible explanation for this finding
Interpreting logit coefficients II
# chance to focus on target when there is a color competitor and
# a gender competitor, while the target is common and not brown
(logit <- fixef(model8)["(Intercept)"] + 1 * fixef(model8)["SameColor"] +
1 * fixef(model8)["SameGender"] + 0 * fixef(model8)["TargetNeuter"] +
0 * fixef(model8)["TargetBrown"] +
1 * 0 * fixef(model8)["SameGender:TargetNeuter"])(Intercept)
0.248 plogis(logit) # intercept-only model was 0.7(Intercept)
0.562 
Distribution of residuals
qqnorm( resid( model8 ) )
qqline( resid( model8 ) )
- Not normal, but also not required for logistic regression