An important aspect of lexical analysis is the treatment of unknown words. The system applies a number of heuristics for unknown words. Currently, these heuristics attempt to deal with numbers and number-like expressions, capitalized words, words with missing diacritics, words with `too many' diacritics, compounds, and proper names.
If such heuristics still fail to provide an analysis, then the system guesses a tag by inspecting the suffix of the word. A list of suffixes is maintained which predict the tag of a given word. If this still does not provide an analysis, then it is assumed that the word is a noun.
In addition to the treatment of unknown words, the robustness of the system is enhanced by the possibility to skip tokens of the input. Currently this possibility is employed only for certain punctuation marks. Even though punctuation is treated both in the lexicon and the grammar, the syntax of punctuation is irregular enough to warrant the possibility to ignore punctuation. For instance, quotation marks may appear almost anywhere in the input. The corpus contains:
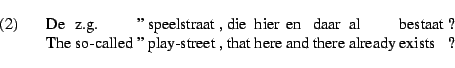
Apparently, the author intended to place speelstraat within quotes, but the second quote is not present. During lexical analysis, tags are optionally extended to include neighbouring words which are classified as `skipable'.