10 juni 2026
Actueel…
- Nederlandstalige nieuwsberichten
- (tijdelijke) website
- git
- aantekeningen
- naar README verplaatsen
- website
- toelichting
- stijgers en dalers
- wat vergelijken
- week t.o.v. vorige week
- week t.o.v. voorgaande vier weken
- vier weken t.o.v. vier weken daarvoor
- alleen algemeen
- telling i.p.v. rangnummer
- lemma i.p.v. word
- rare resultaten: min of veel i.p.v. min of meer
- onderdelen:
- losse woorden geen mwp, en mwu
- alle woorden behalve @pt=let and @neclass
- elke @neclass apart
- score: zeta-functie, of iets anders
- wat vergelijken
- documentatie voor gebruikers corpora
- overzicht data
- problemen vermelden, en hoe die te vinden
- zinnen aan elkaar
- titels zonder aanhalingstekens
We werken met ranglijsten. Dan lijkt het logisch om stijgers te definiëren als woorden die het meest op de ranglijst zijn gestegen. Frequenties zijn niet interessant. De enige knop om aan te draaien, volgens mij, is of je stijgers hoger in de lijst wilt benadrukken, of juist stijgers lager in de lijst. Met a en b de nieuwe en oude (genormaliseerde) positie in de lijst:
- score = an - bn
…voor n = 1, n < 1, of n > 1
Dalers zijn voormalige stijgers: niet interessant.
Zie ook tekst onder tweede set grafieken.
Wat als je toch met frequenties werkt? Een woord kan bovenaan de ranglijst staan, en toch sterk stijgen in frequentie. Dan zou je die toch in de lijst met stijgers moeten opnemen.
Wat zijn de grootste stijgers?
zie ook vergelijking woordfrequenties in Python :
G² = 2 * sum(observed * log(observed / expected))
Wat is sum? Geen functie, want de som van 1 getal is dat getal.
Toegepast op data uit bovenstaande grafiek:
>>> results.sort_values('g2')
word freq_recent freq_reference pct_diff log_ratio chi2 p_chi2 g2 p_g2 p_g2_adjusted
1775 Identitair Verzet 0.000083 0.000106 -21.702772 -0.352963 0.024065 8.767194e-01 0.000000 1.000000e+00 1.000000e+00
3667 Roshon van Eijma 0.000083 0.000106 -21.702772 -0.352963 0.024065 8.767194e-01 0.000000 1.000000e+00 1.000000e+00
1786 Ilke Paddenburg 0.000083 0.000106 -21.702772 -0.352963 0.024065 8.767194e-01 0.000000 1.000000e+00 1.000000e+00
1785 Ilhan Omar 0.000083 0.000106 -21.702772 -0.352963 0.024065 8.767194e-01 0.000000 1.000000e+00 1.000000e+00
1784 Iker Luque 0.000083 0.000106 -21.702772 -0.352963 0.024065 8.767194e-01 0.000000 1.000000e+00 1.000000e+00
... ... ... ... ... ... ... ... ... ... ...
669 Charles 0.000498 0.005141 -90.313745 -3.367915 24.603287 7.043150e-07 33.162393 8.477436e-09 7.945053e-06
99 Alexander 0.002822 0.000106 2562.105744 4.734483 44.159664 3.026540e-11 33.438462 7.355485e-09 7.945053e-06
1062 Donald Trump 0.008798 0.019240 -54.272693 -1.128872 30.296753 3.707460e-08 33.934356 5.700317e-09 7.945053e-06
1989 Jesper de Jong 0.004814 0.000583 725.679856 3.045580 50.945711 9.495627e-13 39.327043 3.584424e-10 8.398306e-07
1737 Hondius 0.001162 0.010230 -88.640817 -3.138068 47.103099 6.734912e-12 64.366325 1.033088e-15 4.841052e-12
>>> results.sort_values('chi2')
word freq_recent freq_reference pct_diff log_ratio chi2 p_chi2 g2 p_g2 p_g2_adjusted
1400 Freek 0.000996 0.001007 -1.098239 -0.015932 0.000557 9.811767e-01 0.000000 1.000000e+00 1.000000e+00
2624 Magyar 0.000996 0.001007 -1.098239 -0.015932 0.000557 9.811767e-01 0.000000 1.000000e+00 1.000000e+00
1393 Fred Rutten 0.000830 0.000848 -2.128465 -0.031039 0.001765 9.664904e-01 0.000000 1.000000e+00 1.000000e+00
3435 Péter Magyar 0.000830 0.000848 -2.128465 -0.031039 0.001765 9.664904e-01 0.000000 1.000000e+00 1.000000e+00
1310 Felipe 0.000830 0.000848 -2.128465 -0.031039 0.001765 9.664904e-01 0.000000 1.000000e+00 1.000000e+00
... ... ... ... ... ... ... ... ... ... ...
3969 Stan Wawrinka 0.002324 0.000106 2092.322377 4.454375 34.967944 3.351783e-09 25.842886 3.703673e-07 2.479344e-04
2191 Jurriën Timber 0.004316 0.000689 526.377822 2.647031 38.396523 5.773517e-10 29.581158 5.362367e-08 4.188008e-05
99 Alexander 0.002822 0.000106 2562.105744 4.734483 44.159664 3.026540e-11 33.438462 7.355485e-09 7.945053e-06
1737 Hondius 0.001162 0.010230 -88.640817 -3.138068 47.103099 6.734912e-12 64.366325 1.033088e-15 4.841052e-12
1989 Jesper de Jong 0.004814 0.000583 725.679856 3.045580 50.945711 9.495627e-13 39.327043 3.584424e-10 8.398306e-07
>>> results.sort_values('pct_diff')
word freq_recent freq_reference pct_diff log_ratio chi2 p_chi2 g2 p_g2 p_g2_adjusted
4584 Xi Jinping 0.000083 0.002809 -97.045388 -5.080870 15.822528 6.956926e-05 22.023559 0.000003 0.001052
112 Alexia 0.000083 0.002014 -95.879093 -4.600878 11.026056 8.984008e-04 14.359901 0.000151 0.032160
4583 Xi 0.000083 0.002014 -95.879093 -4.600878 11.026056 8.984008e-04 14.359901 0.000151 0.032160
4532 William 0.000083 0.001855 -95.525873 -4.482233 10.068464 1.508287e-03 12.859264 0.000336 0.056201
115 Ali B 0.000083 0.001749 -95.254713 -4.397344 9.430496 2.134065e-03 11.866999 0.000571 0.089249
... ... ... ... ... ... ... ... ... ... ...
2163 Juan Manuel Cerúndolo 0.000996 0.000027 3658.266932 5.231943 16.439344 5.023174e-05 10.582458 0.001142 0.133745
2581 Luciano Valente 0.000996 0.000027 3658.266932 5.231943 16.439344 5.023174e-05 10.582458 0.001142 0.133745
1162 Elisa Balsamo 0.001162 0.000027 4284.644754 5.454335 19.544875 9.826402e-06 13.112440 0.000293 0.050911
2358 Koopmans 0.001328 0.000027 4911.022576 5.646980 22.657235 1.936298e-06 15.684129 0.000075 0.021922
1305 Federico Cinà 0.001660 0.000027 6163.778220 5.968908 28.894926 7.641282e-08 20.916433 0.000005 0.001729
Wat vergelijken?
- huidige week t.o.v. vier voorgaande weken
- huidige week t.o.v. voorgaande week
- laatste vier weken t.o.v. de vier weken daarvoor (lijkt minst interessant, maar sluit wel aan bij “woord van de maand”)
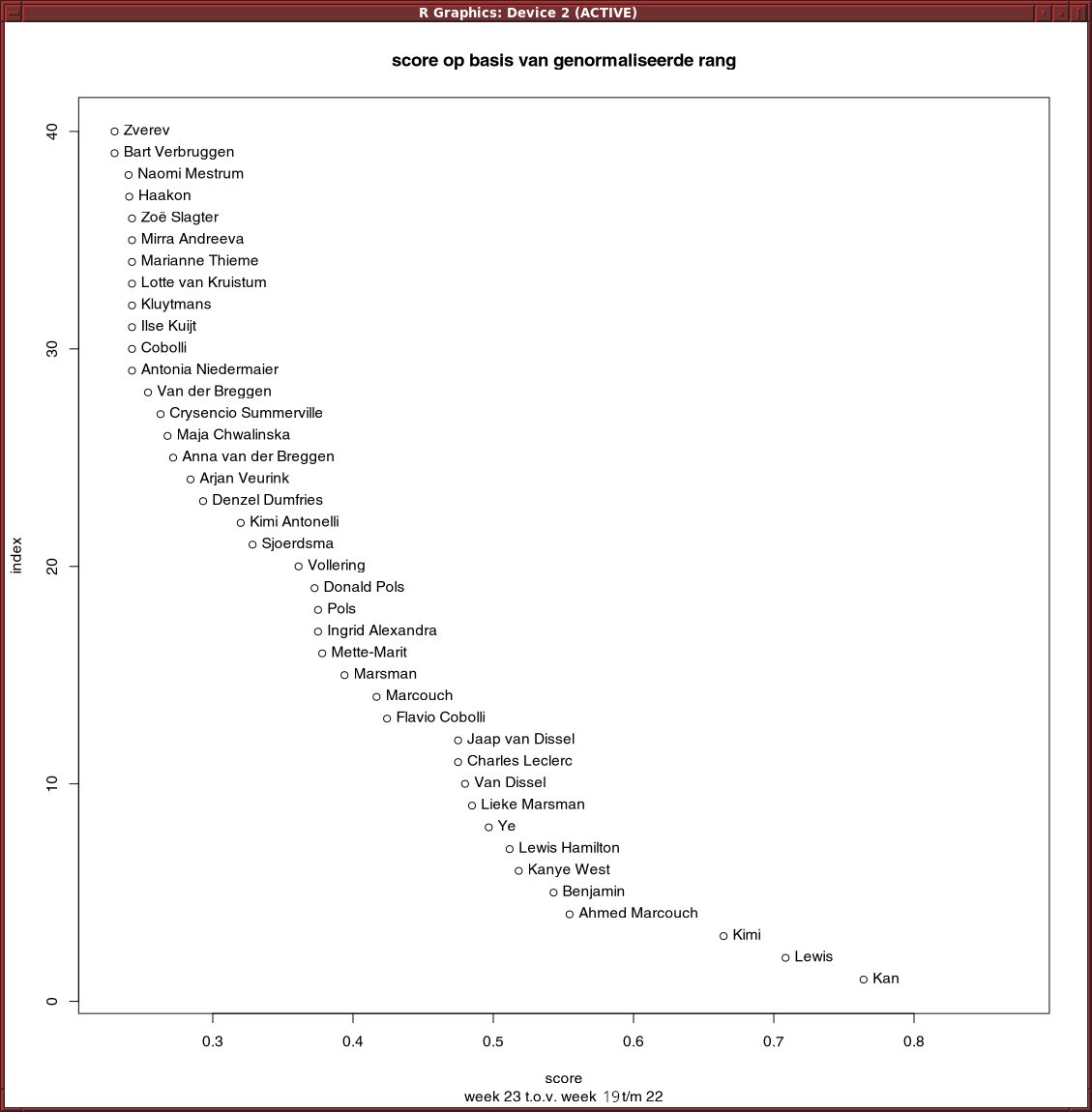
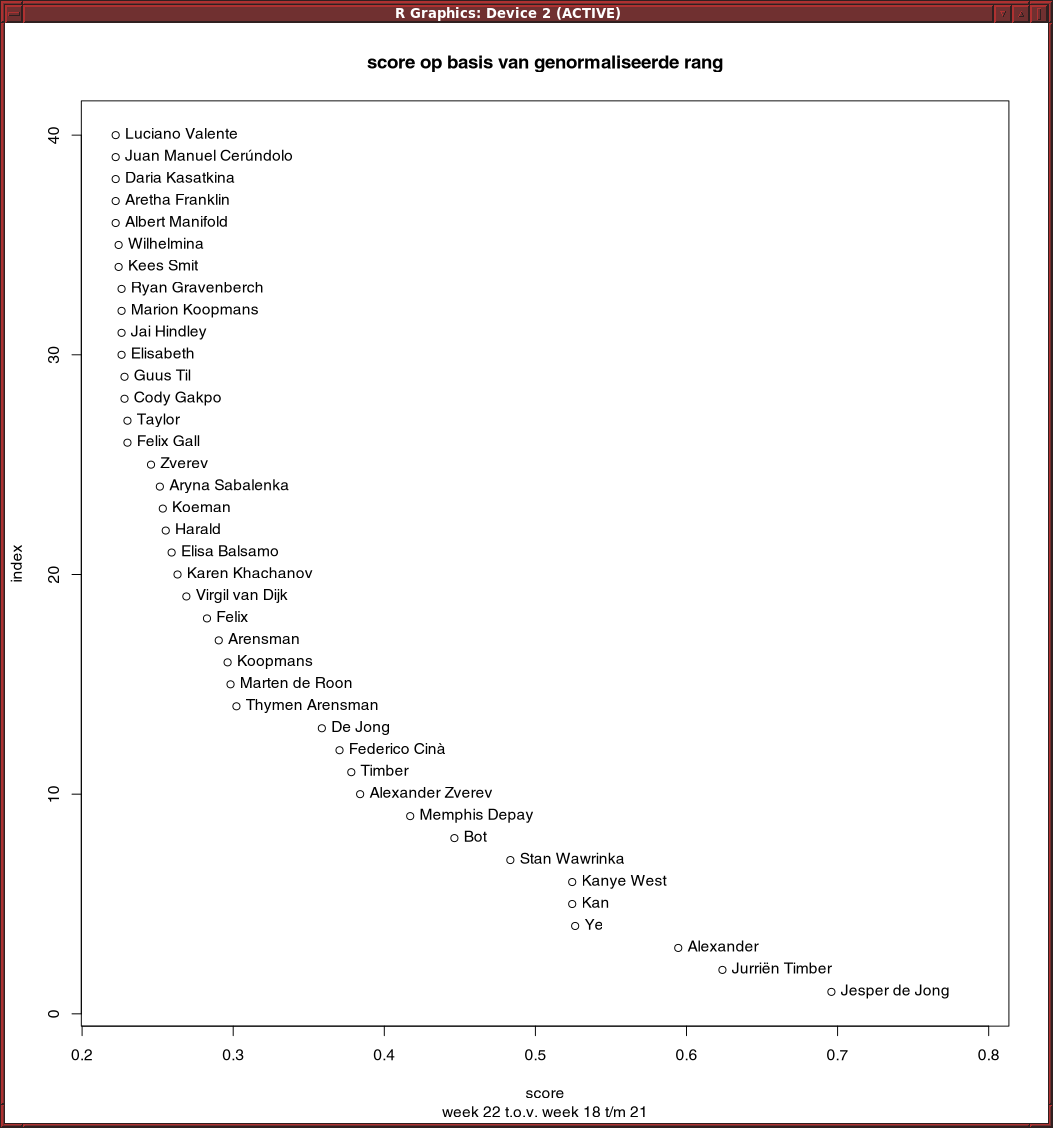
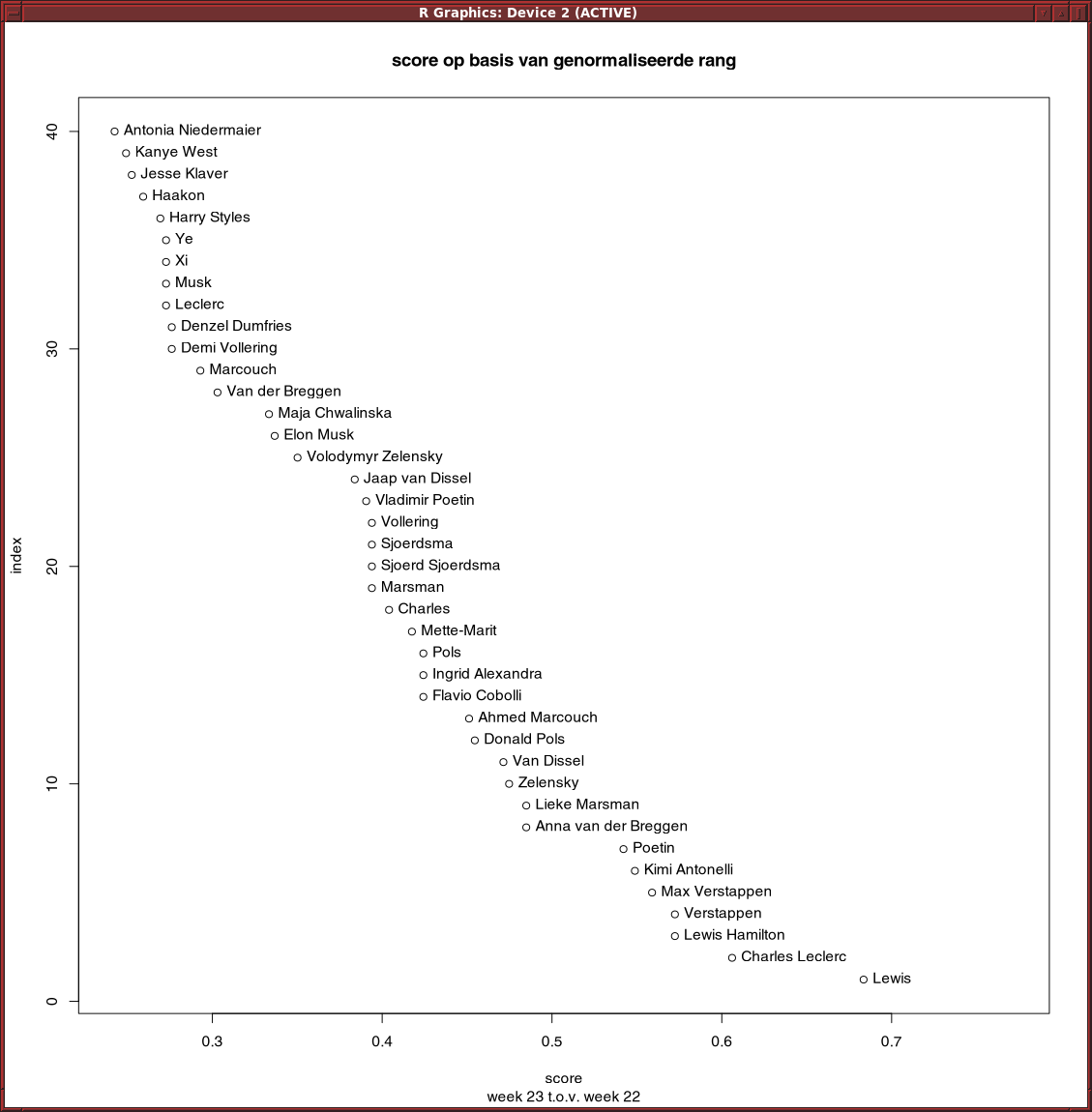
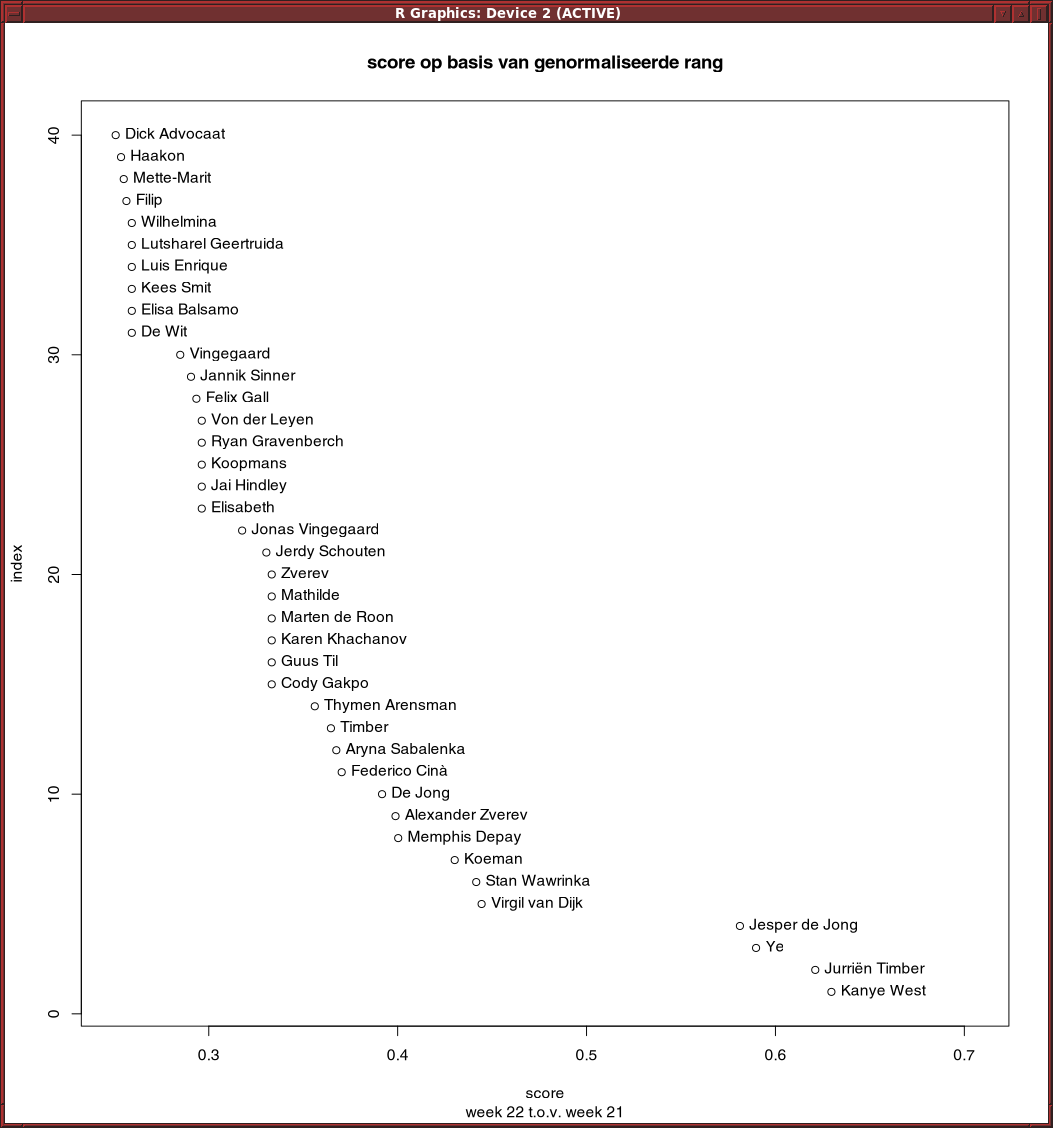
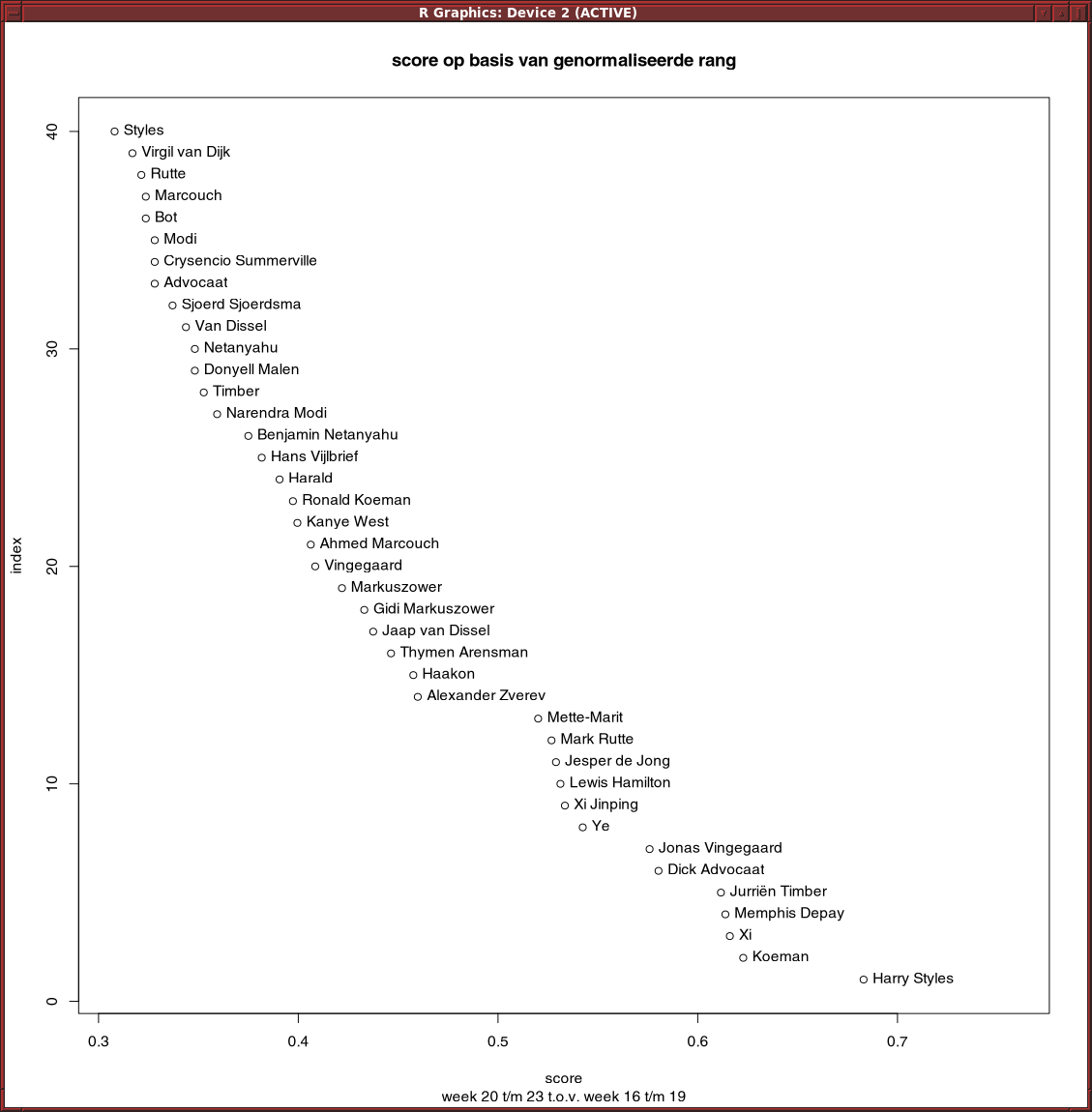
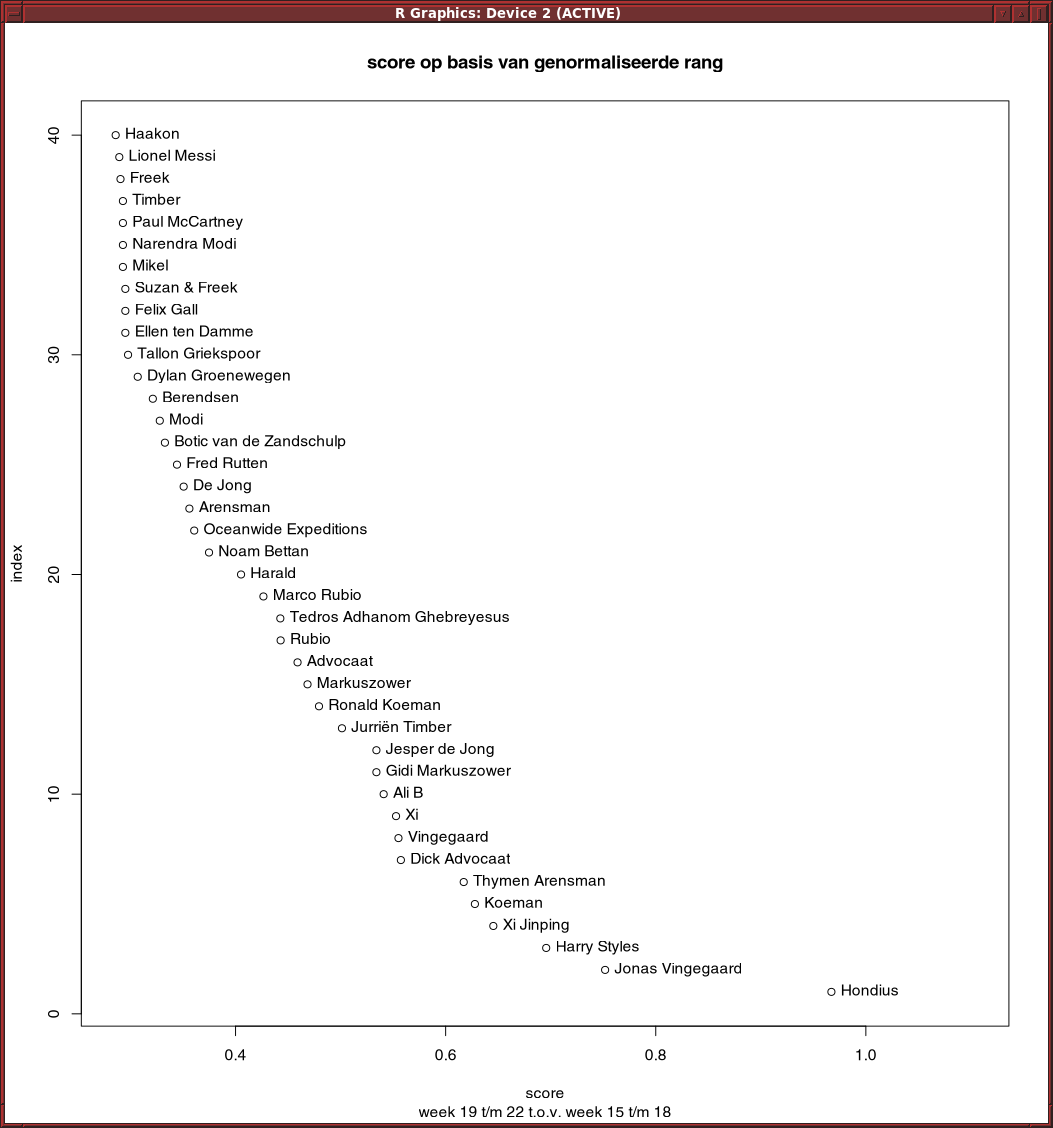
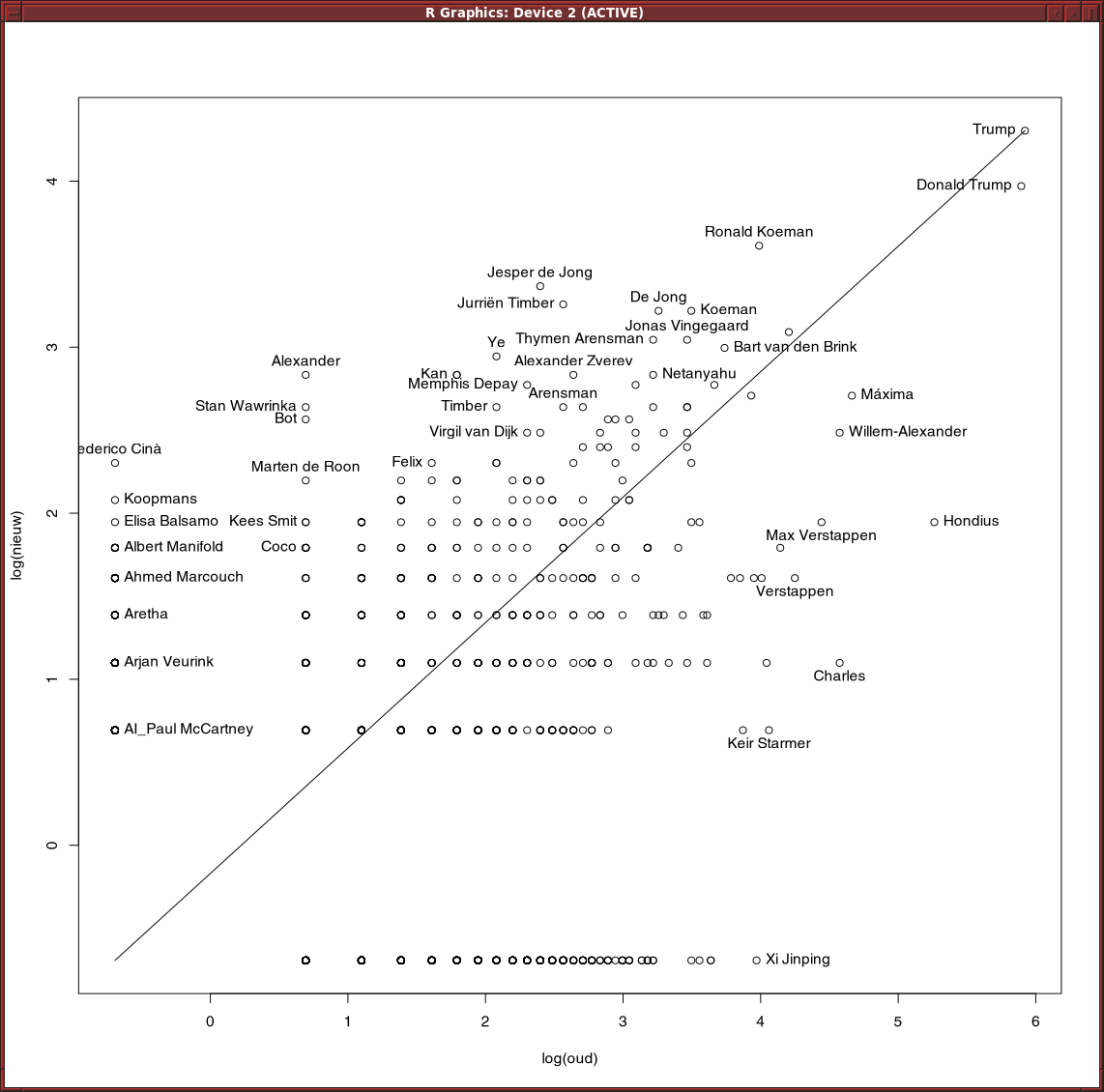
Residuals van lineair model op basis van rang werkt slecht. Trump scoort hoog, terwijl hij onveranderd op 1 staat.
Met een quadratisch model komt Trump op 25 in de lijst van stijgers, nog steeds te veel.
Een model op basis van telling i.p.v. rang geeft een vergelijkbaar resultaat.
En als je kijkt naar woorden, dan zijn de residuals hoog voor woorden die heel veel voorkomen, zoals de en een.
Hier staan nog wat grafieken
Modeleren werkt niet. Een grafiek van frequenties is te extreem, bijna verticaal in het begin, en dan een heel lange staart die vrijwel horizontaal is. Met een log van frequenties kom je er niet.
Gewoon iets op basis van verandering in rang werk wel aardig:

Woorden:
//node[(@pt and not(@pt="let" or @rel="mwp" or @neclass)) or (@cat="mwu" and not(.//node[@neclass]))]
Namen:
//node[(@neclass="LOC" and not(@rel="mwp")) or (@cat="mwu" and .//node[@neclass="LOC" ])] //node[(@neclass="PER" and not(@rel="mwp")) or (@cat="mwu" and .//node[@neclass="PER" ])] //node[(@neclass="ORG" and not(@rel="mwp")) or (@cat="mwu" and .//node[@neclass="ORG" ])] //node[(@neclass="MISC" and not(@rel="mwp")) or (@cat="mwu" and .//node[@neclass="MISC"])]
Later…
- colossus upgrade naar Ubuntu 24.04
- migratie van haytabo naar colossus