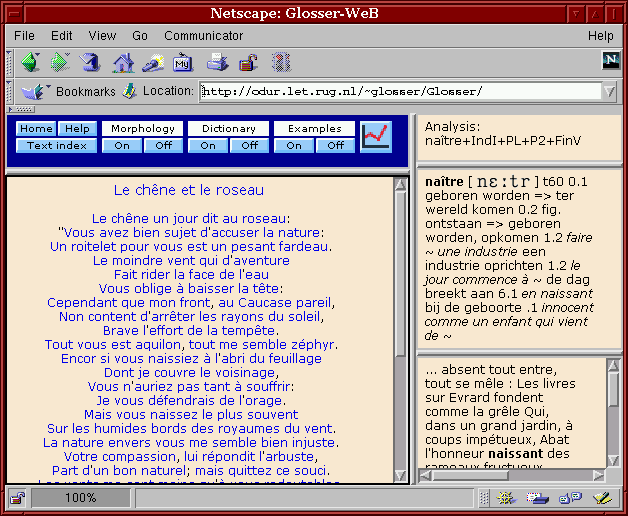
We report on a feasibility study making a state-of-the-art application in Computer-Aided Language Learning (CALL) available on the Web. The program does not merely cache data, but exploits extensive Natural Language Processing (NLP) modules. The goal of the processing is to facilitate the reading of French text for Dutch students, and it invokes morphological analysis, part-of-speech disambiguation, dictionary and corpora lookup in response to Web client requests. On a local platform, the program has been functional for thirty-four months (as of 5/2000). In Figure 1 the Glosser-Web prototype is shown as it appears on the Web.
The use of the computer in language teaching starts in the 60's and can roughly be divided into three stages: behavioristic CALL, communicative CALL, and integrative CALL. Each stage corresponds to a certain level of technology as well as a certain pedagogical approach. For an in-depth, historical overview see Levy (1997), Warschauer & Healy (1998).
In integrative CALL (Warschauer 1996), the students learn to use a variety of technological tools in language learning and use. Instead of being passive recipients of knowledge, students are challenged to construct their own knowledge with guidance from a teacher.
The Web is an optimal tool for a more learner-centered, integrative approach such as this. The Web offers the possibility of making learning materials and tools available electronically and putting them into an interactive environment. There are several advantages using the Web in a language learning environment as for example Godwin-Jones (1998a) and Polyson e.a. (1996) have pointed out:
Figure 1: The Glosser-Web prototype as it appears to the World-Wide Web user. Note that the Xerox morphological analyzer successfully identified the stem of the irregular form `naissiez' (line 11 in the poem) enabling the dictionary look-up. The top right window identifies the grammatical significance of the morphology, the middle window is the dictionary, and the bottom shows examples from another 1 million words collected from the Internet.
Glosser-RuG, which applies natural language processing techniques to CALL, is designed to help people who have an intermediate grasp of a foreign language to get more background information on texts they read. Someone reading an online text in a foreign language might encounter unknown words or an unfamiliar use of a known word. Through Glosser-RuG she or he can get online information from a bilingual dictionary, as well as information about the word's morphological form, its syntactic category, and other examples of how the word is used (from corpora). A mouse click is sufficient to make these resources available. See for example Nerbonne & Dokter (1999), Nerbonne e.a. (1998), Nerbonne & Smit (1996). For each word in the text the user can select what specific information is needed and start a lookup for this particular word. A user study (Schurcks-Grozeva e.a. 1998) has shown that applications in the line of Glosser-RuG can be used in practical language education. The application clearly improves the ease with which language students approach a text in a foreign language.
Loosely based on Glosser-RuG we have built a Web-prototype, which is meant to be a first step towards distributed CALL. We would like to show that we can deliver the same services on the Web with comparable advantages.
Glosser-RuG is in principle a structured integration of several previously developed linguistic tools and existing resources. The major informational resources that are incorporated are: an online dictionary provided by Van Dale Lexicografie (Van Dale Lexicografie 1993), morphological analysis software provided by Rank Xerox (Bauer & Zaenen 1995), and examples of the use of words in especially collected text corpora. The program relies heavily on the morphological analysis software, which provides the link between the text that is being processed, and the other informational sources. Each word for which information is sought is analyzed within its linguistic context (the sentence it occurs in) and disambiguated with respect to its base form, its syntactic category (also known as `part-of-speech', or `POS') and the properties of the word (and inflections) that determine its appearance. The analysis thus provides the link between the possibly inflected form of the word as it appears in the text and the base form, or `citation form', listed in dictionary entries. This `lemmatization' is also exploited for lookup of examples. All various forms of a word occurring in the text are variations of a single lemma, and can thus be indexed by this single form. This effectively guarantees that a wide variety of inflections and lexical environments will be shown as examples of a specific word, providing a rich contexts for vocabulary improvement and word comprehension. Lemmatization thus plays a dual role: it is informational in that it displays properties of words, and it is functional for processing, by providing the link between text on the one hand, and dictionary and examples on the other. Figure 2 provides a complete overview of the flow of information within Glosser-RuG.
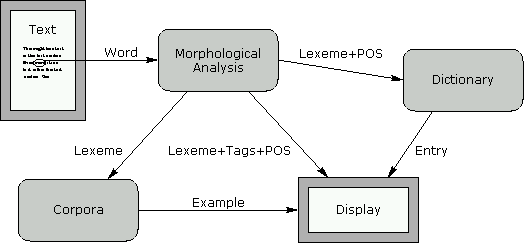
Figure 2: The flow of information for a single lookup within Glosser-RuG, given that all sources are activated.
The dual role of lemmatization will be significant in the architecture of the Web version. The goal in re-developing Glosser-RuG into a version on the Web was to maintain as much of the functionality as possible. However, for property rights reasons, our Web-prototype could only be developed to a demonstrational level.
Another option to construct interactive Webpages is JavaScript. Netscape and Microsoft browsers support this means of creating interactive Web pages locally, without accessing a server. JavaScript can provide feedback in a greater variety of ways than CGI, and it's faster because all the interaction is local. On the other hand, JavaScript does not allow for the submission of student work. It is also not secure -- the source code can be easily viewed. Probably the best configuration is a combination of JavaScript and CGI. JavaScript can be used to do preliminary (local) processing of student input and then a CGI can save or record the student's work on the Web server.
A major obstacle to implementation of Glosser-RuG was the restriction that the result of processing cannot be stored client-side. This posed problems for programs (CGI scripts and JavaScripts) that need to exploit results of earlier scripts. A problem of using multiple CGI scripts in a single application is posed by the lack of communication between the scripts on the one hand, and JavaScript (JS) code on the other. Once a request is sent, control over the request is no longer possible for JS.
A second problem ensued from a design choice to display results in different frames (windows): every request is restricted to communicating its response to exactly one frame. For our program this implied that different knowledge sources had to be implemented by separate CGI scripts, since information for each source is displayed in a separate window. Remember that the result of morphological analysis is both directly informational and also indirectly functional in further processing. It should be displayable, but also stored in case it is needed for later processing. The user is able to specify whether morphological information should be displayed, but in either case (whether the morphology is displayed or not), the analysis initiated by the CGI script must send output to a predefined frame. The frame is obligatory. The problem is then to provide a displayable HTML document and a result for further processing by a single CGI script and then be able not to display the document if the user doesn't want the analysis to be displayed. A solution to the first problem is provided by cookies, i.e. small strings which retain state information on the client-side. The use of cookies is the only way for Web applications to store information apart from Java/JS runtime variables on the user side of the connection. The cookies are stored in memory during a single browser session, and written to a special file after the session has been ended.
One CGI script writes a cookie on the user side, specifying a URL of another CGI script that will receive the cookie when addressed. This mechanism provides communication between the different parts of the application. The lexeme found by morphological analysis is written as a cookie, which is added to every call to the URL specifying the scripts for dictionary and examples lookup. The latter two scripts simply retrieve the cookie from the request header, since the host server stores the cookie. The second problem (where to leave the returned document when no frame is open) is inelegantly solved by providing a 'hidden' frame in the main window, which is not user-controlled and therefore present during the whole session. This frame is so small, that it can not visibly display any information, therefore, the document is hidden from the user. These solutions allow the information flow sketched in Figure 3.
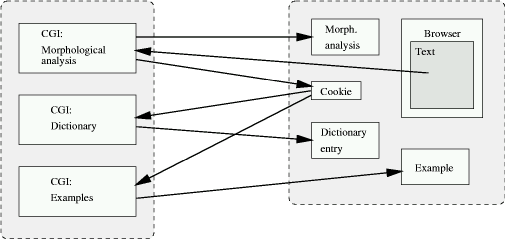
Figure 3: The flow of information between the major components of the Glosser-Web prototype.
This paper has explained how the specific implementation of Glosser-RuG was realized: there are (admittedly clumsy) means of delivering the level of information processing required within standard browsers. Java simplifies some of the programming obstacles we encountered, and will be used for delivery in more advanced environments. Furthermore, Glosser_RuG should be integrated in a versatile electronic language learning environment in order to exploit its full potential.