Bij het doen van dialectonderzoek gaat de meeste tijd zitten in het verzamelen
en digitaliseren van data. De data dient in een formaat opgeslagen te worden
waar
RuG/L04 mee overweg kan. Als daarmee bij de
digitalisatie geen rekening is gehouden moet je eerst zelf voor de
omzetting zorgen.
De bestanden waarmee de software werkt, zowel de data zelf als de hulpbestanden,
zijn in een formaat dat voor de mens leesbaar is. Dat wil zeggen, je kunt de
bestanden bewerken met een editor voor platte tekst,
maar bovenal kun je de bestanden bewerken met eenvoudige hulpmiddelen zoals
scripts (bijvoorbeeld: Perl). Heb je de data opgeslagen in een binair formaat,
bijvoorbeeld in een database, dan moet je het bijbehorende programma
gebruiken om de data te exporteren. Je moet met dat programma de data dan
uitschrijven, of direct in het formaat dat voor RuG/L04
nodig is, of in een andere vorm als platte tekst, waarna je
bijvoorbeeld een script gebruikt om de data in de juiste vorm te
krijgen.
Behalve de data zelf heb je een paar andere bestanden nodig.
Je hebt een bestand nodig met daarin een lijst van genummerde plaatsnamen. Zie
label file voor het formaat van dat bestand.
(Zie als voorbeeld het bestand PA.lbl zoals dat gebruikt werd in de
voorbeelden van de vorige twee hoofdstukken van deze tutorial.)
Wil je van een meting de local incoherence bepalen
(zie deel 6), dan heb je een bestand nodig met
daarin de coördinaten van de plaatsen. Zie
coordinate file voor het formaat van dat
bestand.
Dit bestand heb je ook nodig als je kaarten wilt tekenen. (Voorbeeld: het
bestand PA.coo uit de vorige hoofdstukken.)
De overige bestanden, die je alleen nodig hebt om kaarten te tekenen, worden in
deel 5 van de tutorial besproken.
Hieronder wordt ingegaan op het formaat van de data zelf.
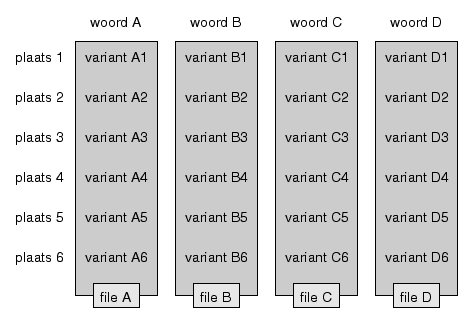
De dialectgegevens bestaan uit varianten van een reeks woorden (of
woordgroepen) zoals die in een reeks plaatsen zijn opgetekend. Deze data is
verdeeld over een aantal bestanden. Elk bestand dient alle varianten van één
bepaald woord uit alle plaatsen te bevatten. Dat is weergegeven in onderstaand diagram:
Uitleg over het formaat voor de losse databestanden vind je
hier.
Merk op dat hierboven netjes voor elke plaats en elk woord precies één
variant aanwezig is. Dit hoeft niet. Je kunt ook voor een bepaald woord en een
bepaalde plaats meerdere varianten hebben, of zelfs helemaal geen data.
Stel nu dat je de data al netjes onderverdeeld hebt in bestanden, maar niet per
bestand alle varianten van één woord in alle plaatsen,
maar per bestand alle varianten van alle woorden in één plaats,
zoals weergegeven in onderstaand diagram:
In dit geval moet je de data herordenen. Hiervoor kun je het programma
perfiles gebruiken. Ook in dit geval
moeten de bestanden in een bepaald formaat zijn, zoals wordt uitgelegd in de
handleiding van het programma
perfiles.
Als je de data in een enkel werkblad hebt (spreadsheet), dan kun je het
programma
sssplit gebruiken om de
data op te splitsen in losse bestanden. Je moet dan eerst het werkblad
bewaren als een "tab-delimited file" of als een "comma-delimited file".