
Next: Conclusions
Up: Disambiguation
Previous: Dependency relations
While the model described in the previous section offers good
performance and conceptual simplicity, it is not without problems. In
particular, the strategies for dealing with reentrancies in the
dependency structures and for combining scores derived from penalty
rules and from dependency relation statistics are ad
hoc. Log-linear models, introduced to natural language processing by
[3] and [10], and applied to
stochastic constraint-based grammars by [1] and
[12], offer the potential to solve both of these
problems. Given a conditional log-linear model, the probability of a
sentence x having the parse y is:
As before, the partition function Z(x) will be the same
for every parse of a given sentence and can be ignored, so the score
for a parse is simply the weighted sum of the property functions
fi(x,y). What makes log-linear models particularly well suited for
this application is that the property functions may be sensitive to
any information which might be useful for disambiguation. Possible
property functions include syntactic heuristics, lexicalized and
backed-off dependency relations, structural configurations, and
lexical semantic classes. Using log-linear models, all of these
disparate types of information may be combined into a single model for
disambiguation. Furthermore, since standard techniques for estimating
the weights 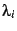 from training data make no assumptions about
the independence of properties, one need not take special precautions
when information sources overlap.
from training data make no assumptions about
the independence of properties, one need not take special precautions
when information sources overlap.
The drawback to using log-linear models is that accurate estimation of
the parameters requires a large amount of annotated
training data. Since such training data is not yet available, we
instead attempted unsupervized training from unannotated data. We used
the Alpino parser to find all parses of the 82,000 sentences with ten
or fewer words in the `de Volkskrant' newpaper corpus. Using the resulting
collection of 2,200,000 unranked parses, we then applied Riezler et
al.'s (2000) `Iterative Maximization' algorithm to
estimate the parameters of a log-linear model with dependency tuples
as described in the previous section as property functions. The
results, given in table 3, show some promise, but the
performance of the log-linear model does not yet match that of the
other disambiguation strategies. Current work in this area is focused
on expanding the set of properties and on using supervised training
from what annotated data is available to bootstrap the unsupervised
training from large quantities of newspaper text.
Next: Conclusions
Up: Disambiguation
Previous: Dependency relations
Noord G.J.M. van
2001-05-15