De taak van de syntactische analysecomponent is om in een zin de woordgroepen te onderscheiden, en hun onderlinge relaties vast te leggen. Het resultaat van deze component is meestal een syntactische analyseboom. Deze analyseboom kan dan weer gebruikt worden om door middel van semantische analyse de betekenis te achterhalen.
Bekijk het zinnetje:
![]()
In dit zinnetje is het duidelijk dat de `ik' persoon degene is die slaat, terwijl `de man' de geslagene is. Dit volgt uit de syntactische relaties in deze zin: `ik' is onderwerp van het gezegde, terwijl `de man' lijdend voorwerp is. Twee mogelijke analysebomen voor deze zin zijn de volgende:
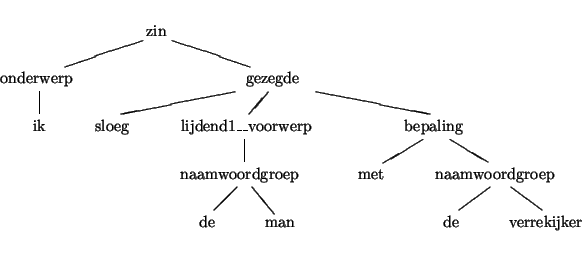
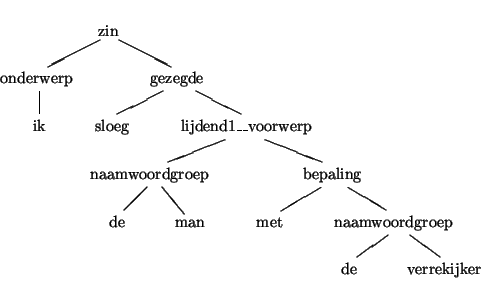
De eerste analyseboom kan worden gebruikt om de lezing af te leiden
waarbij de verrekijker gebruikt wordt als slaginstrument. In de tweede
analyseboom kan de lezing worden afgeleid waarbij de man toevallig een
verrekijker bij zich heeft, maar waarbij het slaginstrument ongenoemd
blijft. Deze voorbeelden tonen aan waarom syntactische
analyse van belang is om de betekenis van een zin te begrijpen.
Bij het automatisch ontleden van de zin (`parsing') onderscheiden we vaak aan de ene kant de grammatica die de regels voor bijvoorbeeld het Nederlands definieert; en aan de andere kant het algoritme dat bepaalt hoe je op grond van een grammatica een syntactische analyseboom kunt afleiden. Een grammatica bestaat vaak uit een verzameling herschrijfregels. Deze regels zien er bijvoorbeeld uit als in (5) en (6). Hierbij wordt (6) het woordenboek genoemd.


Deze syntactische regels bepalen hoe woordgroepen in het Nederlands
kunnen worden opgebouwd. De eerste regel stelt bijvoorbeeld dat een
zin zou kunnen bestaan uit een onderwerp gevolgd door een
gezegde. De rechtopstaande streep duidt aan dat er meerdere
mogelijkheden zijn.
Natuurlijk is bovenstaande grammatica slechts een fractie van de regels die je voor het Nederlands nodig zou hebben.
Daarnaast wordt bij zulke grammatica's meestal gebruik gemaakt van de mogelijkheid om attributen aan de verschillende categorieen mee te geven. Zo zal in een realistische grammatica de tweede regel in bovenstaand voorbeeld eisen dat de naamwoordgroep in de eerste naamval staat (in het Nederlands is dat van belang omdat `me' als onderwerp niet is toegestaan). Verder worden aan de syntactische regels al vaak de bijbehorende semantische regels toegevoegd. Hoewel dus conceptueel vaak semantische analyse wordt voorgesteld als een aparte component zijn syntactische en semantische analyse in de praktijk vaak gecombineerd. Wanneer we aan de voorgaande grammatica semantische regels toevoegen dan kan het resultaat er bijvoorbeeld als volgt uitzien (voor enkele regels):

Hier schrijven we de semantische representaties steeds na de schuine
streep ('/'). In de semantische representatie maken we gebruik van
variabelen (woorden die met een hoofdletter beginnen). De tweede regel
stelt dus dat de semantiek van een gezegde bestaat uit een predicaat
(de semantiek van het werkwoord Pred) toegepast op de semantiek van het
lijdend voorwerp Arg2.
De parser is een programma dat een binnenkomende zin volgens de gegeven grammatica analyseert. Er bestaan daarbij veel verschillende strategieën. De meeste strategieen zijn ontwikkeld in de informatica. De code van een computerprogramma moet door een computer immers ook eerst geanalyseerd worden voordat duidelijk is welke instructies in welke volgorde moeten worden uitgevoerd. Toch is er een belangrijk verschil: computerprogramma's zijn niet ambigu, terwijl natuurijke-taaluitingen dat wel zijn. Dit betekent dan ook dat de grammatica van bijvoorbeeld alle correcte Pascal programma's geen ambiguiteit hoeft toe te staan, terwijl een grammatica voor bijvoorbeeld het Nederlands dat wel moet toestaan.
Een mogelijke parseerstrategie is de bottom-up strategie. Hierbij worden aan de woorden in de zin eerst de categorielabels toegekend (zoals in het woordenboek gedefinieerd):

Vervolgens wordt steeds geprobeerd regels toe te passen. Hierbij wordt
gekeken of de reeks symbolen rechts van de pijl in een regel
overeenkomt met een reeks symbolen in de woordenrij. In bovenstaand
voorbeeld kunnen we `lidwoord' gevolgd door `naamwoord' samen
combineren tot een naamwoordgroep. Wanneer we systematisch alle
mogelijke regels toepassen onstaan de twee parseerbomen in (4).
Verschillende parseerstrategieen kunnen worden onderverdeeld aan de hand van een aantal criteria. Zo kan een algoritme bottom-up werken, zoals in het voorbeeld hierboven. In dat geval worden alle parseerbomen van beneden naar boven opgebouwd. In het omgekeerde geval spreekt men van top-down parsing. Gecombineerde varianten zijn ook mogelijk. Daarnaast kunnen parseeralgoritmen gekarakteriseerd worden door te kijken in welke volgorde de woorden uit de zin in de boom worden gehangen. Vaak gebeurt dit van links naar rechts, maar er zijn ook varianten waarbij de input zin bidirectioneel wordt doorlopen: sommige stukken van links naar rechts, maar andere delen van rechts naar links. Ten slotte worden parseeralgoritmes gekarakteriseerd aan de hand van de methode die wordt gebruikt om de zoekruimte te doorlopen: welke regel pas je het eerst toe. Belangrijk hierbij is ervoor te zorgen dat je al het werk slechts een keer wilt doen.