plot(lls$BAC, lls$ratingNL, xlab='BAC', ylab='rating (NL)')Statistiek I
Introduction to linear regression
Relation between two numerical variables
- We can visualize this relationship in a scatter plot
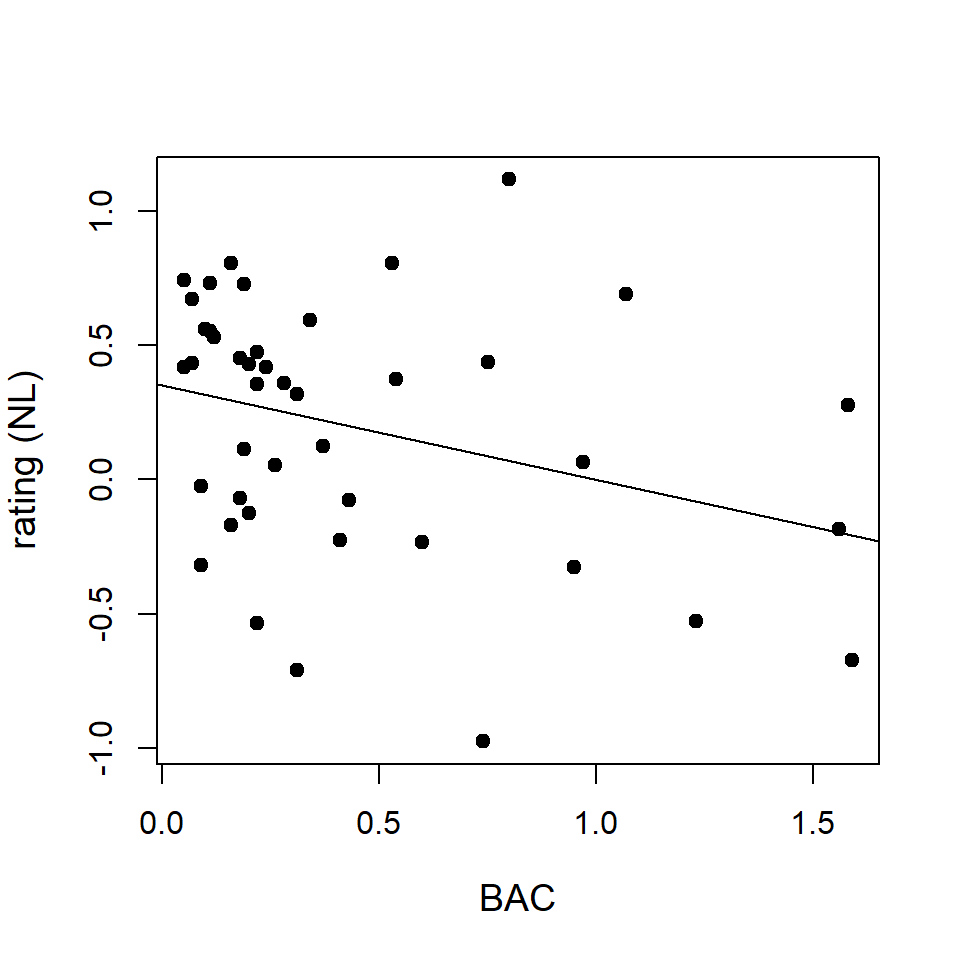
Correlation results
cor(lls$BAC, lls$ratingNL)[1] -0.31931(Cor)relation is not causation (1)

Linear regression: general formula
- Linear regression captures a linear relationship between dependent variable (DV) and independent variable(s) (IV)
- Regression formula: \(y = \beta_0 + \beta_1 x\)
- \(y\): dependent variable (= predicted or fitted values)
- \(x\): independent variable
- \(\beta_0\): intercept (fitted value of \(y\) when \(x = 0\))
- \(\beta_1\): influence (slope) of \(x\) on \(y\)
- Regression formula: \(y = \beta_0 + \beta_1 x\)

Linear regression: formula for individual data points
- General regression formula: \(y = \beta_0 + \beta_1 x\)
- Individual regression formula: \(y_i = \beta_0 + \beta_1 x_i + \epsilon_i\)
- \(x_i\): real \(x\)-value for observation \(i\)
- \(y_i\): real \(y\)-value for observation \(i\)
- \(\epsilon_i\): difference between \(y\) (fitted value) and \(y_i\) (actual value) \(\implies\) residual

Linear regression: example
Suppose \(\beta_0 = 2\) and \(\beta_1 = 1\), then regression formula equals: \(y = 2 + 1 \times x\)
Suppose \(x = 2\), then the regression model predicts: \(y = 2 + 1 \times 2 = 4\)
If actual \(y_i = 5\), then residual \(\epsilon_i = 5 - 4 = 1\)

Residuals: difference between actual and fitted values
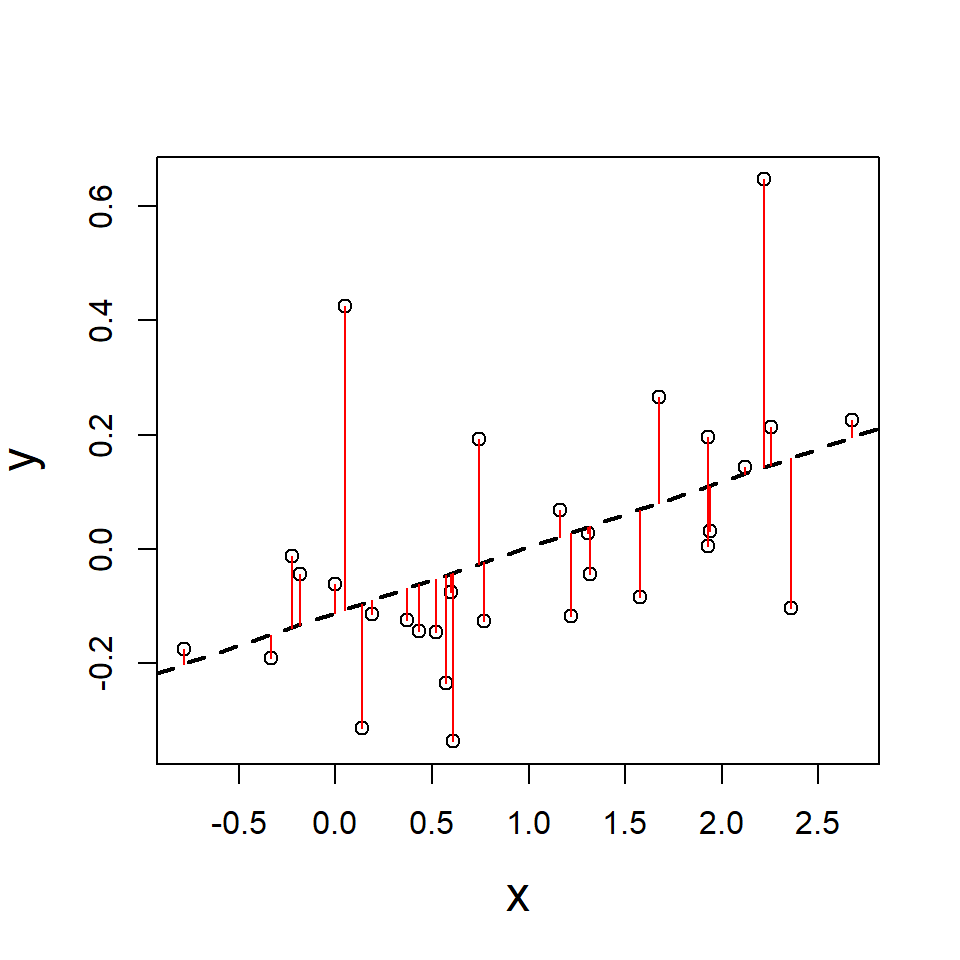
- Regression minimizes residual error (residuals: sum of squared errors)
- Thereby determining the optimal coefficients for intercept and slope(s)
Visualization is essential!
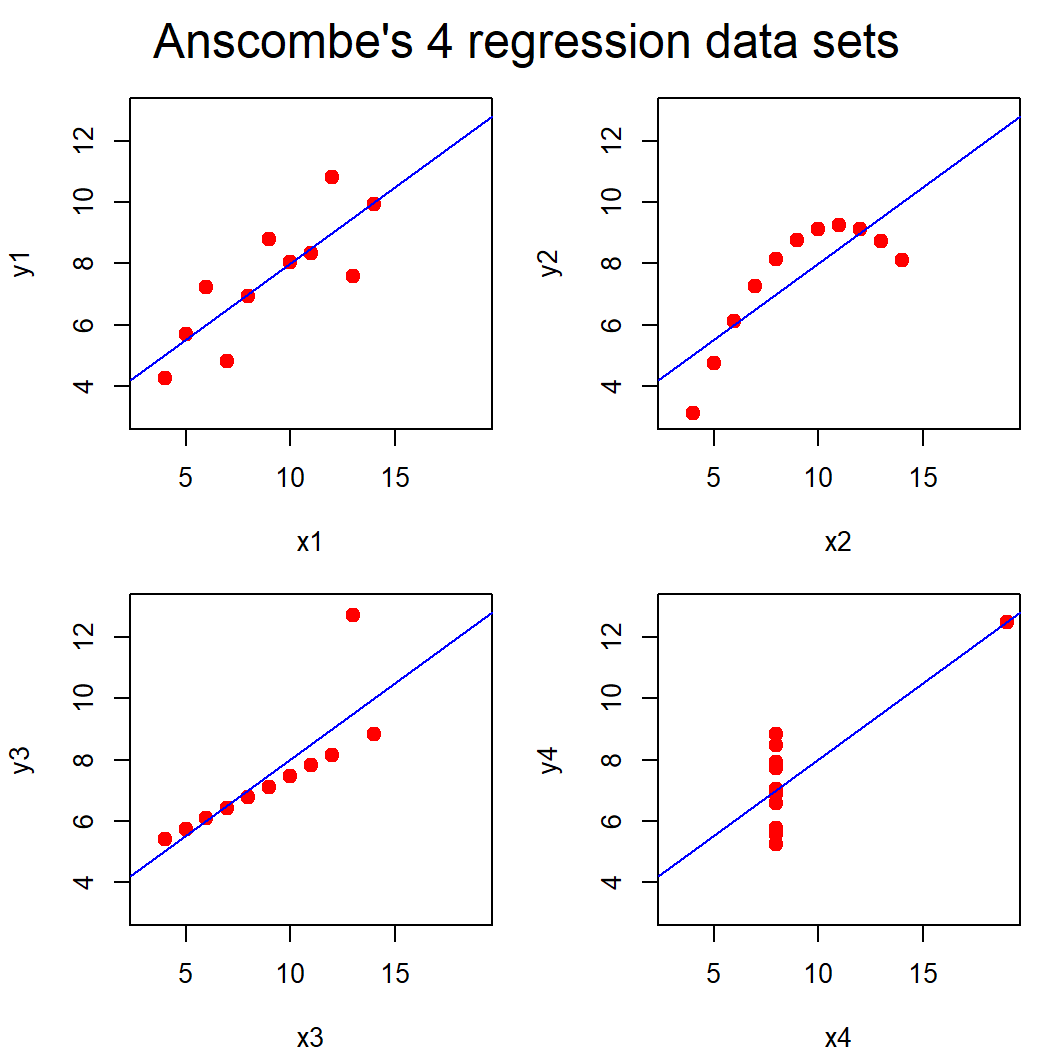
- Linear regression is only suitable in the top-left situation
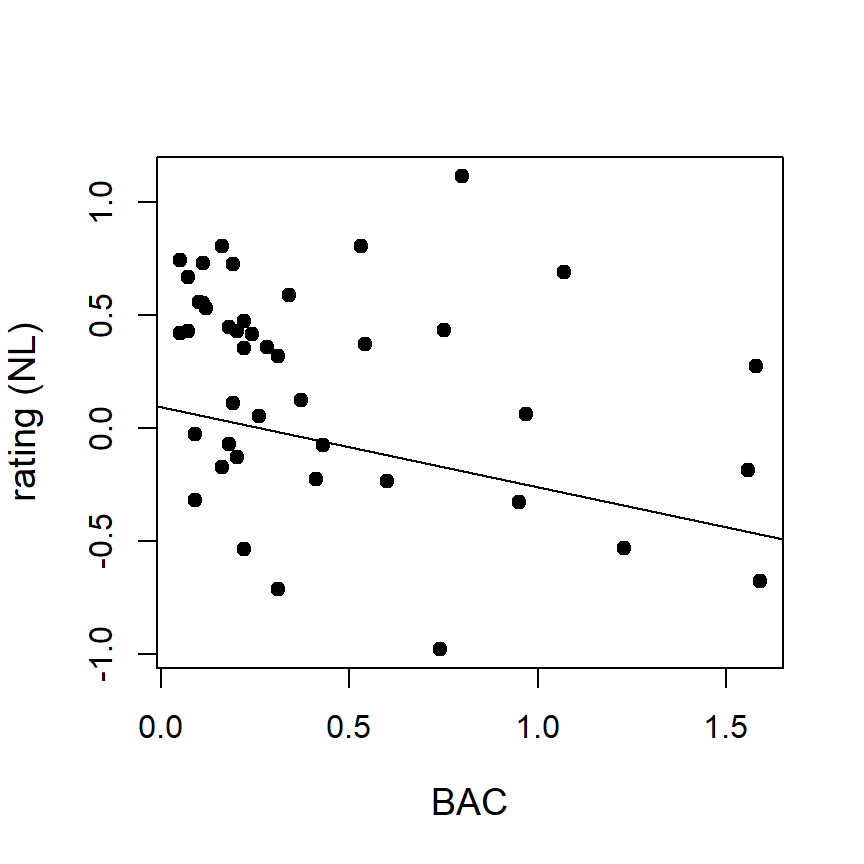
Visualizing the results
library(visreg) # load visreg package to visualize regression results
visreg(m, xlab = "BAC", ylab = "rating (NL)") # including 95% CI bands
abline(h=0, v=0, lty=2) # add x- and y-axis
Using the regression formula
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.34970 0.099513 3.5141 0.0010909
BAC -0.35049 0.162448 -2.1576 0.0368728- For
BACof \(0\) fittedratingNLof: \(0.35 +\,\) \(-0.35\, *\) \(0\) \(=\) \(0.35\) (= Intercept) - For
BACof \(0.5\) fittedratingNLof: \(0.35 +\,\) \(-0.35\, *\) \(0.5\) \(=\) \(0.175\) - For
BACof \(1.5\) fittedratingNLof: \(0.35 +\,\) \(-0.35\, *\) \(1.5\) \(=\) \(-0.175\)

Visual comparison: shifted axis

Visual comparison of the three models
visreg(m, xlab = "BAC (original)", ylab = "rating (NL)")
visreg(mc, xlab = "BAC (centered)", ylab = "rating (NL)") # note the shifted x-axis
visreg(mz, xlab = "BAC (z-transformed)", ylab = "rating (NL)") # note the different scale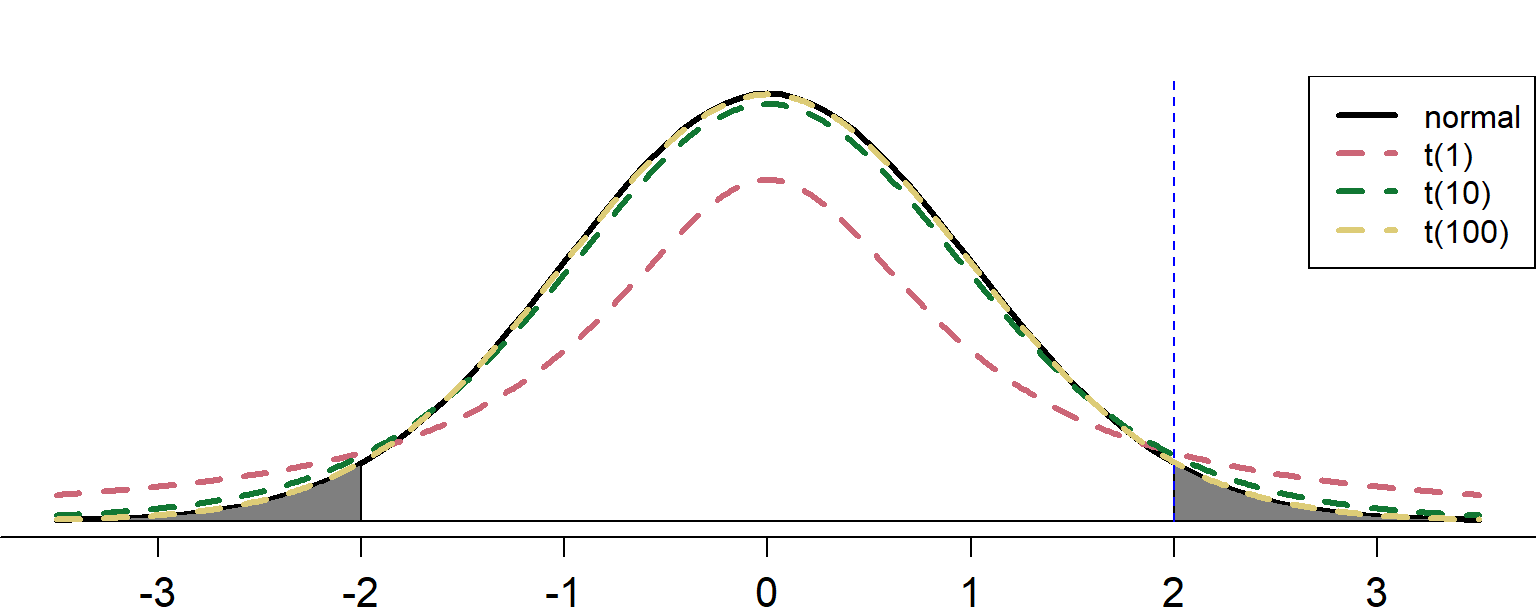
What are degrees of freedom?
- There are five balloons each having a different color
- There are five students (\(n = 5\)) who need to select a balloon
- If 4 students have selected a balloon (dF = 4), student nr. 5 gets the last balloon (fixed)

- If 4 students have selected a balloon (dF = 4), student nr. 5 gets the last balloon (fixed)
- Similarly, if we have a fixed slope and a fixed intercept with 43 observations
- 41 values may vary, but the 42nd and 43rd are fixed: dF = 43 - 1 - 1 = 41
- For regression, dF = N - V - 1 (with N: nr. of obs., V: nr. of independent variables)
Visualizing \(t\)-distributions

- For significance (given \(\alpha\)), higher (abs.) \(t\)-values are needed than \(z\)-values (but only when dF < 100, otherwise \(z\) and \(t\) are equal)
qt(0.025, df=5, lower.tail=F) # critical t-value (alpha = 0.025) for dF = 5[1] 2.57Answer to question 7
pt(2, 10, lower.tail=F) * 2 # two-sided p-value = 2 * one-sided p-value[1] 0.0734
- Dark gray area: \(p\) < 0.05 (2-tailed)
Model assumptions for linear regression
- Four important requirements:
- Distribution of residuals is assumed to follow a normal distribution
- Variance of residuals should be equal along the regression line (homoscedastic)
- Independent observations (only one value per individual for the dependent variable)
- Relationship between dependent variable and independent variable is linear (assumed to be true during this course; would also become clear in residuals if not)

Does our model satisfy the required assumptions?
par(mfrow=c(1,3))
qqnorm(resid(m))
qqline(resid(m)) # approximately normal
plot(lls$BAC, resid(m), main='Variance of residuals (vs predictor)') # approx. constant
plot(fitted(m), resid(m), main='Residual variance (vs fitted)') # = homoscedastic