The most time consuming part of doing dialect research is the collecting and
digitalisation of data. The data must be available in the specific file
format that
RuG/L04 can handle. If this wasn't
taken into account during digitalisation, you have to convert the data.
The files used by the software, both data and other files, have a human-readable
format. This means that you can edit the files with any editor for
plain text, but this also means that you can
use simple tools such as Perl scripts to process the files. If the data
is in a binary format, for example stored by a database application, you must use that
application to export the data. You use that program to write
the data in a format necessary for RuG/L04,
or in another plain text format, so you can use a script to make the
final conversion.
In addition to the data, there are some other files you need.
You need a file with numbered list of names of location. The file format is
explained in
label file.
(As an example, have a look at the file PA.lbl that was used in the previous
two chapters of this tutorial.)
If you want to get the local incoherence of a
measurement
(see part 6), you'll need a file with
coordinates of the locations. See coordinate file for a
description of the file format. You also need this file if you want to
draw maps. (Example: the file PA.coo used in the previous chapters.)
Other helper files are used only for drawing maps, and are discussed in
part 5 of the tutorial.
Below is a discussion of the file format of the actual dialect data.
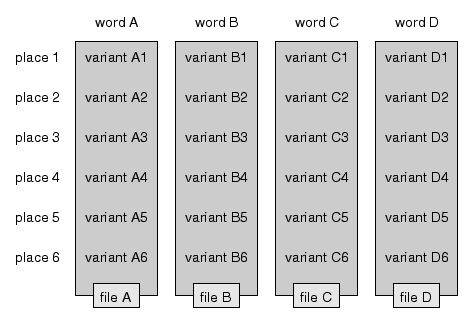
Dialect data consists of variants of a series of words (or word groups) as they
are recorded in a series of locations. This data is grouped into a set of
files. A single file has all the variants of one word for all locations. This
is illustrated in the diagram below:
Here is an overview of the file format for individual files.
Note that, in the diagram above, each location has exactly one variant. That
doesn't need to be. You can have for one word more than one variant for a single
location, or none at all.
Suppose you have all data neatly distributed in a set of files, but not with
all variants of one word for all locations in one file, but all variants
of all words for a single location in one file, like this:
In this case, you need to redistribute the data. For this, you can use the
perfiles program. In this case too, the
data needs a specific format to be handled, as is explained in the manual
of
perfiles.
If you have the data in a single spreadsheet, then you can use the
sssplit program to split the data into a
set of separate files. You need to save the spreadsheet first as a
tab-delimited file or as a comma-delimited file.