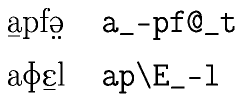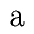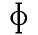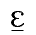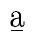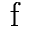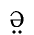At the moment, there is no data available to demonstrate things. As soon as
this changes, this page will be updated.
The Levenshtein algorithm in its simplest form compares two sequences of
characters and all that matters is whether or not two characters are the
same. When you want to determine differences based on phonetic
differences, then there is much room for improvement. You want to compare
sequences of sounds. Though there is a relationship between a sequence of
sounds and the sequence of characters used to record that sound sequence,
so with a simple Levenshtein measurement you get a reasonable impression
of dialect differences (see
part 2), it
is not the most accurate method imaginable.
There are two issues:
- Often, a sound is not recorded with a simple character, but with a sequence
of characters.
- There is much variation in how much two sounds differ from each other.
Below are two words. On the left, transcribed in phonetic writing. On the right,
transcribed with X-Sampa, a coding system useful for writing phonetic
script with a standard keyboard, using the standard US-ASCII character
set.
(See: IPA/X-SAMPA chart by Andrew Mutchler)
Both words consist of a sequence of four sounds. But in electronic form, they
are recorded as sequences of eight and seven characters, in this example,
using one to three characters per sound. Not only accents are coded by
adding extra characters, basic sounds too are often coded using more than
one character, like the combination of
p\ for
the second sound in the second word.
What happens if you compare these two sequences with the Levenshtein algorithm
is shown in the diagram below. (See also:
Levenshtein demo)
The first step to come to a more accurate measurement is splitting the
character sequence into tokens. Each group of characters that represents
one phonetic base symbol or one accent is taken as one token. You can use
the
xstokens program to do this.
After this tokenisation, Levenshtein runs like this:
Unfortunately in this case, there is no improvement. You have to go one step further.
Sounds have features. You could say that the more features are different
between two sounds, the more different those two sounds are. Instead of
comparing sounds as single units, you could split each sound into a
sequence of features, and thus, you could compare features.
Vowel sounds differ from each other, among other things, by the location in the
mouth of the highest point of the tongue: in front, in the middle, or
in the back of the mouth. You can code for this feature with a sequence
of two tokens:
| tongue | coding
|
|---|
| front | Ta1 Tb1
|
| middle | Ta0 Tb1
|
| back | Ta0 Tb0
|
This way, a front vowel differs one token from a middle vowel, and two tokens
from a back vowel.
You can do a similar thing for the jaw position:
| jaw | coding
|
|---|
| closed | Ja1 Jb1 Jc1
|
| half closed | Ja0 Jb1 Jc1
|
| half opened | Ja0 Jb0 Jc1
|
| opened | Ja0 Jb0 Jc0
|
And for the position of the lips:
| lips | coding
|
|---|
| rounded | L1
|
| unrounded | L0
|
So, each single vowel sound is replaced by a long sequence of tokens. For
example, the "i":
i: Ta1 Tb1 Ja1 Jb1 Jc1 L0
| | | | | |
| | | | | +---> unrounded
| | | | |
| | +---+---+---> closed
| |
+---+---> front
This differs only slightly (1 token) from the "y":
y: Ta1 Tb1 Ja1 Jb1 Jc1 L1
| | | | | |
| | | | | +---> rounded
| | | | |
| | +---+---+---> closed
| |
+---+---> front
But the difference with "o" is much bigger (4 tokens):
o: Ta0 Tb0 Ja0 Jb1 Jc1 L1
| | | | | |
| | | | | +---> rounded
| | | | |
| | +---+---+---> half closed
| |
+---+---> back
You can use the xtokens program to do all this
recoding, and then use leven to
measure the differences.
This method is reasonably simple, and more accurate than an ordinary
Levenshtein measurement based on the original character sequences. But
it isn't perfect:
- The effective weight of a feature is determined by the number of tokens
used to code it. So you have to strike the correct balance.
- The coding of basic sounds combined with the coding of accents can be
unfortunate. Suppose, you have a front vowel with an accent that
indicates that it is a little less fronted than it would have been
without the accent, and you have a middle vowel with an accent that
puts it little towards the front. These two sounds are thus less
different than two sounds written without these accents, but with our
coding scheme, they will look more different, not less.
- The coded sequences are much longer than the uncoded sequences, and since
the number of computations for the Levenshtein algorithm increases with
the product of the length the two sequences, the overall measurement
can become very time-consuming.
We take another step. We split the sequence of characters into basic sounds and accents, and
then join each basic sound and its accents into a single token. A simple
Levenshtein measurement based on such tokens run like this:
Two sequences of four sounds each, and none of the sounds in one word is
identical to any sound in the other word, so the measured difference is
maximal. That is not what we want. We don't want the substitution of two
different sounds to give the maximal value, but a value based on the
actual difference of both sounds. Like this:
First you get the comparison of two a-like sounds, then the deletion of a p,
then the comparison of two f-like sounds, then the comparison of two
e-like sounds, and finally the insertion of an l.
The procedure to get to such a measurement involves the following steps:
- Making a detailed description of tokens and their associated features, and
of how the features of accents combine with features of basic sounds.
- Converting the files with dialect data, such that each token sequence
(one basic sound plus features) that represent a unique sound is
replaced by a single, unique token.
- Determining the distances between tokens based on the differences of their
(phonetic) feature values. Steps 2 and 3 are done with the
features program, based on the
definition you wrote in step 1.
- Determining the Levenshtein differences with the leven
program, of the recoded dialect data made in step 2, using the differences
between tokens that were calculated in step 3.
Unfortunately, step 1 is quite complex. Whether this procedure justifies the
effort depends partly on the condition of the data. You could strive for
a feature/value definition that is as scientifically correct as possible,
but if the data wasn't collected very carefully, if the data contains too
much noise, then it doesn't pay to take your analysis efforts this far.