Theoretical linguistics has developed extensive and precise accounts of the grammatical knowledge implicit in our use of language. It has been able to adduce explanations of impressive generality and detail. These explanations account for speakers' discrimination between different linguistic structures, their ability to distinguish well-formed from ill-formed structures, and their ability to assign meaning to such well-formed structures. Grammars are hypothesised which model the well-formed utterances of a given natural language and the meaning representations which correspond with these utterances.
The smaller and younger field of computational linguistics has also been successful in obtaining results about the computational processing of language. These range from descriptions of dozens of concrete algorithms and architectures for understanding and producing language (parsers and generators), to careful theoretical analysis of the underlying algorithms. The theoretical analyses classify algorithms in terms of their applicability, and the time and space they require to operate correctly. The scientific success of this endeavour has opened the door to many new opportunities for applied linguistics.
However a number of important research problems have not been solved. An important challenge for computational accounts of language is the observed efficiency and certainty with which language is processed. The efficiency challenge is both theoretical and practical: grammars with transparent inspiration from linguistic theory cannot be processed efficiently. This can be demonstrated theoretically, and has been corroborated experimentally. In current practice, such grammars are recast into alternative formats, and are restricted in implementation. Effectively, large areas of language are then set aside.
The certainty with which language is processed is not appreciated generally. But careful implementation of wide-coverage grammars inevitably results in systems which regard even simple sentences as grammatically ambiguous, even to a high degree. The computational challenge is to incorporate disambiguation into processing.
There are two central leading hypotheses of the project. We shall explore approximation techniques which recast theoretically sound grammars automatically into forms which allow for efficient processing. The hypothesis is that processing models of an extremely simple type, namely finite automata, can be employed. The use of finite automata leads to interesting hypotheses about language processing, as we will argue below.
Second, we test the hypothesis that certainty can be accounted for--at least to some extent--by incorporating the results of language experience into processing. This will involve the application of machine learning techniques to grammars in combination with large samples of linguistic behavior, called corpora. Such techniques will ensure that a given utterance, which receives a number of competing analyses if considered in isolation, will receive a single analysis if the relevant context and situation are taken into account.
The project aims furthermore at significant partial results. In order to test its processing claims, large scale grammars of some theoretical ambition must be tested. While these exist now for English, the project will devote resources to extending existing Dutch grammars to further test the claims. An extensive Dutch grammar in the public domain would be a major contribution to Dutch computational linguistics and to the international community. Second, the processing techniques and concrete implementations are technology which directly enables a number of interesting applications in spoken language information systems, language instruction, linguistic research, grammar checking, and language aids to the disabled.
Naturally there have been attempts to process theoretically well-informed grammars using a range of grammar theories. For example, the Alvey project implemented a wide coverage Generalized Phrase Structure Grammar (GPSG) [19,45,38]. The grammar illustrates both difficulties, inefficient processing and ambiguity.
The Alvey grammar eschews the abstract formulation favoured by contemporary theorists. It is purely context-free in form, and makes use of a small number of mostly atomic-valued features.2.1 Most GPSG grammar principles are not represented directly at all; rather, the grammarian is required to keep these in mind. In particular, the grammarian should write no rules or lexical entries in violation of the principles, but there is no mechanism for the grammarian to write principles which the parser will attend to. So on the one hand the grammar makes concessions to processing difficulties.
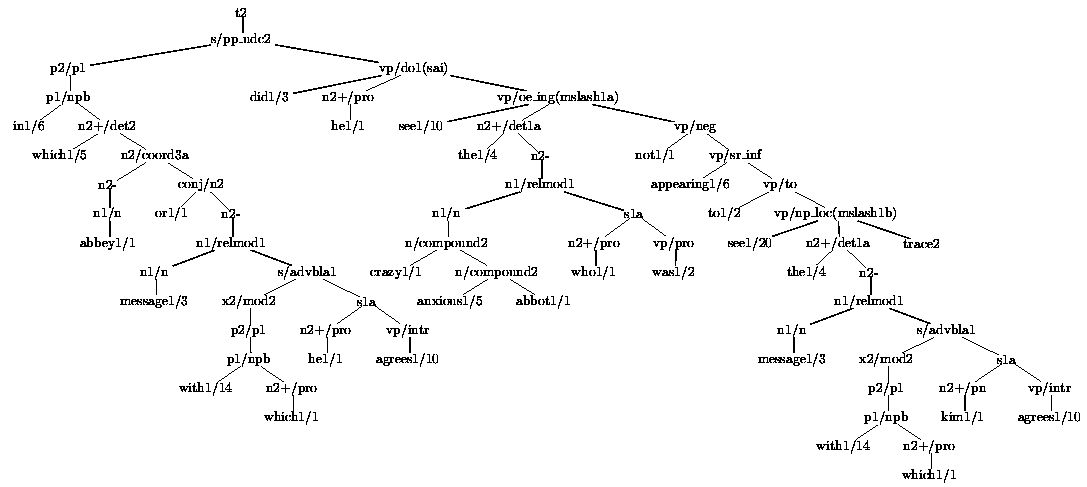
Massive ambiguity on the other hand could not be circumvented. For longer sentences hundreds and even thousands of readings are associated with a single sentence. One of the test-sentences of the Alvey NL Tools grammar is the question In which abbey or message with which he agrees did he see the crazy anxious abbot who was not appearing to see the message with which kim agrees? The sentence is peculiar because the lexicon was minimal, but its peculiarity does not explain how the grammar assigns it 2,736 distinct readings, each of which is motivated linguistically. One of the parse-trees is given in figure 2.1.
 |
How shall we deal with inefficiency and massive ambiguity? We propose to investigate solutions to these problems along the following two dimensions.
To prevent inefficiency we shall explore automated grammar approximation. Techniques will be investigated in which natural language grammars expressed in powerful constraint-based grammatical formalisms are approximated by devices of a much more simple form (typically by finite-state devices). Progress in this area would explain the relation of linguistic competence and linguistic performance; at the same time it would facilitate the practical application of more advanced natural language processing techniques in practical applications. Contributions are foreseen not only from theoretical and computational linguistics, but also from mathematical linguistics and psycholinguistics.
To account for the certainty of human communication, we shall investigate automated grammar specialisation, a means of optimising a theoretical grammar on the basis of a corpus of representative linguistic behavior. Applications of specialisation will yield specialised, less ambiguous grammars but in a manner which does not rely on the grammarians' intuitions. Such specialised grammars may be expected to take the form of hybrid systems which combine rules with statistical information. Contributions are foreseen from theoretical linguistics, computational linguistics, information theory and machine learning. Progress in this area will contribute to our theoretical understanding of disambiguation and will facilitate the portability of natural language processing components.
The most important innovation of the proposed project is the combination of linguistically sound grammars on the one hand with corpus-based techniques on the other hand. The area of computational linguistics has seen a shift of perspective over the last ten years. After a period in which `knowledge-based' approaches towards computational linguistics dominated the field, in combination with applications which only had a long-term potential (such as fully automatic, high quality translation), the last ten years corpus-based and probabilistic techniques have become quite popular, together with more emphasis on less ambitious applications with short-term potential.
We feel that this shift of attention was beneficial because of its emphasis on evaluation and `real-world' problems. We also feel, however, that this `no-nonsense' attitude has neglected some of the potential that linguistics has to offer. We believe that in order to be able to extend the state of the art to larger domains of applicability it is necessary to import linguistic insights again. And furthermore, such a connection with theoretical linguistics is warranted from a theoretical point of view.
The innovative aspect of the current proposal therefore is that it
combines a corpus-based evaluation methodology with a sound
linguistic basis.
Another innovative aspect of the proposal is that it focuses on the Dutch language, and hence on Dutch linguistics, and Dutch language technology. This is an important aspect of the proposal, since we believe it is important that language technology is developed for Dutch in addition to the current developments for languages such as English, German and French. Language technology applications such as grammar checkers, dictation systems, documentation systems and aids to the handicapped are cultural bonuses that should accrue not only to the speakers of majority languages.
A recent overview on Dutch Language and Speech Technology
[11] reports that there are many fewer language
technology resources available for Dutch (as compared to English). In
particular, the report signals a need for implemented Dutch grammars.
The present proposal accords with one of the report's recommendations:
fundamental and applied research in language and speech technology in
Dutch should be stimulated.
The research project aims to answer the question of how it is that knowledge of language is applied in communication. Two major concerns can be identified. Firstly, it is important to understand how it is possible that knowledge of language is applied so efficiently by humans when they understand and produce natural language. We propose to investigate the hypothesis that natural language processing is finite-state in nature. This hypothesis is explained in more detail in section 2.2.
Secondly, humans are also very good at disambiguation; natural language users quickly discard ridiculous readings of a given sentence by taking into account the context and situation of the utterance. We propose to investigate techniques which are capable of augmenting the knowledge of language (modelled in the form of a grammar) with a theory of how this knowledge of language is usually applied. Below, in section 2.3, we refer to such techniques as grammar specialisation in order to stress the fact that we take a linguistic grammar (the model of the knowledge of language) as an important point of departure for such techniques.
Although the proposed research aims at general answers to the above-mentioned questions we believe strongly in a methodology in which concrete proposals are developed and compared. For this reason we want to be able to apply and evaluate such concrete proposals on a specific grammar of Dutch. This aspect of the proposal is defined in section 2.4.
Moreover, we propose to apply some of the approximation and disambiguation techniques in lgrep: a linguistic search tool for bare text-corpora (section 2.5). Such a tool would be useful for (computational) linguists working with corpora, but also as an extension to traditional grammars as used by language learners, to be able to obtain example sentences of particular constructions upon request. The tool will also be useful for the proposed research itself; for each of the proposed research areas corpus exploration is important and therefore such a corpus exploration tool will be a useful tool.