The annotation process typically starts by parsing a sentence with the Alpino grammar. This produces a (often large) number of possible analyses. The annotator picks the analysis which best matches the correct analysis. To facilitate selection of the best parse among a large number of possibilities, the HDRUG environment has been extended with a graphical tool based on the SRI TreeBanker [8] which displays all fragments of the input which are a source of ambiguity. By disambiguating these items (usually a much smaller number than the number of readings), the annotator can quickly pick the most accurate parse.
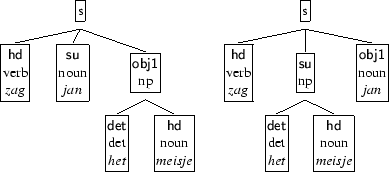
For example, the sentence Jan zag het meisje `Jan saw the girl' has (in principle) two readings corresponding to the dependency structures in figure 3.
The readings of a sentence are represented as a set of sets of dependency paths, as in figure 4. From these sets of paths, the parse selection tool computes a set of maximal discriminants which can be used to select among different analyses. In this case, the path `s:hd = v zag' is shared by all the analyses and so is not a useful discriminant. On the other hand, the path `s:obj1:hd = n meisje' does distinguish between the readings but it is not maximal, since it is subsumed by the path `s:obj1 = np het meisje' which is shorter and makes exactly the same distinctions. The maximal discriminants are presented to the annotator, who may mark any of them as either good (the correct parse must include it) or bad (the correct parse may not include it). In this simple example, marking any one of the maximal discriminants as good or bad is sufficient to uniquely identify the correct parse. For more complex sentences, several choices will have to be made to select a single best parse. To help the annotator, when a discriminant is marked as bad or good, the following inference rules are applied to further narrow the possibilities [8]:If the parse selected by the annotator is fully correct, the dependency structure for that parse is stored as XML in the treebank. If the best parse produced by the grammar is not the correct parse as it should be included in the treebank, the dependency structure for this parse is sent to the Thistle editor.4 The annotator can now produce the correct parse manually.
We have started to annotate various smaller fragments using the annotation tools described above. The largest fragments consist of two sets of sentences extracted from the Eindhoven corpus [19]. The CDBL10 treebank currently consists of the first 519 sentences of ten words or less from section CDBL (newspaper text). The CDBL20 treebank consists of the first 252 sentences with more than 10 but no more than 20 words.