

Natuurlijke-taalinterfaces
Gosse Bouma and Gertjan van Noord
Vakgroep Alfa-informatica & BCN
Rijksuniversiteit Groningen
vannoord@let.rug.nl
Natuurlijke-taalinterfaces zijn computerprogramma's die je in staat
stellen in natuurlijke taal met een computer te communiceren. Sommige
natuurlijke-taalinterfaces werken met gesproken taal, andere met input
via een toetsenbord. Natuurlijke-taalinterfaces zijn vooral populair
voor informatiesystemen.
Een voorbeeld van een natuurlijke-taalinterface is een systeem waaraan
momenteel door een aantal Nederlandse onderzoeksgroepen wordt
gewerkt: een systeem dat informatie verschaft over het
openbaar vervoer, en dat je per telefoon in gesproken taal kunt
raadplegen.
In dit hoofdstuk bespreken we natuurlijke-taalinterfaces. In deze
paragraaf leggen we ten eerste uit waarom in sommige gevallen
natuurlijke-taalinterfaces te verkiezen zijn boven andere interfaces
(zoals grafische interfaces, of interfaces die gebruik maken van
een speciaal programmeertaaltje).
In sectie 2 bespreken we de problemen waarmee je te maken krijgt
wanneer je een natuurlijke-taalinterface wilt bouwen. Sectie 3 geeft
een overzicht van een aantal technieken uit de
natuurlijke-taalverwerking die in geavanceerde
natuurlijke-taalinterfaces vaak worden gebruikt. In de laatste sectie
bespreken we ten slotte kort enkele bestaande systemen en de
prestaties die op dit moment mogelijk zijn.
Een belangrijk voordeel van het gebruik van natuurlijke-taalinterfaces
is dat iedereen natuurlijke taal kan spreken. Je hoeft dus niet
ingewerkt te worden, een speciale programmeertaal te leren, of de
betekenis van allerlei ingewikkelde muisacties te doorgronden. Dit
voordeel is natuurlijk cruciaal voor informatiesystemen die gericht
zijn op de `gewone' gebruiker, en niet speciaal ontworpen zijn voor
een klein aantal specialisten.
Een tweede voordeel is dat natuurlijke taal expressief is. Alles wat
je zou kunnen willen vragen kun je in natuurlijke taal uitdrukken. Het
is dan ook zo dat mensen vaak het gebruik van natuurlijke taal
prefereren. Dit is vooral zo wanneer je niet precies weet wat je
wilt vragen of wanneer je niet precies weet welke informatie
beschikbaar is. In zulke gevallen is vaak eerder sprake van het
collaboratief probleemoplossen of `onderhandelen' in plaats van het
direct stellen van gerichte vragen. Dit voordeel is het grootst
wanneer gebruik wordt gemaakt van gesproken taal.
Er zijn nog meer speciale voordelen verbonden aan het gebruik van
gesproken natuurlijke taal. Telefonische interfaces staan het
gebruik van een informatiesysteem over grotere afstand toe, zonder dat
de gebruiker daarbij de beschikking hoeft te hebben over een
computerterminal. Dit is voorlopig nog wel een belangrijk voordeel ten
opzichte van interfaces die bijvoorbeeld van netwerken zoals
Internet gebruik maken.
Gesproken-taalinterfaces zijn daarnaast mogelijk in situaties waarbij
je je handen niet kunt gebruiken. Je kunt hierbij bijvoorbeeld denken
aan een systeem dat in een auto informatie kan verschaffen over de te
volgen route, of de te verwachten verkeersdrukte.
Aan het gebruik van natuurlijke taal kleven ook nadelen. Zo is
natuurlijke taal vaak niet erg precies, of meerduidig, of niet erg
compact. Dit kunnen redenen zijn dat informatiesystemen die gericht
zijn op gespecialiseerde gebruikers gebruik maken van speciale
interfaces. Maar het belangrijkste praktische bezwaar tegen het
gebruik van natuurlijke taal is voorlopig domweg dat de huidige
mogelijkheden nogal beperkt zijn. Het is voor een computer (nog?)
ontzettend moeilijk een gebruiker in natuurlijke taal precies te
begrijpen.
Wat je ook doet
de semantiek gooit roet
Battus
Het belangrijkste probleem waar een natuurlijke-taalinterface tegen
aanloopt is het probleem van de meerduidigheid of
ambiguïteit. Bijna elke taaluiting is in isolatie
meerduidig. Mensen hebben daarmee geen enkele
moeite. Na het horen van het zinnetje:

komen alleen taalkundigen op het idee dat deze zin ook zou kunnen
betekenen dat Jan boven op het stationsgebouw aan het wachten
is.
Waarom weten mensen nu wat de bedoelde betekenis is? Het lijkt
erop dat je om zulke vragen te kunnen beantwoorden in het algemeen
ontzettend veel informatie moet hebben over hoe de wereld in elkaar
zit, en wat `normale' acties van mensen zijn. Een computer ontbeert
zulke kennis en heeft dus vaak de neiging teveel analyses aan een uiting toe te kennen: namelijk ook allerlei
zeer onwaarschijnlijke analyses. Disambiguatie
(het toekennen van de bedoelde lezing aan een meerduidige zin)
is daarom een belangrijke taak.
Het omgekeerde probleem doet zich ook voor. Natuurlijke
taal-interfaces zijn vaak niet robuust. Mensen maken vaak
`foutjes' in hun taalgebruik (vooral in gesproken taal), ze gebruiken
nieuwe woorden, ze gebruiken soms even een vreemde taal. Een typische
opmerking van een gebruiker tegen een openbaar vervoer informatie systeem
zou kunnen zijn:

Dus zelfs wanneer het systeem de regels van het Nederlands perfect
beheerst moet het systeem in dit voorbeeld eerst ontdekken dat de
gebruiker zichzelf enige malen in de rede viel en stukjes van zijn
eigen uiting corrigeerde.
Opnieuw geldt dat mensen met dit probleem geen enkele
moeite hebben; voor machines is dit echter wel degelijk een groot
struikelblok.
Zoals in hoofdstuk XXX al is aangetoond kan ook het (door een
computer) omzetten van spraak naar tekst (spraakherkenning) nog niet
beschouwd worden als een opgelost probleem. Dit betekent voor het
systeem eigenlijk dat in input `onzeker' is. Vaak levert een
spraakherkenner bijvoorbeeld verschillende kandidaatzinnen op. De
bovengenoemde problemen worden hierdoor alleen maar
moeilijker op te lossen.
Over het algemeen zijn er in een natuurlijke-taal interface een aantal
verschillende componenten te onderscheiden. De volgende
componenten bespreken we in de loop van dit hoofdstuk in wat meer
detail:
- Syntactische analyse. In deze component worden de woordgroepen
onderscheiden, en hun onderlinge syntactische relaties bepaald.
- Semantische analyse. Op basis van de syntactische analyse wordt
in deze component een representatie van de betekenis van de uiting
gebouwd.
- Dialoogvoering en database raadpleging. In deze component wordt
aan de hand van de vergaarde informatie bijvoorbeeld een database
geraadpleegd. Indien nog niet genoeg informatie voorhanden is zal
deze component verantwoordelijk zijn voor het stellen van een vraag
ter verduidelijk aan de gebruiker.
- Taalgeneratie. Sommige natuurlijke-taal interfaces bevatten ook
een taalgeneratie component. Deze component wordt aan de ene kant
gebruikt voor het stellen van vragen door het systeem, bijvoorbeeld
wanneer de vraag van de gebruiker nog niet duidelijk genoeg
was. Daarnaast is het soms zo dat de antwoorden in natuurlijke taal
gepresenteerd moeten worden. In deze component wordt een
representatie van een stukje betekenis omgezet in een reeks
woorden.
In het geval sprake is van een gesproken
natuurlijke-taalinterface komen hier nog twee componenten bij:
automatische spraakherkenning en automatische spraaksynthese. Deze
componenten worden besproken in een ander hoofdstuk.
De taak van de syntactische analysecomponent is om in een zin de
woordgroepen te onderscheiden, en hun onderlinge relaties vast te
leggen. Het resultaat van deze component is meestal een syntactische analyseboom. Deze analyseboom kan dan weer gebruikt
worden om door middel van semantische analyse de betekenis te
achterhalen.
Bekijk het zinnetje:

In dit zinnetje is het duidelijk dat de `ik' persoon degene is die
slaat, terwijl `de man' de geslagene is. Dit volgt uit de syntactische
relaties in deze zin: `ik' is onderwerp van het gezegde, terwijl `de man'
lijdend voorwerp is. Twee mogelijke analysebomen voor deze zin zijn de
volgende:
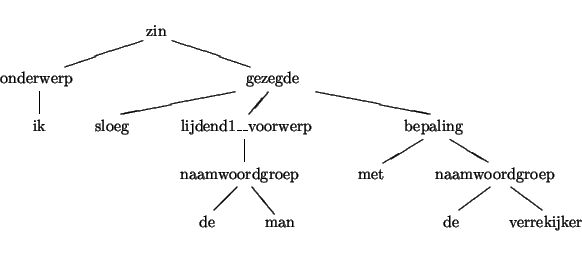

De eerste analyseboom kan worden gebruikt om de lezing af te leiden
waarbij de verrekijker gebruikt wordt als slaginstrument. In de tweede
analyseboom kan de lezing worden afgeleid waarbij de man toevallig een
verrekijker bij zich heeft, maar waarbij het slaginstrument ongenoemd
blijft. Deze voorbeelden tonen aan waarom syntactische
analyse van belang is om de betekenis van een zin te begrijpen.
Bij het automatisch ontleden van de zin (`parsing') onderscheiden we
vaak aan de ene kant de grammatica die de regels voor
bijvoorbeeld het Nederlands definieert; en aan de andere kant het
algoritme dat bepaalt hoe je op grond van een grammatica een
syntactische analyseboom kunt afleiden. Een grammatica bestaat vaak
uit een verzameling herschrijfregels. Deze regels zien er bijvoorbeeld
uit als in (5) en (6). Hierbij wordt (6) het woordenboek genoemd.


Deze syntactische regels bepalen hoe woordgroepen in het Nederlands
kunnen worden opgebouwd. De eerste regel stelt bijvoorbeeld dat een
zin zou kunnen bestaan uit een onderwerp gevolgd door een
gezegde. De rechtopstaande streep duidt aan dat er meerdere
mogelijkheden zijn.
Natuurlijk is bovenstaande grammatica slechts een fractie van
de regels die je voor het Nederlands nodig zou hebben.
Daarnaast wordt bij zulke grammatica's meestal gebruik gemaakt van de
mogelijkheid om attributen aan de verschillende categorieen mee te
geven. Zo zal in een realistische grammatica de tweede regel in
bovenstaand voorbeeld eisen dat de naamwoordgroep in de eerste naamval
staat (in het Nederlands is dat van belang omdat `me' als onderwerp
niet is toegestaan). Verder worden aan de syntactische regels al vaak
de bijbehorende semantische regels toegevoegd. Hoewel dus conceptueel
vaak semantische analyse wordt voorgesteld als een aparte component
zijn syntactische en semantische analyse in de praktijk vaak
gecombineerd. Wanneer we aan de voorgaande grammatica semantische
regels toevoegen dan kan het resultaat er bijvoorbeeld als volgt
uitzien (voor enkele regels):

Hier schrijven we de semantische representaties steeds na de schuine
streep ('/'). In de semantische representatie maken we gebruik van
variabelen (woorden die met een hoofdletter beginnen). De tweede regel
stelt dus dat de semantiek van een gezegde bestaat uit een predicaat
(de semantiek van het werkwoord Pred) toegepast op de semantiek van het
lijdend voorwerp Arg2.
De parser is een programma dat een binnenkomende zin volgens de
gegeven grammatica analyseert. Er bestaan daarbij veel verschillende
strategieën. De meeste strategieen zijn ontwikkeld in de
informatica. De code van een computerprogramma moet door een computer
immers ook eerst geanalyseerd worden voordat duidelijk is welke
instructies in welke volgorde moeten worden uitgevoerd.
Toch is er een belangrijk verschil: computerprogramma's zijn niet
ambigu, terwijl natuurijke-taaluitingen dat wel zijn. Dit betekent dan
ook dat de grammatica van bijvoorbeeld alle correcte Pascal
programma's geen ambiguiteit hoeft toe te staan, terwijl een
grammatica voor bijvoorbeeld het Nederlands dat wel moet toestaan.
Een mogelijke parseerstrategie is de bottom-up strategie. Hierbij
worden aan de woorden in de zin eerst de categorielabels toegekend
(zoals in het woordenboek gedefinieerd):

Vervolgens wordt steeds geprobeerd regels toe te passen. Hierbij wordt
gekeken of de reeks symbolen rechts van de pijl in een regel
overeenkomt met een reeks symbolen in de woordenrij. In bovenstaand
voorbeeld kunnen we `lidwoord' gevolgd door `naamwoord' samen
combineren tot een naamwoordgroep. Wanneer we systematisch alle
mogelijke regels toepassen onstaan de twee parseerbomen in (4).
Verschillende parseerstrategieen kunnen worden onderverdeeld aan de
hand van een aantal criteria. Zo kan een algoritme bottom-up werken,
zoals in het voorbeeld hierboven. In dat geval worden alle
parseerbomen van beneden naar boven opgebouwd. In het omgekeerde geval
spreekt men van top-down parsing. Gecombineerde varianten zijn ook
mogelijk. Daarnaast kunnen parseeralgoritmen gekarakteriseerd worden
door te kijken in welke volgorde de woorden uit de zin in de boom
worden gehangen. Vaak gebeurt dit van links naar rechts, maar er zijn
ook varianten waarbij de input zin bidirectioneel wordt
doorlopen: sommige stukken van links naar rechts, maar andere delen
van rechts naar links. Ten slotte worden parseeralgoritmes
gekarakteriseerd aan de hand van de methode die wordt gebruikt om de
zoekruimte te doorlopen: welke regel pas je het eerst toe. Belangrijk
hierbij is ervoor te zorgen dat je al het werk slechts een keer wilt
doen.
Eén van de karakteristieke eigenschappen van natuurlijke taal is
ambiguïteit. Dit betekent dat woorden, uitdrukkingen, en zinnen
niet één vaste betekenis hebben, maar dat de betekenis afhangt van
de context. In mens-mens communicatie is ambiguïteit vrijwel
nooit een probleem: mensen zijn zo goed in het interpreteren van
natuurlijke taal dat ze vrijwel altijd de juiste betekenis aan een
uiting toekennen, vaak zelfs zonder te bemerken dat er ook nog andere
betekenissen mogelijk zijn. Voor mens-machine communicatie is
ambiguïteit evenwel een belangrijk obstakel. Om succesvol te
kunnen communiceren met een computerprogramma is het noodzakelijk dat
iedere uiting van de gebruiker wordt omgezet in een volledig
expliciete en eenduidige opdracht of mededeling voor het onderliggende
programma. Dit betekent dat een NTI de ambiguïteiten en
vaagheden die inherent zijn aan het gebruik van natuurlijke taal moet
opsporen en vervolgens elimineren.
Ambiguïteiten kunnen verschillende oorzaken hebben. Lexicale ambiguïteiten zijn ambiguïteiten die worden
veroorzaakt doordat een woord of woordgroep meerdere betekenissen
heeft. Syntactische ambiguïteiten treden op wanneer een
uiting op verschillende manieren syntactisch geanalyseerd kan worden.
Zowel lexicale als syntactische ambiguïteit leidt ertoe dat de
analyse van een zin op basis van een computationele grammatica niet
een uniek resultaat oplevert, maar dat er meerdere mogelijke analyses
zijn. Een belangrijke functie van de semantische interpretatie is om
uit de verschillende mogelijke analyses de juiste te kiezen.
Om de betekenis van een uiting volledig te bepalen is het niet
voldoende om alleen lexicale en syntactische ambiguïteiten op te
lossen. De interpretatie van veel woorden, zoals voornaamwoorden, en
uitdrukkingen als gisteren, daar, de volgende, etc, is
afhankelijk van de context waarin ze worden gebruikt.
In de rest van deze sectie bespreken we een aantal voorbeelden van
lexicale en syntactische ambiguïteit en van de rol die context
speelt bij het interpreteren van uitingen.
Veel woorden hebben meerdere betekenissen. Het woord ezel kan
verwijzen naar een dier (en naar personen die daar een zekere
overeenkomst mee vertonen) of naar een stuk schildersgereedschap.
Wanneer we een zin als De ezel stond in de wei in isolatie
proberen te interpreteren valt niet te beslissen welke betekenis bedoeld wordt.
Voorbeelden zoals hierboven, waar een woord twee volledig
verschillende betekenissen heeft, zijn relatief zeldzaam. Veel vaker
hebben woorden verschillende betekenissen die verwant
zijn. Preposities (zoals voor en op) kunnen zowel in
combinatie met een tijdsaanduiding (voor zes uur, op
zondag) als met een plaatsbepaling (voor het station, op
de Harmonie) optreden. De betekenis van de prepositie verschilt
hier weliswaar, maar het lijkt erop alsof de verschillende
betekenissen van voor en op niet helemaal ongerelateerd
zijn. De ambiguïteit van deze preposities wordt vaak helemaal
niet opgemerkt. Dit komt omdat de combinatie van een prepositie met
een tijdsuitdrukking of met een plaatsbepaling meteen duidelijk maakt
welke interpretatie nodig is. Voor een computationeel systeem leveren
deze ambiguïteiten om dezelfde reden ook weinig problemen op.
Het kan ook voorkomen dat een woord of uitdrukking maar één
betekenis heeft, maar dat deze betekenis een zekere mate van vaagheid bezit. Een uitdrukking als vandaag
verwijst bijvoorbeeld naar een periode die begint om twaalf uur 's
avonds en 24 uur later eindigt. Soms lijkt een iets ruimere
interpretatie evenwel ook mogelijk. Op de vraag Gaat er
vandaag nog een trein naar Utrecht? zou best geantwoord kunnen worden met
Om kwart over twaalf.
Sommige zinnen zijn syntactisch ambigu. Dit wil zeggen dat ze op
meerdere manieren syntactisch geanalyseerd kunnen worden. Syntactische
ambiguïteit is relevant voor de interpretatie van een
zin, omdat verschillen in syntactische analyse bijna altijd leiden tot
verschillen in betekenis. PPs zijn een beruchte bron van
syntactische ambiguïteit omdat ze zowel onderdeel van een S
als van een NP kunnen zijn. Een voorbeeld wordt
gegeven in (8-c).
![\exi.
\a. Ik neem de intercity van kwart over tien naar Enschede
\b. [s ik neem...
...]]
\c. [s ik neem [np de intercity van kwart over tien] [pp naar Enschede]]
\par](img10.png)
Iemand die van Amsterdam naar Amersfoort wil reizen kan zin ((8-c)a) uiten,
en bedoelen dat zij naar Amersfoort wil reizen met de intercity die
Enschede als eindbestemming heeft. Deze interpretatie van de zin
(waarbij de spreker dus niet van plan is pas in Enschede uit te stappen)
is mogelijk wanneer we kiezen voor de syntactische analyse in
((8-c)b). De PP naar Enschede is hier onderdeel van de
NP. Een alternatieve analyse van zin ((8-c)a) wordt gegeven
in ((8-c)c). Hier is de PP naar Enschede onderdeel
van de zin als geheel. Kiezen we voor deze analyse (waarbij de spreker zegt
dat zij naar Enschede wil reizen met de intercity van kwart over
tien), dan mogen we wel degelijk concluderen dat de spreker
Enschede als reisdoel heeft.
Voor een computationeel systeem is het erg lastig te bepalen
welke van de twee interpretaties hier bedoeld wordt. Het lijkt erop
alsof de interpretatie in ((8-c)c) in de meeste gevallen de
voorkeur verdient. Alleen wanneer uit de context duidelijk blijkt dat
de spreker niet naar Enschede wil, kiezen we voor lezing
((8-c)b). Voor een computationeel systeem betekent dit dat het
moet redeneren met behulp van informatie die eerder in de dialoog is
uitgewisseld.
De interpretatie van uitingen hangt vaak af van de context waarin ze
geuit worden. Met name de voorafgaande dialoog of discourse is
hier van belang. In figuur 1 is een voorbeeld te vinden
van een dialoog waarin verschillende uitingen voorkomen die
contextafhankelijk zijn.
Figure 1:
De interpretatie van zinnen in context
 |
In uiting 1 is de tijdsuitdrukking elf uur ambigu. Deze kan zowel
naar 11.00 uur `s ochtends uur als naar 23.00 uur `s avonds
verwijzen. Het is niet eenvoudig te bepalen welke interpretatie hier
bedoeld wordt. De interpretatie die het systeem kiest (23.00 uur) is
waarschijnlijk gebaseerd op de overweging dat er geen verbindingen
zijn waar na 11.00 uur geen treinen meer rijden (en dat dit algemeen
bekend is), maar dat er wel verbindingen zijn waar na 23.00 uur geen
trein meer gaat. Waarschijnlijk is de gebruiker dus in het laatste
geval geïnteresseerd.
Het voornaamwoord die in uiting 3 verwijst terug naar de interpretatie
van de NP een trein in uiting 2. Om dit te kunnen
vaststellen moet het systeem een lijst bijhouden van NP's die
eerder in de dialoog zijn opgetreden.
Met NP de laatste trein in uiting 4 wordt niet de
laatste trein überhaupt bedoeld, maar de laatste trein op het traject
Zwolle-Groningen. Deze interpretatie is gebaseerd op het feit dat de
gebruiker begon met een vraag naar dit traject. Merk op dat het
systeem ook had kunnen kiezen voor de interpretatie laatste trein op het traject Zwolle-Groningen die stopt in
Haren. Het woordje laatste betekent hier trouwens laatste in de
NS-dienstregeling en bijvoorbeeld niet laatste vandaag
(d.w.z. de laatste die voor 24.00 uur vertrekt).
Merk tenslotte op dat ogenschijnlijk kleine verschillen in de manier waarop iets
gezegd wordt de interpretatie kunnen veranderen. Wanneer in uiting 1 het
woordje nog ontbreekt, dan is al iets minder duidelijk dat 23.00 uur
's avonds bedoeld wordt. Is de vraag geformuleerd als wanneer gaat
er na elf uur een trein van Zwolle naar Groningen dan is zonder
verdere context niet te beslissen of 11.00 uur dan wel 23.00 uur
bedoeld wordt.
Om de dialoog tussen gebruiker en machine enigszins soepel te laten
verlopen is het nodig dat het systeem een zekere mate van initiatief
vertoont en `coöperatief' is. Met dit laatste bedoelen we dat het
systeem misverstanden aan de kant van de gebruiker probeert te
voorkomen, en dat het systeem probeert om antwoorden te geven die
informatief zijn, zelfs als een korter antwoord zou hebben volstaan.
Het voorbeeld in figuur 1 illustreert hoe belangrijk het
is dat een dialoogsysteem zich coöperatief gedraagt en in staat is
tot het nemen van initiatieven.
De dialoog begint bijvoorbeeld met een
ja/nee vraag van de kant van de gebruiker. Het zou uiterst
oncoöperatief zijn wanneer het systeem hierop alleen met ja
zou hebben geantwoord. Het systeem neemt dan ook terecht het
initiatief om nog enige extra informatie te verstrekken. In de eerste
plaats bevat het antwoord de tijdsuitdrukking vandaag. Op deze
manier maakt het systeem duidelijk dat het bij het beantwoorden van de
vraag een assumptie heeft gemaakt (namelijk dat de gebruiker
informeert naar de dienstregeling van vandaag), die niet expliciet in
de vraag aanwezig was. Door het expliciet maken van zulke assumpties
worden misverstanden voorkomen.
Daarnaast wordt de vertrektijd van een trein die na 23.00 uur vertrekt
gegeven. Het systeem had in principe nog meer informatie kunnen
geven (zoals de aankomsttijd van de genoemde trein of de vertrektijden
van andere treinen op dit traject die na 23.00 ur vertrekken). Hier is
het belangrijk een afweging te maken tussen het geven van informatie
die misschien ook relevant is en het vermijden van het geven van
informatie waarom de gebruiker niet gevraagd heeft.
Ook op de tweede en derde vraag van de gebruiker wordt steeds
geantwoord met meer informatie dan waarom strikt genomen wordt
gevraagd.
De laatste vraag van de gebruiker is een vraag naar een busverbinding. Een
oncoöperatief systeem had hier domweg nee kunnen antwoorden
(omdat er geen (spoor-) verbinding van Groningen naar Zoutkamp
is). Dit zou echter misleidend zijn. Uit het feit dat er geen
verbinding kan worden gevonden, kan worden afgeleid dat Zoutkamp geen
NS-station is. Door dit in het antwoord te vermelden kan een
misverstand bij de gebruiker (die er misschien van uitgaat dat Zoutkamp wel per
spoor te bereiken is, of dat het systeem ook busverbindingen kent)
gecorrigeerd worden.
Normaal gesproken wordt bij het onderzoek naar het automatisch
genereren van natuurlijke taal een onderscheid gemaakt tussen twee
verschillende componenten: een component die bepaalt wat er
gezegd moet worden, en een component die bepaalt hoe dit gezegd
moet worden. In het geval van taalgeneratie als component van een
natuurlijke-taalinterface is de eerste component meestal onderdeel van
de component die zorgt voor de dialoogvoering en het raadplegen van de
database. Het is vaak zo dat deze ``dialoogvoerder'' een
betekenisrepresentatie oplevert waarvoor de taalgeneratiemodule dan
een bijbehorende zin moet opleveren. We houden ons hier dus alleen
bezig met de hoe component.
In bepaalde opzichten is taalgeneratie het omgekeerde van
syntactische en semantische analyse. Bij analyse is de opdracht voor
een gegeven zin de relevante betekenisrepresentatie op te leveren; bij
generatie is de betekenisrepresentatie al gegeven, maar moet de
bijbehorende zin worden teruggevonden. Deze symmetrie leidt ertoe dat
soms wel geprobeerd wordt de generatiecomponent gebruik te laten maken
van dezelfde grammatica als de analysecomponenten. In dat geval noemt
men de grammatica omkeerbaar of reversibel, omdat de
grammatica immers in twee richtingen kan worden gebruikt.
Net als bij de syntactische analyse bestaan er vele verschillende
generatie algoritmes. En net als bij syntactische analyse kunnen we
deze algoritmes karakteriseren aan de hand van:
- top-down of bottom-up
- van links naar rechts of bidirectioneel
- gebruikte zoekmethode
Een eenvoudige top-down generatieprocedure werkt bijvoorbeeld als
volgt. Om deze procedure uit te leggen nemen we even aan dat in elke
syntactische regel de categorieën een bijbehorende semantische
waarde hebben. Om een zin met een bepaalde semantiek Sem te
produceren zoeken we een regel die aan de linkerkant van de pijl de
categorie zin/Sem heeft. Vervolgens moeten we dan voor de
categorieen rechts van de pijl dezelfde procedure recursief toepassen.
Dit doen we net zolang we alleen woorden overhouden: de zin. Het
volgende figuurtje illustreert de procedure:
doel: zin/slaan(ik,maarten23)
regel: zin/Pred(Arg1,Arg2) --> onderwerp/Arg1, gezegde/Pred(Arg2)
doel: onderwerp/ik gezegde/slaan(maarten23)
regel: onderwerp/Sem --> naamwoordgroep/Sem
doel: naamwoordgroep/ik gezegde/slaan(maarten23)
regel: naamwoordgroep/ik --> ik
doel: ik gezegde/slaan(maarten23)
regel: gezegde/Pred(Arg2) --> werkwoord/Pred, lijdend_voorwerp/Arg2
doel: ik werkwoord/slaan, lijdend_voorwerp/maarten23
regel: werkwoord/slaan --> sloeg
doel: ik sloeg lijdend_voorwerp/maarten23
regel: lijdend_voorwerp/Sem --> naamwoordgroep/Sem
doel: ik sloeg naamwoordgroep/maarten23
regel: naamwoordgroep/maarten23 --> Maarten 't Hart
doel: ik sloeg Maarten 't Hart
Er zijn ook belangrijke verschillen tussen analyse en
generatie. Bij analyse is een belangrijk probleem om ambiguiteiten op
te lossen. Bij generatie hebben we dit probleem natuurlijk niet. Wel
is het soms zo dat meerdere mogelijke zinnen voor een gegeven
semantische structuur mogelijk zijn. In dat geval bestaat er een
vergelijkbaar probleem omdat we dan de meest geschikte zin willen
genereren. Om te bepalen wat de meest geschikte zin is kunnen we een
aantal criteria gebruiken. Het is bijvoorbeeld mogelijk om te proberen
ambigue zinnen te vermijden. Die zouden immers gemakkelijk tot
misverstanden bij de luisteraar kunnen leiden. Daarnaast kun je je
voorstellen dat je wellicht de eenvoudigste zin wilt gebruiken.
Het probleem van robuustheid dat wel bestaat bij analyse heb je niet
bij generatie. De reden hiervoor is dat je bij analyse de input niet
in de hand hebt (je weet ten slotte nooit wat de spreker zal gaan
zeggen). Bij generatie heb je wel invloed op de input: die wordt
immers door het systeem zelf gemaakt.
Vanwege de afwezigheid van de ambiguiteits- en
robuustheidsproblematiek kun je de generatiecomponent beschouwen als
een eenvoudigere component dan de analysecomponent.
Niet ieder computerprogramma kan worden voorzien van een natuurlijke
taalinterface, en niet ieder programma zal baat hebben bij een
dergelijke interface.
Het ontwikkelen van een NTI valt te overwegen wanneer aan
één of meer van de volgende criteria wordt voldaan:
- 1.
- De gebruikers van het systeem zijn niet gewend te werken met
commando-talen of andere vormen van mens-machine interactie.
- 2.
- Interactie met het systeem vereist de beheersing van een groot
aantal commando's.
- 3.
- Alternatieve vormen van mens-machine interactie zijn niet toepasbaar.
- 4.
- Het geven van uitleg is belangrijk.
- 5.
- Het systeem moet soms een (lange) dialoog met de gebruiker
voeren.
De eerste twee criteria zijn vaak doorslaggevend bij de
ontwikkeling van een NTI voor databases die door een grote groep
(niet-specialistische) gebruikers bediend moeten kunnen worden.
Het derde criterium is bijvoorbeeld doorslaggevend voor systemen die
dia via de telefoon geraadpleegd moeten kunnen worden en voor systemen
die bijvoorbeeld in auto's ingebouwd worden (zoals navigatiesystemen).
De laatste twee criteria spelen vooral een rol bij kennis- en
expertsystemen. Het geven van uitleg en advies, en het voeren van
lange dialogen (bijvoorbeeld om een diagnose te stellen of een
probleem op te lossen) is hier essentieel. Natuurlijke taal is hier de
meest voor de hand liggende vorm van interactie.
Het ontwikkelen van een NTI is in de meeste gevallen een
kostbaar en moeizaam proces. Het ontwikkelen van een systeem dat alle
aspecten van het voeren van een dialoog in natuurlijke taal goed
beheerst, en dat gebruik maakt van de technieken die hiervoor zijn
besproken kost zeker vele manjaren. Bovendien zijn garanties voor
succes moeijlijk te geven.
Om dit probleem op te lossen wordt in veel projecten de nadruk gelegd
op het feit dat men niet een NTI voor één bepaalde
applicatie ontwikkeld, maar een algemeen systeem voor het
voeren van dialogen in natuurlijke taal. In het ideale geval kan dit
systeem gebruikt en hergebruikt worden als interface voor
verschillende applicaties. Het aanpassen van een NTI voor een
nieuwe applicatie vereist in dit geval voornamelijk een investering in
het aanpassen van de taalmodule aan het domein van de applicatie en in
het aanpassen van de module die verantwoordelijk is voor de
communicatie tussen de NTI en de eigenlijke applicatie.
Daarnaast zijn veel NTI's een compromis tussen datgene wat
idealiter vereist wordt van een NTI en datgene wat practisch
haalbaar is. Sommige systemen hebben bijvoorbeeld geen of een zeer
beperkt besef van context en dialoog, en interpreteren iedere vraag dus
apart.
Daarnaast is de syntaxis van sommige systemen erg beperkt. Dit
betekent dat een gebruiker alleen de meest eenvoudige en voor de hand
liggende zinsconstructies kan gebruiken. Een nadeel van deze aanpak is
dat de gebruiker soms eerst moet leren welke zinnen wel en niet
geaccepteerd worden. Een belangrijk voordeel van NTI's, namelijk
dat ze door gebruikers zonder speciale voorkennis toegankelijk zijn, gaat dan verloren.
Veel systemen vermijden ook het volledig syntactisch en
semantisch analyseren van de input van de gebruiker, en volstaan met
een ruwe analyse van de input, waarbij vooral gelet wordt op
zogenaamde keywords die belangrijk zijn voor de
applicatie. De vraag wanneer gaat er een trein van Groningen naar
Zwolle bevat bijvoorbeeld de keywords van en naar. De stations die hierna volgen zijn ongetwijfeld de vertrek-
en aankomststations die de gebruiker in gedachten heeft. Door alleen deze
informatie uit een vraag van de gebruiker te destilleren kan het
systeem achterhalen waarnaar ongeveer gevraagd wordt. Soms volstaat
dit voor het geven van het juiste antwoord. Het voordeel van deze
aanpak is dat de gebruiker veel vrijheid heeft bij het formuleren
van een vraag. Het nadeel is dat veel van de informatie in de input
verloren gaat. Het voeren van langere dialogen, waarbij het systeem
gebruik maakt van contextuele informatie, is met behulp van deze
techniek dan ook erg moeilijk.
Natuurlijke-taalinterfaces
This document was generated using the
LaTeX2HTML translator Version 98.2 beta6 (August 14th, 1998)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 2 nli.tex
The translation was initiated by Noord G.J.M. van on 1998-09-29
Noord G.J.M. van
1998-09-29