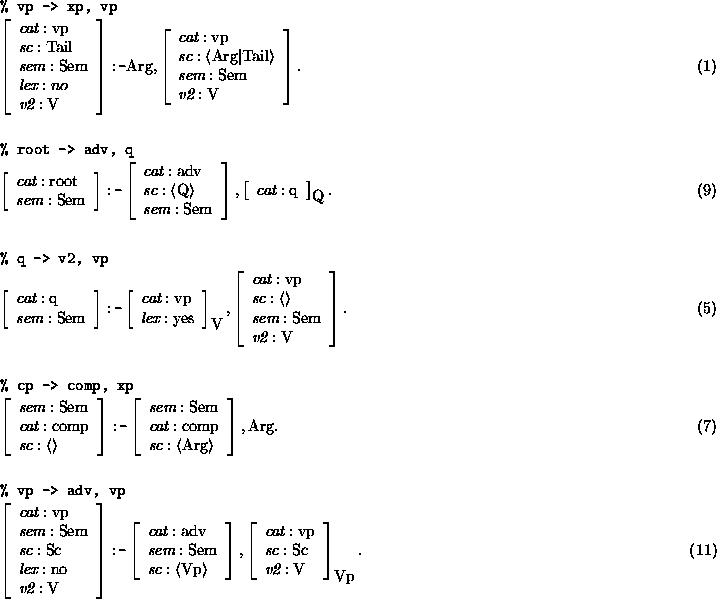
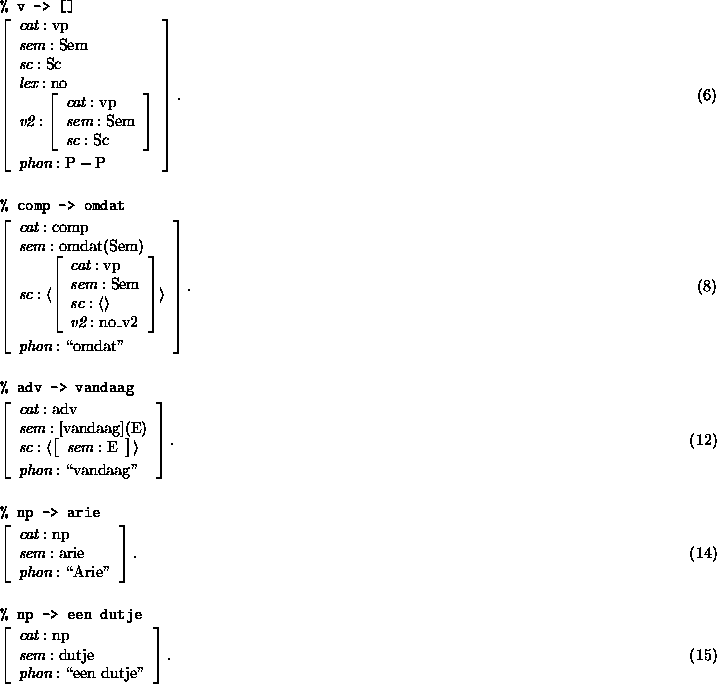
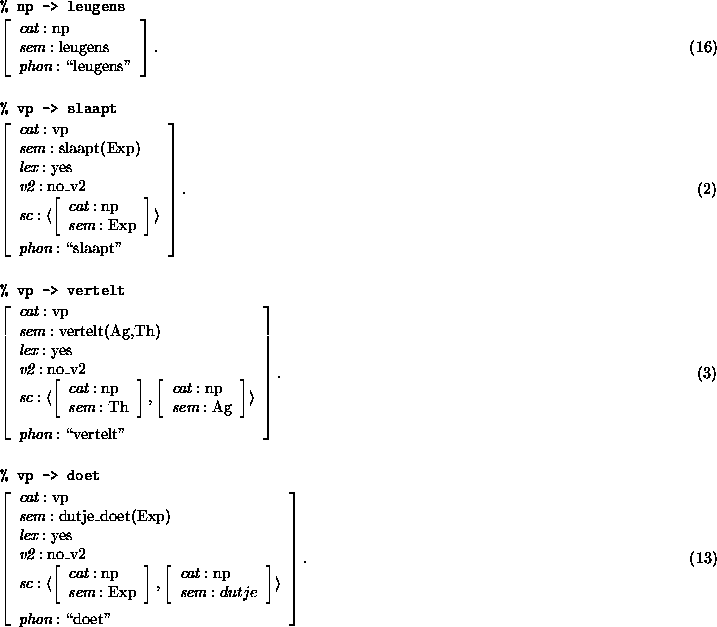
To illustrate the different generation techniques, which I discuss in the following sections, I will first define a simple, but in some respects typical, grammar for a small subset of Dutch.
I assume in this grammar that all strings are built using a difference-list implementation of concatenation as in concatenative formalisms. Therefore, each binary rule extends the following:
![]()
To make the rules somewhat easier to read, I will not explicitly
mention these constraints in the rules -- however for each rule they
are present.
Lexical entries will generally specify their phonology as follows, where the variable Word is instantiated by some constant representing the terminal symbol associated with that lexical entry:
![]()
Note though that none of the conclusions of this chapter in any way depends on the restriction to assume such a concatenative base. In the next chapter I discuss other ways to combine strings -- the generation algorithms discussed here are all capable of handling such more powerful rules. In fact, some of the problems I will encounter for generation, can be solved in grammars in which concatenation is not the sole operation to construct phonological structures.

The value
of the subcat feature (the label
sc) is a list of signs. In
this rule, the first element of the subcat list of the second daughter
of the rule, is equated with the first daughter of the rule. The
`remaining' elements on the list, i.e. the tail of the list is
`percolated' to the mother node of the rule. If a verb selects several
arguments then this
vp rule can be applied iteratively. The
following example clarifies this technique. Assume that some verb
subcategorizes for four elements, called a, b, c and d.
Then the parse tree for the saturated verb phrase dominating this
verb, looks as in figure 3.1. The elements of this list are
selected by a binary verb-phrase rule, one at the time. If selection
is to the left, then the order of the elements on the list mirrors the
order of the elements found in the string.Thus, the elements of the
subcat list are selected one at the time. Note that in the case where
elements are selected to the left of the head, the order of the
elements on the subcat list is the reverse of the order of the actual
elements in the string. Furthermore note that if a sign is saturated,
then its subcat list is empty.
Furthermore, it is stated in this rule, that the semantics of the second daughter is identical with the semantics of the mother of the node. In the current grammar, semantic structures will invariably be built lexically; these structures are always unified between the semantic-head and the mother of a rule. Thus, the semantic-head, or `functor', of a rule is that daughter, which shares its semantics with the semantics of the mother node of the rule. This daughter not necessarily is the `syntactic-head' of the phrase. For example, modifiers often are analyzed as the semantic-head of the construction they modify, whereas the modified part of the construction is the syntactic head.
The semantics of a lexical entry is defined by sharings with the semantics of the elements it subcategorizes for. Some verbs are defined as in rule 2. In these entries it should be noted how semantic structures are defined by sharings with parts of the elements on the subcat list. Therefore, if such verbs are selected by the VP rule above, the semantics is gradually instantiated, when the arguments are selected. Note that this mechanism is essentially the mechanism assumed in UCG [113]; see also [58], and [61] for discussion.
In Dutch, the finite verb occupies the second position of a main clause, whereas in subordinate clauses it occupies the final position. Thus we have:

In order to be able to use the same verb phrase rules in both subordinate and main clauses, I will define a threading implementation of a `movement' analysis of verb second. This analysis uses the features v2 and lex, already mentioned in the foregoing rule 1. I assume that in main clauses the finite verb also occupies the final position, but in a phonologically empty way. Furthermore the information of this empty verb is then percolated through the v2 feature to the pre-VP position. The basic idea of this analysis is illustrated in figure 3.2. The information of the initial finite verb is percolated downwards to a phonologically empty verb, in the position of the finite verb in subordinate sentences.
Furthermore, categories of type q (for `question' -- the rest of the root sentence has a yes-no question word-ordering) consist of a finite verb and a saturated verb phrase that misses this verb. This is how the current grammar deals with verb second. The rule is defined in 5.

In this rule the binary feature
lex is used to implement the
fact that only verbs, and not verb phrases, can be fronted to the
verb-second position. The information of the verb in verb second
position is percolated through the
v2 feature. Furthermore,
there is the option that a verb in Dutch can be `empty', in case the
features in its `incoming'
v2 feature unify with its own
features, cf. rule 6.
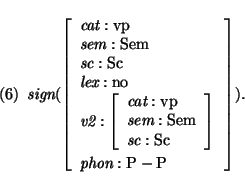
In case a verb phrase should not dominate this empty verb, the grammar
instantiates the
v2 feature with some constant, for example
the value
![]() .
The grammar rule in rule 7 defines
that a complementizer phrase consists of a complementizer and the
argument for which this complementizer subcategorizes.
.
The grammar rule in rule 7 defines
that a complementizer phrase consists of a complementizer and the
argument for which this complementizer subcategorizes.

Such a complementizer `omdat' (the Dutch equivalent of `because') is
defined in rule 8, where it should be noted that this
complementizer requires that the verb phrase should not dominate the
empty verb, by specifying the value of the
v2 attribute.
Furthermore note that the complementizer requires that the embedded
verb phrase should be `saturated', i.e. should have selected its
arguments, because it requires that the value of the
sc attribute
of the verb phrase for which it subcategorizes, is the empty list. This
is a way to implement LFG's completeness requirement [10]
on subcategorization specifications. In general, lexical entries
require that the subcat lists of their arguments are empty.
![\pr
\pred\head{
\mbox{\it sign}(\avm{\mbox{\it cat}: \mbox{\rm root}\\ \mbox{\it...
...\mbox{\it sign}(\avm[\mbox{\rm Q}]{\mbox{\it cat}: \mbox{\rm q}} ).}
\epred\epr](img194.png)
Note that the position of this adverbial is usually analyzed as the
topic position. The current simplification is motivated, because for
the expository purposes of the grammar, it is not necessary to
implement a gap-threading analysis of topicalization.
The grammar also allows some simple modification of verb phrases. Verb phrases may consist of an adverbial phrase followed by a verb phrase. The subcat list of the verb phrases is percolated, because in Dutch, unlike in English, adverbials can be interspersed with the arguments of the verbs:

Note that such sentences motivate the use of the binary verb phrase rule 1, giving rise to branching verb phrases, rather than flat verb phrases as in HPSG. Rule 11 defines that a verb-phrase may consist of an adverbial and a verb phrase.

Such an adverbial might for example be defined such as the following
entry of `vandaag' (today) in rule 12.
We will not be very much interested in noun phrases; therefore I simply assume some noun phrases that are defined as in the following example for `Arie', `een dutje' (`a nap') and `leugens' (`lies'):



This second noun phrase will be used to construct the idiomatic verb phrase
`een dutje doen' which means `to take a nap'.
A suitable parser for this simple grammar returns for the call
![]()
the following constraint on
X0:
![\begin{displaymath}\avm[{\mbox{\rm X}_{0}}]{
\mbox{\it cat}: comp\\
\mbox{\it ...
...\
\mbox{\it phon}: \mbox{\lq\lq omdat arie leugens vertelt''} \\
}\end{displaymath}](img203.png)
The resulting grammar is given in the figures 3.3, 3.4 and 3.5. Note that I left out the relation symbols `sign' for short.
![\begin{figure}
\begin{center}
\leavevmode
\unitlength1pt
\beginpicture
\setplot...
...booml { d,c,b,a} }} [Bl] at 83.46 18.00
\endpicture
\end{center}\par\end{figure}](img184.png)


![\begin{figure}
\begin{center}
\leavevmode
\unitlength1pt
\beginpicture
\setplot...
...x{$\epsilon $}} [Bl] at 51.02 18.00
\endpicture
\par\end{center}\par\end{figure}](img188.png)