The prediction step, as it is defined in BUG, only uses semantic information. However, it is possible to extend the prediction step to take into account syntactic information as well. This is especially useful for grammars that define words that are semantically empty. For example, assume our Dutch grammar is extended with the complementizer dat (that) as defined in 22.

In this entry, the semantics of the embedded verb phrase is simply
`taken over' as the semantics of the complementizer, and hence of the
complementizer phrase headed by `dat'. Such lexical entries will be
candidates for each invocation of the prediction step, because they
are completely ignorant as to what semantics they may end up with.
This leads to gross efficiency problems as has been observed in
practice.
Suppose, however, that the prediction step is augmented with syntactic information. If the goal is to generate a verb phrase, then it is obvious from the grammar, that it is useless to predict a complementizer at that point, because the only results of connecting a complementizer upwards will be a complementizer phrase. Assume that the predicate link(Moth,Head) is a pre-compiled table of the reflexive and transitive closure of possible syntactic links between mothers and heads, similar to the link predicate in the BUP parser [55] between mothers and left-most daughters. For the example grammar of this chapter, the predicate can be defined as follows, if we restrict the link table, to take into account only the value of the attribute cat:
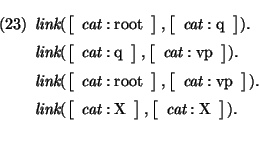
It is possible to change the definition of predict_head and
select_rule into the definitions given in 24.

Note that we change the select_rule clause to take four
arguments now. The fourth argument is the top goal (i.e. the second
argument of the sem_head clauses).
In fact, the prediction step does not necessarily have to be restricted to semantic and syntactic information, as long as it is possible to pre-compile the reflexive and transitive closure of the relation between heads and mothers. The `restrictor' technique discussed by [82] can be used here. Note though that the semantic information should not be `restricted'. Syntactic prediction limits the choice of possible lexical entries. The semantic prediction has a further task in instantiating the semantics of the lexical entry to ensure that recursive generation calls also have their semantics specified. This difference is the reason to differentiate in the foregoing definition of predict_head between the semantic prediction and the syntactic prediction.
The syntactic linking technique has a problem in that it may produce spurious ambiguities. For example, consider the following part of a hypothetical syntactic linking table:
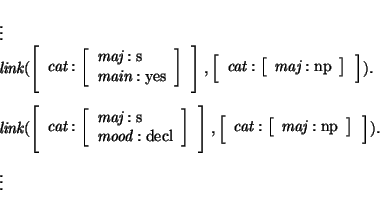
Assume a goal is specified for category
s, and the current
category, that needs to be connected to that goal, is
np.
In that case both clauses are applicable.
However, these two clauses do not necessarily correspond to two
distinct results. In a Prolog implementation this problem may be
solved by a `double negation' trick; i.e. we would write something
like:
where \+ is the negation-as-failure operator. The linking
predicate then reduces to a check that does not introduce new
information, but only filters the application of rules and lexical
entries that cannot be linked to the goal (for that reason the
predicate should be called immediately after the predicates
ncr and
cr, rather than before.).
Doubly negating the semantic prediction step would, of course,
be damaging, because the main task of the semantic prediction is
to further instantiate (the semantics of) the predicted lexical
entries.
Another possibility, to prevent spurious ambiguities of the syntactic linking device, would be to compute the generalization of all possible answers every time the `link' predicate is called. In the previous example this would simply result in neglecting the main and mood attributes. In general such a solution requires quite a bit of overhead. For different grammars different answers will be possible to the question what the most efficient solution is.