This section evaluates the NLP component with respect to efficiency and accuracy.
We present a number of results to indicate how well the NLP component currently performs. We used a corpus of more than 20K word-graphs, output of a preliminary version of the speech recognizer, and typical of the intended application. The first 3800 word-graphs of this set are semantically annotated. This set is used in the experiments below. Some characteristics of this test set are given in Table 1. As can be seen from this table, this test set is considerably easier than the rest of this set. For this reason, we also present results (where applicable) for a set of 5000 arbitrarily selected word-graphs. At the time of the experiment, no further annotated corpus material was available to us.
|
We report on two different experiments. In the first experiment, the parser is given the utterance as it was actually spoken (to simulate a situation in which speech recognition is perfect). In the second experiment, the parser takes the full word-graph as its input. The results are then passed on to the robustness component. We report on a version of the robustness component which incorporates bigram-scores (other versions are substantially faster).
All experiments were performed on a HP-UX 9000/780 machine with more than enough core memory. Timings measure CPU-time and should be independent of the load on the machine. The timings include all phases of the NLP component (including lexical lookup, syntactic and semantic analysis, robustness, and the compilation of semantic representations into updates). The parser is a head-corner parser implemented (in SICStus Prolog) with selective memoization and goal-weakening as described in [10]. Table 2 summarizes the results of these two experiments.
|
From the experiments we can conclude that almost all input word-graphs can be treated fast enough for practical applications. In fact, we have found that the few word-graphs which cannot be treated efficiently almost exclusively represent cases where speech recognition completely fails and no useful combinations of edges can be found in the word-graph. As a result, ignoring these few cases does not seem to result in a degradation of practical system performance.
In order to evaluate the accuracy of the NLP component, we used the same test set of 3800 word-graphs. For each of these graphs we know the corresponding actual utterances and the update as assigned by the annotators. We report on word and sentence accuracy, which is an indication of how well we are able to choose the best path from the given word-graph, and on concept accuracy, which indicates how often the analyses are correct.
The string comparison on which sentence accuracy and word accuracy are
based is defined by the minimal number of substitutions, deletions and
insertions that is required to turn the first string into the second
(Levenshtein distance). The string that is being compared
with the actual utterance is defined as the best path through the
word-graph, given the best-first search procedure defined in the
previous section. Word accuracy is defined as
1 - ![]() where n is the length of the actual utterance
and d is the distance as defined above.
where n is the length of the actual utterance
and d is the distance as defined above.
In order to characterize the test sets somewhat further, Table 3 lists the word and sentence accuracy both of the best path through the word-graph (using acoustic scores only), the best possible path through the word-graph, and a combination of the acoustic score and a bigram language model. The first two of these can be seen as natural upper and lower boundaries.
|
Word accuracy provides a measure for the extent to which linguistic processing contributes to speech recognition. However, since the main task of the linguistic component is to analyze utterances semantically, an equally important measure is concept accuracy, i.e. the extent to which semantic analysis corresponds with the meaning of the utterance that was actually produced by the user.
For determining concept accuracy, we have used a semantically annotated corpus of 3800 user responses. Each user response was annotated with an update representing the meaning of the utterance that was actually spoken. The annotations were made by our project partners in Amsterdam, in accordance with the guidelines given in [11].
Updates take the form described in Section 3. An update is a logical formula which can be evaluated against an information state and which gives rise to a new, updated information state. The most straightforward method for evaluating concept accuracy in this setting is to compare (the normal form of) the update produced by the grammar with (the normal form of) the annotated update. A major obstacle for this approach, however, is the fact that very fine-grained semantic distinctions can be made in the update-language. While these distinctions are relevant semantically (i.e. in certain cases they may lead to slightly different updates of an information state), they often can be ignored by a dialogue manager. For instance, the update below is semantically not equivalent to the one given in Section 3, as the ground-focus distinction is slightly different.
userwants.travel.destination.place
([# town.leiden];
[! town.abcoude])
However, the dialogue manager will decide in both cases that this is a correction of the destination town.
Since semantic analysis is the input for the dialogue manager, we have
therefore measured concept accuracy in terms of a simplified version
of the update language. Following the proposal in [4], we
translate each update into a set of semantic units, were a unit
in our case is a triple ![]() CommunicativeFunction, Slot,
Value
CommunicativeFunction, Slot,
Value![]() . For instance, the example above, as well as the
example in Section 3, translates as
. For instance, the example above, as well as the
example in Section 3, translates as
![]() denial, destination_town, leiden
denial, destination_town, leiden ![]()
![]() correction, destination_town, abcoude
correction, destination_town, abcoude ![]()
Both the updates in the annotated corpus and the updates produced by the system were translated into semantic units of the form given above.
Semantic accuracy is given in the following tables according to four different definitions. Firstly, we list the proportion of utterances for which the corresponding semantic units exactly match the semantic units of the annotation (match). Furthermore we calculate precision (the number of correct semantic units divided by the number of semantic units which were produced) and recall (the number of correct semantic units divided by the number of semantic units of the annotation). Finally, following [4], we also present concept accuracy as
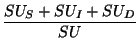
where SU is the total number of semantic units in the translated corpus annotation, and SUS, SUI, and SUD are the number of substitutions, insertions, and deletions that are necessary to make the translated grammar update equivalent to the translation of the corpus update.
We obtained the results given in Table 4.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The following reservations should be made with respect to the numbers given above.
Even if we take into account these reservations, it seems that we can conclude that the robustness component adequately extracts useful information even in cases where no full parse is possible: concept accuracy is (luckily) much higher than sentence accuracy.