In unification-based grammar formalisms, linguistic information is represented by means of typed feature-structures. Each word or phrase in the grammar is associated with such a feature-structure, in which syntactic and semantic information is bundled. Within Head-driven Phrase Structure Grammar (HPSG), such feature-structures are called signs, a terminology which we will follow here.
At present, the grammar makes use of 15 different types of sign, where each type roughly corresponds to a different category in traditional linguistic terminology. For each type of sign, a number of features are defined. For example, for the type NP, the features AGR, NFORM, CASE, and SEM are defined. These features are used to encode the agreement properties of an NP, (morphological) form, case and semantics, respectively. A more detailed presentation of these features follows below.
There are a number of features which occur in most types of sign, and which play a special role in the grammar. The feature SC (SUBCATEGORISATION) (present on signs of type v, sbar, det, a, n and p), for instance, is a feature whose value is a list of signs. It represents the subcategorisation properties of a given sign. As will be explained below, it is used to implement rules which perform functor-argument application (as in Categorial Grammar).
The feature SLASH is present on v, ques and sbar. Its value is a list of signs. It is used to implement a (restricted) version of the account of nonlocal dependencies proposed in Pollard and Sag [36] and Sag [38]. The value of SLASH is the list of signs which are `missing' from a given constituent. Such a `missing' element is typically connected to a preposed element in a topicalisation sentence or WH-question. The same mechanism can also be used for relative clauses.
The feature VSLASH is similar to SLASH in that it records the presence of a missing element, a verb in this case. It is used to implement an account of Dutch main clauses, based on the idea that main clauses are structurally similar to subordinate clauses, except for the fact that the finite verb occurs as first or second constituent within the clause and the clause final position where finite verbs occur in subordinate clauses is occupied by an empty verbal sign (i.e. an element which is not visible in the phonological or orthographic representation of the sentence).
The feature SEM is present on all signs. It is used to encode the semantics of a word or phrase, encoded as a quasi logical form [3]. The feature MOD is present on the types a, pp, p, adv, sbar and modifier. It is used to account for the semantics of modifiers. Its value is a list of quasi-logical forms. In the sections below on syntax, we only give an informal impression of the semantics. The details of the semantic construction rules and principles are dealt with in section 2.5.
An important restriction imposed by the grammar-parser interface is that each rule must specify the category of its mother and daughters. A consequence of this requirement is that general rule-schemata, as used in Categorial Grammar and HPSG cannot be used in the OVIS2 grammar. A rule which specifies that a head daughter may combine with a complement daughter, if this complement unifies with the first element on SC of the head (i.e. a version of the categorial rule for functor-argument application) cannot be implemented directly, as it leaves the categories of the daughters and mother unspecified. Nevertheless, generalisations of this type do play a role in the grammar. We adopt an architecture for grammar rules similar to that of HPSG, in which individual rules are classified in various structures, which are in turn defined in terms of general principles.
Rules normally introduce a structure in which one of the daughters can be identified as the head. The head daughter either subcategorises for the other (complement) daughters or else is modified by the other (modifier) daughters.
The two most common structures are the head-complement and head-modifier structure.1 In figure 1 we list the definitions for these structures and the principles they refer to, except for the filler principle, which is presented in the section on topicalisation.
Head-complement and head-modifier structures are instances of headed structures. The definition of headed structure refers to the HEAD-FEATURE, VALENCE, and FILLER principles, and furthermore fixes the semantic head of a phrase. Note that the definition of hd-struct has a number of parameters. The idea is that a headed structure will generally consist of a head daughter, and furthermore of zero or more complement daughters and possibly a modifier. Head-complement and head-modifier structures differ from each other only in that the first introduces complements, but no modifiers, whereas the second introduces no complements, but a modifier. Moreover, the syntactic head is also the semantic head in head-complement structures, but not in a head-modifier structure. In head-modifier structures, the semantic contribution of the head to the meaning of the phrase as a whole is handled by unifying the head semantics with the value of (the first element of) MOD on the modifier.
The HEAD FEATURE PRINCIPLE states for a number of features (the head-features) that their value on the head daughter and mother must be unified. As this principle generalises over various types of sign, its definition requires the predicate unify_ifdef.
The VALENCE PRINCIPLE determines the value of the valence feature SC. The value of SC on the head daughter of a rule is the concatenation ( append) of the list of complement daughters and the value of SC on the mother. Another way to put this is that the value of SC on the mother is the value of SC on the head daughter minus the elements on SC that correspond to the complement daughters. Note that the formulation of the VALENCE PRINCIPLE is complicated by the fact that SC (or SUBJ) may sometimes not be defined on the mother. In that case, it is assumed that the value of SC on the head daughter must correspond exactly to the list of complement daughters. The constraint ifdef(sc,Mother,MotherSc,[]) states that the value of SC on Mother unifies with MotherSc, if SC is defined for the type of Mother. Otherwise, MotherSc is assigned the value [] (i.e. the empty list).
The structures defined in figure 1 are used in the
definition of grammar rules. The np-det-n rule introduces a
head-complement structure in which (following the traditional semantic
analysis) the determiner is the head, and
the noun the complement:
Note
that for a given rule, the types of the mother and daughters must be
specified, and furthermore, the number of complements is always
specified. This implies that the constraints in the principles in
figure 1 can be reduced to a number of basic
constraints on the values of particular features defined for the signs
in the rule. The previous two rules
can be depicted in matrix notation as (where
![]() denotes
the empty list):
denotes
the empty list):
![\begin{displaymath}\small\begin{minipage}[t]{.9\textwidth}\begin{avm}
{\tt np\_d...
...\ sem & \@2 \end{displaymath}~~~
\@3 n
\end{avm}\end{minipage}\end{displaymath}](img12.gif) |
(8) |
![\begin{displaymath}\small\begin{minipage}[t]{.9\textwidth}\begin{avm}
{\tt n\_ad...
...agr & \@2 \\ sem & \@4 \end{displaymath}\end{avm}\end{minipage}\end{displaymath}](img13.gif) |
(9) |
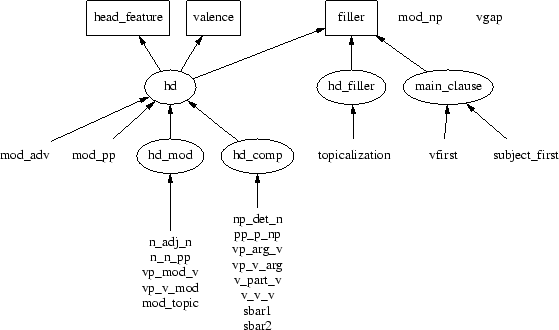
An overview of all grammar rules defined in the fragment at the moment, together with the structures and principles from which they inherit, is given in figure 2.
 |
The classification of rules into structures, which are in turn defined in terms of principles, allows us to state complicated rules succinctly and to express a number of generalizations. Nevertheless, it is also clear that the rules could have been more general, if rule schemata (in which the type of the daughters, or even the number of daughters is not necessarily specified) had been allowed. Given this restriction, one may even wonder whether the VALENCE PRINCIPLE (and the feature SC that comes with it) cannot be eliminated in favour of more specific rules. Valence features are particularly important for grammars employing rule schemata, but they are much less crucial for more traditional types of grammar. Although eliminating valence features is not impossible in principle, we believe that the present set-up still has advantages, although these are less apparent than in grammars which make use of rule schemata. Expressing valence information lexically, instead of using more detailed syntactic rules, has the advantage that idiosyncratic subcategorization requirements (such as the restriction that denken ( to think) requires a PP-complement headed by aan ( about), or the fact that komen ( to come) may combine with the particle aan (the combination of which means to arrive)) need not be stated in the rules. Similarly, all constraints having to do with case marking and agreement can be expressed lexically, as well as the semantic relation between a head and its dependents.
![\begin{figure}
\begin{verbatim}hd_comp_struct(Head,Complements,Mother) :-
hd_...
...her,MotherSc,[]),
append(Complements,MotherSc,HeadSc)\end{verbatim}\end{figure}](img8.gif)
![\begin{displaymath}
\small\begin{minipage}[t]{.9\textwidth}\begin{verbatim}rul...
...> norm, hd_comp_struct(Det,[N],NP).\end{verbatim}\end{minipage}\end{displaymath}](img9.gif)
![\begin{displaymath}
\small\begin{minipage}[t]{.9\textwidth}\begin{verbatim}rul...
... N0:agr, hd_mod_struct(N0,AdjP,N1).\end{verbatim}\end{minipage}\end{displaymath}](img10.gif)