


Volgende: 3. Evaluatie
Naar boven: De positie van het
Vorige: 1. Inleiding en Uitgangspunten
Subsecties
In dit hoofdstuk schetsen we de huidige infrastructuur voor taal- en
spraaktechnologie. We geven achtereenvolgens een overzicht van bestaande
dataverzamelingen en hulpmiddelen voor het Nederlands, een kort
overzicht van vergelijkbare materialen voor het Engels, van onderzoeks- en
onderwijsinstellingen, van beleidsinstellingen, en van buitenlandse
organisaties voor taal- en spraaktechnologie.
In deze sectie geven we een zo volledig mogelijk overzicht van beschikbare
hulpmiddelen voor het Nederlands. We volgen de indeling uit sectie
1.7.
De informatie die hieronder volgt is ten dele ontleend aan:
Het samenstellen van een corpus waaraan geen annotatie is toegevoegd is
tegenwoordig vrij eenvoudig. Elektronische teksten zijn in overvloed
aanwezig op het WWW. Op sommige van deze teksten rust geen
auteursrecht (bijvoorbeeld de handelingen van de eerste en tweede
kamer in Nederland, of het lijvige rapport van de Nederlandse
parlementaire onderzoekscommissie Van
Traa).
Het verzamelen van een corpus over een bepaald onderwerp, of
met een evenwichtige vertegenwoordiging van verschillende
tekstsoorten, kan toch nog een tijdrovende bezigheid zijn. Literaire
teksten zijn beschikbaar via het
Coster-project.
Ook de
web-pagina's van de Stichting Tekstcorpora en Databestanden in de
Humaniora (STDH)
geven verwijzingen naar literaire corpora.
Daarnaast zijn enkele corpora speciaal voor taalkundig
onderzoek beschikbaar gemaakt:
- ECI/MCI CD-Rom.
Omschrijving: De CD-ROM European Corpus
Initiative Multilingual Corpus I bevat een aantal Nederlandse corpora:
- dut01. ``Newspaper, Dutch, 600K tokens, Articles from the
student newspaper Universiteitskrant of the University of
Groningen from the academic years 1990/1991 and 1991/1992.''
- dut02. ``Mixed, Dutch, 5203K tokens, A large Dutch corpus
from INL including transcripts of radio programs, newspaper and
magazine issues and some technical texts.''
- dut03. ``Mixed, Dutch, 128K, A continuation of dut02.''
Beschikbaarheid: Distributie door
Elsnet en het
Linguistic Data Consortium.
- ELRA-W0006.
Omschrijving: ``The Polylingual Document Collection
(ELRA-W0006), a collection
of newspaper articles from financial newspapers in 6 languages
(Dutch, English, French, German, Italian and Spanish). It consists
of the following sub-corpora: Dutch - Het Financiële Dagblad -
1992-1993. The corpus contains articles from the Dutch financial
newspaper Het Financiële Dagblad editions of 2nd January 1992
through to 24th December 1993. It contains around 8.5 million words
of text.''
Beschikbaarheid: Distributie door ELRA.
- De INL Corpora.
Omschrijving: Het Instituut voor Nederlandse Lexicografie
bezit verschillende corpora (Kruyt, 1995):
- 50 Miljoen Woorden Corpus 1994.
``Algemeen Nederlands, 1970-1990, 17 boeken over gevarieerde onderwerpen
(30% fictie), niet taalkundig verrijkt.''
- 15 Miljoen Woorden Corpus. ``Automatisch taalkundig verrijkt
(woorsoort en lemma); deel uit 50 Miljoen Woorden Corpus. ''
- 5 Miljoen Woorden Corpus 1994. ``Algemeen Nederlands, 1989-1994,
17 tekstbronnen, geclassificeerd naar publicatiemedium en onderwerp
taalkundig verrijkt met woordsoort en lemma. Er zijn nauwelijks
extra correctieslagen uitgevoerd. Dit geldt zowel voor de
teksten zelf, als voor de linguïstische gegevens woordsoort en
lemma. Woordsoortcodes en lemmavormen zijn automatisch toegekend.
Dit corpus heeft een andere samenstelling dan dat op de
multilinguale ECI/MCI CD-ROM.''
- 27 Miljoen Woorden Corpus 1995. ``Taalkundig verrijkt met
woordsoort en lemma.''
- 38 Miljoen Woorden Corpus 1996. ``Gevarieerde samenstelling met 3
hoofdcomponenten: krantenteksten (1992-1995), juridische component
(1814-1989), gevarieerd samengestelde component (1970-1995).
Teksten geclassificeerd volgens onderwerp en publicatiemedium.
Taalkundig verrijkt met lemma en twee woordsoortcategorieënstelsels:
een globale en een verfijnde met subcategorisatie. De teksten zijn
automatisch taalkundig verrijkt met een
lemma (trefwoordvorm) en twee woordsoorttoekenningen: een globale
(13 woordsoortcategorieën) en een verfijnde (met subcategorisatie)
conform de MECOLB standaard. Er zijn nauwelijks correctieslagen
uitgevoerd.''
Beschikbaarheid: De 50 miljoen en 15 miljoen corpora zijn
uitsluitend voor onderzoeksdoeleinden raadpleegbaar op het INL.
De 5, 27, en 38 miljoen corpora zijn
voor onderzoeksdoeleinden ook raadpleegbaar via internet (telnet)
door middel van een
retrievalprogramma.
- Het Eindhoven (Uit den Boogaart) corpus
(Uit den Boogaart, 1975; de Jong, 1979).
Omschrijving:
``Herkomst: Werkgroep
Frequentie-Onderzoek van het Nederlands, gesubsidieerd door Z.W.O.
(het Nederlandse Fonds voor Zuiver Wetenschappelijk Onderzoek, nu
het N.W.O.) en de Technische Hogeschool Eindhoven (geschreven taal);
Instituut voor Dialectologie, Volks- en Naamkunde van de Koninklijke
Nederlandse Academie voor Wetenschappen te Amsterdam (gesproken
taal). Inhoud: Geschreven en (getranscribeerd) gesproken
Nederlands, respectievelijk uit de periodes 1964-1971 en 1960-1973.
Omvang: Geschreven taal: plm. 600.000 woorden; gesproken taal: plm.
120.000 woorden. Codering: voornamelijk morfo-syntactisch
(woordsoort en flexievorm).''
Beschikbaarheid: ``Op verschillende
instituten is een versie van het corpus aanwezig; het is onduidelijk
of er copyright op het corpus rust. Waarschijnlijk is dit niet het
geval voor wetenschappelijk gebruik.''
- ANNO:
Omschrijving: Het ANNO-corpus (een publieke, geannoteerde,
gegevensbank voor het Nederlands) werd ontwikkeld in het kader
van het Vlaams korte termijnprogramma Spraak- en Taaltechnologie
voor het Nederlands (STTN).
Gezien de aard van dit programma,
dat de nadruk legt op spraaktechnologie, is gekozen voor een corpus
dat dicht aansluit bij de spreektaal. Het corpus bestaat uit de
tekst van BRTN-radio nieuwsuitzendingen en Actueel
uitzendingen. De transcripties van interviews binnen die
uitzendingen betreft spontane uitingen. Het corpus heeft een omvang
van in totaal ruim 640.000 woorden. Het gehele corpus is voorzien
van morfosyntactische en fonetische annotaties. Deze annotatie is
automatisch aangebracht (m.b.v. de WOTAN-tagger en TREETALK, een door W. Daelemans beschikbaar gesteld programma
voor grafeem-naar-foneem conversie), en deels gecorrigeerd.
Beschikbaarheid: Het corpus zal beschikbaar gesteld worden zodra
de auteursrechtelijke kwesties zijn geregeld.
Er zijn geen corpora voor het Nederlands voorzien van
constituentstructuur of semantische annotatie.
- ELRA-W0007.
Omschrijving: ``A Multilingual Parallel Corpus
consisting of translated data in nine European languages: Danish,
Dutch, English, French, German, Greek, Italian, Portuguese and
Spanish. The parallel data, provided by the European Commission,
comprises two sub-corpora from the Official Journal of the European
Communities:
- Official Journal of the European Commission, C
Series: Written Questions 1993.
This corpus contains written questions asked by members of the
European Parliament and corresponding answers from the European
Commission in 9 parallel versions. The total size of the corpus is
approximately 10.2 million words (ca. 1.1 million words per
language).
- Official Journal of the European Commission, Annex:
Debates of the European Parliament 1992-1994.
The Parliamentary Debates are a record of what
was said by members of the meeting as well as written input provided
to the meeting. The original data from which the translations are
produced consist of a transcript of the sittings, each member
speaking in the language of his choice. The final version consists
of nine parallel versions of the material.
This sub-corpus contains some 5 to 8 million words per language.''
Beschikbaarheid: Distributie door ELRA.
Binnen de spraaktechnologie spelen corpora reeds langere tijd een
belangrijke rol. Er zijn dan ook verschillende corpora voor spraak in
omloop, en aan een omvangrijk nieuw corpus wordt gewerkt. We noemen
hieronder de voor spraaktechnologie belangrijkste corpora. Bij de
hierboven genoemde bronnen zijn verwijzingen naar nog een aantal
andere corpora te vinden.
- Eindhoven (Uit den Boogaart) Corpus.
Omschrijving: Zie boven.
- Polyphone-NL
(SPEX).
Omschrijving:
Dit is een geheel van gedirigeerde spraak
van 5000 telefoonsprekers.
Iedereen kon een vrij antwoord formuleren op 17 vaste vragen:
``The Dutch Polyphone corpus
contains telephone speech from 5050
speakers. The corpus comprises 222,075 speech files, which all have been
orthographically transcribed. The data were collected directly off
an ISDN telephone line interface. The
corpus contains both read and extemporaneous items. Items to be read
consist of isolated digits, numbers a
postal code, guilder amounts, time, date, amounts, application
words, sentences with application words, phonetically rich sentences,
spelled words, city names. Several questions were asked to get the
spontaneous part of the speech.''
Beschikbaarheid: Distributie door ELRA.
- CHILDES (CHIld Language Data Exchange System).
Omschrijving: Het Nederlands
deel van dit corpus bevat uitsluitend kindertaal.
Beschikbaarheid: Het corpus is
verkrijgbaar op de
CHILDES-site in Antwerpen
en bij de initiatiefnemers in Pittsburgh, Carnegie Mellon. Voor
onderzoeksdoeleinden is het corpus ook toegankelijk op het Nijmeegse
Max Planck Instituut.
- GRONINGEN Corpus.
Omschrijving:
Korte gelezen teksten, woorden, zinnen en
klanken, meer dan 20 uur:
``The
Groningen Corpus
consists of 4 CD-ROMs containing over 20 hours of speech. It is a corpus of
read speech material in Dutch, recorded on PCM tape under fairly
good conditions. These 4 CD-ROMs contain speech from 238 speakers
who read: 2 short texts, 23 short sentences (containing all
possible vowels and all possible consonants and consonant clusters
in Dutch), 20 numbers,
16 monosyllabic words (containing all possible vowels in Dutch), and
3 long vowels. The
production on CD-ROM was partially supported
by ELSNET and the
pre-mastering was done at LIMSI-CNRS.''
Beschikbaarheid: Distributie door ELRA.
- EUROM1 (The multilingual European speech database).
Omschrijving: ``The first
really multilingual speech database produced in Europe. Equivalent
corpora for each of the European languages: same number of speakers
selected in the same way, and recorded in the same conditions with
common file formats. The content consists of Numbers, Passages, Sentences and
CVC. More than sixty speakers per language.''
Beschikbaarheid: Distributie door ELRA.
- COGEN.
Omschrijving: Het Corpus Gesproken Nederlands COGEN werd
ontwikkeld in het kader van het Vlaams korte termijnprogramma Spraak- en
Taaltechnologie voor het Nederlands (STTN).
Het bevat vier subcorpora:
- WL-OFF (word list office), een corpus van
gespelde woorden, commandowoorden, cijfers, en fonetisch rijke
woorden, gelezen door in total 174 sprekers, opgenomen in een
knatooromgeving (i.e. een omgeving die niet speciaal voor
opnames geprepareerd is en die dus achtergrondgeluiden
bevat). Totaal 2.16 uur gespelde woorden, en 5.83 uur
voorgelezen woorden.
- RS-OFF (read speech office, een corpus van
voorgelezen tekstfragmenten (5 paragrafen), door 174
sprekers, in kantooromgeving. Totale duur: 7.02 uur.
- WL-TEL (word list telephone), een corpus van
voorgelezen woordenlijsten, opgenomen via een
telefoonverbinding, opgenomen voor 185 sprekers. Duur: 5.85
uur.
- SS-TEL (spontaneous speech telephone), een
corpus van spontane uitingen, opgenomen via een
telefoonverbinding, opgenomen voor 126 sprekers. Duur: 2
uur.
Beschikbaarheid: Geen gegevens.
- Corpus Gesproken Nederlands.
Omschrijving: NWO, IWT, en een aantal andere
partners bereiden momenteel een project voor (begroot op 5 miljoen ECU,
looptijd 5 jaar) dat tot doel heeft een
corpus van plusminus 10 miljoen woorden samen te stellen. Het gehele
corpus zal worden voorzien van orthografische transcriptie,
woordsoorten, morfologische analyse, en lexicologische koppeling
(lemmatisering). Een kerncorpus van plusminus één miljoen woorden zal
bovendien worden voorzien van syntactische analyse, en fonetische en
fonologische transcripties, gekoppeld aan het akoestische signaal.
Beschikbaarheid: De Nederlandse Taalunie zal ter zijner tijd
verantwoordelijk zijn voor de distributie van de corpora.
- van Dale.
Omschrijving:
Van Dale
heeft het
Van Dale Groot woordenboek hedendaags Nederlands en het Van
Dale Groot Synoniemenwoordenboek (niet haar bekendste
product, de grote Van Dale (Geerts en Heestermans, 1995)) op CD-ROM beschikbaar
gemaakt (in totaal ongeveer 90.000 trefwoorden en 45.000
betekenisverwante woorden). De CD-ROM is bedoeld als elektronisch
woordenboek en thesaurus, en als hulpmiddel dat kan worden gebruikt in
combinatie met bekende tekstverwerkers als Word en WordPerfect. Merk op
dat dit niet betekent dat de woordenboeken bij automatische
spellingcorrectie of bij afbreken gebruikt kunnen worden.
Beschikbaarheid:
Distributie door Van Dale.
- WNT.
Omschrijving:
Het Woordenboek der Nederlandsche Taal, dat wordt
samengesteld op het INL, is sinds 1995 op
CD-ROM beschikbaar. Behalve een zeer uitgebreid woordenboek
van het oudere Nederlands, bevat het woordenboek ook een grote
hoeveelheid bewijsplaatsen in de vorm van (met name literaire)
citaten.
Beschikbaarheid:
Distributie door
AND Publishers.
- SDU/Elektronisch Groene Boekje.
Omschrijving:
Dit is de elektronische versie van het nieuwe Woordenlijst Nederlandse
Taal (Woordenlijst, 1996).
De functionaliteit is te vergelijken met de Van Dale CD-ROM:
het is vooral bedoeld om de juiste spelling van een woord op te
zoeken.
Beschikbaarheid:
Distributie door de
SDU.
- Sdu/Standaard Spellingschijf.
Omschrijving:
Dit programma
is bedoeld voor
spellingcorrectie. Het programma is bedoeld voor de tekstverwerker
WordPerfect, en zorgt voor een update van de woordenlijst die door
WordPerfect wordt geleverd. De regels van de nieuwe spelling worden toegepast
en nieuwe woorden uit de Woordelijst Nederlandse taal worden toegevoegd.
Beschikbaarheid:
Distributie door de
SDU.
- Words-L.
Omschrijving: Op de
web-pagina van WORDS-L
worden een
aantal woordenlijsten beschikbaar gesteld die
kunnen worden gebruikt voor spellingcorrectie en woorden afbreken in
combinatie met een aantal gangbare tekstverwerkers (Word,
WordPerfect, Latex) en correctieprogramma's (ispell). Het initiatief is
ontstaan uit onvrede over pakketten die door commerciële
leveranciers worden aangeboden. Een collectief heeft zich vervolgens
tot taak gesteld bestaande woordenlijsten (al dan niet beschikbaar in het
publieke domein) te combineren, uit te breiden en te corrigeren. De site
bevat ook een nuttig overzicht van bestaande pakketten en, met name, de
tekortkomingen van verschillende producten.
Beschikbaarheid:
Distributie via de web-pagina van
WORDS-L.
- CELEX. Omschrijving:
CELEX (Centre for Lexical
Information) heeft elektronische
databases ontwikkeld die verschillende types van lexicale informatie
over het hedendaagse Nederlands, Engels en Duits bevatten. De
Nederlandse database bevat ongeveer 400.000 woordvormen uit het
hedendaagse Nederlands. Het Nederlandse deel is voornamelijk
afgeleid uit het INL 50 miljoen woorden corpus. Er is nu
gedetailleerde informatie beschikbaar over de orthografie
(spelling), fonologie (uitspraak), morfologie (woordstructuur:
flexie en derivatie), syntaxis (grammatica) en woordfrequentie. Het
belangrijke aan de CELEX databases is dat alle informatie
gerepresenteerd is om tegemoet te komen aan de formele en strikte
voorwaarden voor computationele toepassingen.
Beschikbaarheid:
``The CELEX database is open to all academic researchers and people
associated with other not-for-profit research institutes free of
charge (at least until 1998). For
prospective customers from abroad, we recommend the stand-alone
CD-ROM version distributed by the Linguistic Data
Consortium.''
- EuroWordNet.
Omschrijving:
Dit project
heeft als doel de ontwikkeling van een
multilinguale lexicale database in de stijl van WordNet
(Miller et al., 1990).
De voorziene omvang van de database is 50.000 trefwoorden per taal. ``The
project aims at developing
a multilingual database with basic
semantic relations between words for several European languages
(Dutch, Italian and Spanish). The wordnets will be linked to the
American wordnet for English and a shared top-ontology will be derived,
while language
specific properties are maintained in the individual wordnets.
The database can be used for multilingual information retrieval
which will be demonstrated by Novell Linguistic
Development.''
Beschikbaarheid:
De resultaten van het project zullen ter zijner tijd onder licentie beschikbaar
worden gesteld aan derden.
- RBN.
Omschrijving:
Het Referentiebestand Nederlands, een multifunctionele
lexicale databank met informatie met betrekking tot
morfologie, syntaxis, combinatoriek, semantiek en
pragmatiek, op een expliciete, formele wijze weergegeven in
de vorm van feature-value paren (45.000 lemmata).
Beschikbaarheid:
Het RBN zal ter zijner tijd beschikbaar worden gemaakt voor
wetenschappelijk onderzoek.
- Van Dale.
Omschrijving: De vertaalwoordenboeken
Engels-Nederlands/Nederlands-Engels,
Frans-Nederlands/ Nederlands-Frans, en
Duits-Nederlands/ Nederlands-Duits zijn op CD-ROM beschikbaar.
Beschikbaarheid: Distributie door Van
Dale.
- ECHO Eurodicautom.
Omschrijving: ``The EURODICAUTOM database is an multilingual
source for all aspects of European institutions terminology,
contextual phrases and abbreviations in all official languages of
the European Union. Whilst the database is produced by the
Translation service of the European Commission (EC), the content is
an accumulation of terminology collected from outside sources such
as international organisations, dictionaries and glossaries.
Eurodicautom currently contains definitions for more than 4.500.000
terms and 180.000 abbreviations. The number of translated terms and
abbreviations are distributed throughout the languages.
EURODICAUTOM is a multilingual data bank. The languages available
are : Danish, Dutch, English, French, German, Greek, Italian,
Portuguese, Spanish, Finnish and Swedish. The database is updated
monthly and the data are collected from 1976 onwards.''
Beschikbaarheid: De database kan on-line geraadplegd worden
via de Eurodicautom web-pagina .
- Euterpe (Trados).
Omschrijving: ``This dictionary
was created by the European Parliament. It now contains over 150,000
entries in the 12 official languages of the European
Community.''
Beschikbaarheid: Distributie via
Trados.
- Multi-language pronunciation dictionary (Onomastica).
Omschrijving: ``This resource is from the ONOMASTICA LRE-61004
project related to the Multi-language pronunciation dictionaries of
proper names. The project ONOMASTICA, funded by the
LRE programme,
has built pronunciation dictionaries for the names of the European
Union. These are city and town names, street names, family names,
first names, product names, for 11 languages - Danish, Dutch,
English, French, German, Greek, Italian, Norwegian, Portuguese,
Spanish and Swedish. An extension to Eastern European languages is
ongoing. ELRA and the Dutch PTT are negotiating the terms,
conditions and modalities of distribution of the complete Dutch
Onomastica dictionary.''
Beschikbaarheid: Distributie door ELRA.
- Speri-Data AG Basic dictionaries (colloquial language).
Omschrijving: ``These dictionaries contain a daily-life
vocabulary. They include phonetic transcription with related phoneme
lists. The following languages
are available: Dutch 12,000 entries.''
Beschikbaarheid: Distributie door ELRA.
- FONILEX.
Omschrijving:
Fonilex is een
uitspraaklexicon voor het Nederlands in Vlaanderen. Het werd
ontwikkeld in het kader van het Vlaams korte termijnprogramma
Spraak- en taaltechnologie voor het Nederlands. Fonilex bevat de
uitspraak van ruim 200.000 woorden, ontleend aan de CELEX
database. Voor elke woordvorm vermeldt de databank de spelling, de
fonologische vorm, en minstens één en ten hoogste drie
(regelmatige) fonetische uitspraakvormen. Elke ingang bevat tevens
een identificatienummer dat het verband legt met de CELEX
database, zodat daar vermelde gegevens eveneens
toegankelijk zijn.
Beschikbaarheid: Sinds kort is het programma voor
wetenschappelijk onderzoek beschikbaar gesteld voor derden.
In deze sectie beschrijven we een aantal hulpmiddelen voor TST
die een algoritmisch aspect bevatten en die speciaal gericht zijn op
het Nederlands. Daarnaast noemen we een aantal standaards.
We gaan in deze sectie niet in op algemene software voor het
exploreren van corpora en woordenboeken, het maken van morfologische
software, of het ontwikkelen van grammatica's.
- Xerox.
Omschrijving:
Xerox Research Centre Europe
heeft programma's ontwikkeld voor de
morfologische analyse van diverse Europese talen, gebaseerd op het
gebruik van finite state technologie. De on-line demo geeft
bijvoorbeeld het resultaat in figuur 2.1.
De technologie wordt ingezet bij toepassingen waarin verschillende
talen een rol spelen (automatisch vertalen, multilinguale IR).
Beschikbaarheid:
Er is een on-line demo versie. Voor commerciële licenties en
toepassingen is de Xerox-dochter
Inxight verantwoordelijk.
Afbeelding 2.1:
Uitvoer van de on-line demo van Xerox' morfologische
analyse-programma.
|
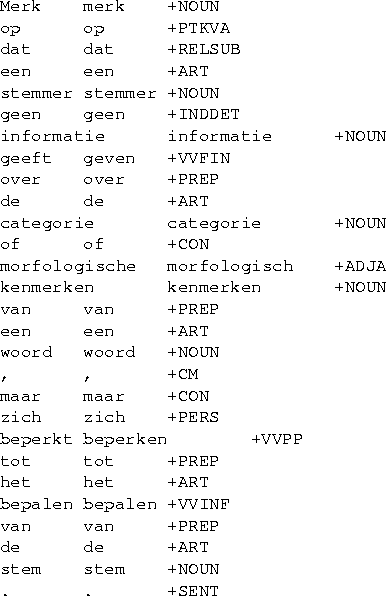
- Uplift.
Omschrijving:
Het Uplift project
onderzoekt de mogelijkheden van taaltechnologie
voor IR. Als onderdeel van een project is een stemmer
gemaakt (een programma dat de stam van verbogen woorden bepaalt).
Merk op dat een stemmer geen informatie geeft over de
categorie of morfologische kenmerken van een woord, maar zich beperkt
tot het bepalen van de stem. Daarnaast wordt de (taalkundige)
accuratesse van het systeem beperkt doordat geen woordenboek wordt
gebruikt. (Analyse van klapschaatsen geeft
klapschaats, van gemiddelde geeft middel, van varken (en varkens) geeft vark, van kinderen
geeft kind, van verzekeren geeft verzekeer.)
Beschikbaarheid:
Een on-line demo is beschikbaar, en ook de code van het programma is
publiek gemaakt.
- Xerox.
Omschrijving:
De gebruikte technieken worden niet beschreven, maar het is
waarschijnlijk dat de Xerox tagger
ontwikkeld is volgens de statistische
benadering die wordt beschreven in
Chanod en Tapanainen (1995) en Cutting et al. (1992).
Deze methode maakt gebruik van een morfologisch analyseprogramma, in
combinatie met een guesser die de mogelijke categorieën van
onbekende woorden bepaald, en een statistisch model dat gebruik
maakt van frequentieinformatie (woord is met % kans een
zelfstandig naamwoord) en van informatie over de
waarschijnlijkheid van woordklasse-combinaties (de kans dat een
adjectief vooraf wordt gegaan door een lidwoord is %). De
gebruikte tagset bevat 49 elementen. Een voorbeeld van de
werking van de on-line demo-versie is te vinden in
figuur 2.2.
Beschikbaarheid:
Er is een on-line demo versie. Voor commerciële licenties en
toepassingen is de Xerox-dochter
Inxight verantwoordelijk.
Afbeelding 2.2:
Voorbeeld uitvoer van de Xerox tagger.
 |
- Wotan.
Omschrijving:
``De WOTAN tagger
is ontwikkeld door Johan Berghmans
(Berghmans, 1994).
De WOTAN tagger maakt gebruik van softwarecomponenten die door de
TOSCA-groep zijn ontwikkeld
voor het Engels, maar die voor het grootste gedeelte
taalonafhankelijk zijn. De trainingsdata, die natuurlijk wel
taalafhankelijk zijn, bestonden uit 1,5 miljoen woorden die in
eerdere projecten getagd en gecontroleerd waren. De tagger bestaat
uit vier componenten.
Een eerste component is de tokenizer. Die maakt de onbewerkte tekst
in ASCII-formaat klaar voor verwerking. Een tweede component is een
woordvormenlexicon. Dit is met behulp van speciale software
geëxtraheerd uit het trainingscorpus. Omdat er in de tagger geen
morfologische regelcomponent is opgenomen, waaruit stamvormen zouden
kunnen worden afgeleid, bevat het lexicon geen woordstammen, maar
gehele woordvormen. Een derde component is het suffixenlexicon.
Aangezien het mogelijk is dat een woord uit de te analyseren tekst
niet in het woordvormenlexicon voorkomt (omdat het niet in het
trainingsmateriaal aanwezig was), is er een suffixenlexicon
voorzien. Dit moet voorkomen dat onbekende woorden niet van een tag
zouden worden voorzien. Een vierde component tenslotte is van
probabilistische aard. Deze component bepaalt op basis van de
context welke tag aan een woord moet worden toegekend.''2.1 Figuur 2.3 geeft een voorbeeld van de analyse van
een tekstfragment met de WOTAN-tagger.
Beschikbaarheid: Geen gegevens.
Afbeelding:
Voorbeeld van de uitvoer van WOTAN. Het -teken geeft
hier een zinsgrens aan.
 |
- MBT (KUB).
Omschrijving: Aan de KUB
werd een memory-based part-of-speech tagger-generator
ontwikkeld
(Daelemans et al., 1996a; Daelemans et al., 1996b). Met behulp
hiervan is o.a. een tagger voor het Nederlands ontwikkeld, die
gebruik maakt van de vereenvoudigde WOTAN tag-set (alleen
woordsoorten, 13 tags). Het foutenpercentage voor deze tagger, die
werd getraind op het Eindhoven-corpus is 4% (3% voor bekende
woorden, 28% voor onbekende woorden).2.2 Een
voorbeeld van de uitvoer is te vinden in figuur 2.4.
Er bestaat ook een versie van MBT met de volledige
WOTAN tag set.
Beschikbaarheid: Er is een on-line
demo-versie van de MBT tagger
beschikbaar. Specifieke taggers zijn onder voorwaarden beschikbaar
voor onderzoekdoeleinden.
Afbeelding 2.4:
Uitvoer van de MBT tagger.
 |
- DutchTale (INL).
Omschrijving:
``Om de teksten voor zijn Taaldatabank van het Hedendaagse Nederlands
te taggen en lemmatiseren, gebruikt het INL o.a. de POS
tagger
Dutchtale. De tagger (voor het Nederlands) is volautomatisch, maar
biedt wel de mogelijkheid om achteraf, met behulp van een
intelligente tekstverwerker die daarvoor ontwikkeld is, de output
manueel te controleren.
Het systeem bestaat uit drie modules: In de eerste module (lexicale
opzoek- en morfologische analysemodule) vindt lemmatisering en
woordsoorttoekenning plaats. Als een woord niet in een tokenlexicon
gevonden, dan vindt er morfologische analyse plaats. Het gaat hier
om zowel samenstellings- als afleidingsanalyse. De tweede module
desambigueert op basis van een beperkte regelcomponent. In een apart
regelbestand staan enkele honderden desambigueringsregels opgesteld
in een formele taal. De derde module is statistisch van aard en
werkt met n-grammen. De meest waarschijnlijke desambiguering wordt
gekozen op basis van de directe linker en rechter context van een
ambigu token. Een woordsoorttag wordt toegevoegd indien er in de
voorgaande modules geen lemma was toegekend.''2.3
Beschikbaarheid: Geen gegevens.
- D-Tale (VU).
Omschrijving: De dutch tagger lemmatizer voor het
Nederlands is een programma dat werd ontwikkeld door de afdeling
lexicologie aan de VU, voor Van Dale. De output is een tekst
voorzien van tags die woordklasse (zelfst. naamw, werkwoord)
en eventuele aanvullende kenmerken aangeven (enkelvoud/ meervoud) en
ook het lemma. Tijdens de analyse raadpleegt het programma het
woordenboek (140.000 woordvormen), worden morfologische regels
toegepast, worden mogelijke woordsoorten van
onbekende woorden voorgesteld, en worden tenslotte met behulp van
statistische technieken ambiguiteiten opgelost. Het foutenpercentage
is 7%.2.4
Beschikbaarheid: Geen gegevens.
- Corrie.
Omschrijving: Theo Vosse ontwikkelde de spelling- en grammaticacorrector
CORRIE voor het Nederlands (Vosse, 1994).
Onderdeel van het programma is een
(Tomita-) parser voor het Nederlands. De grammatica is een
augmented context-free grammar (een CFG waaraan
attributen zijn toegevoegd om zaken als persoon en getal te kunnen
beschrijven) met plusminus 500 regels en 14 regels die speciaal voor
het doen van correctie zijn toegevoegd. Het systeem is getest op
verschillende documenten (o.a. juridische teksten, wetenschappelijke
boeken en scripties, en (6 megabyte) nieuwsberichten).
Beschikbaarheid:
Geen gegevens.
- Amazon.
Omschrijving: Amazon is een grammatica ontwikkeld door
Peter-Arno Coppen (KUN). Het is een grammatica die het
Nederlands redelijk breed afdekt: ongeveer 95% van de ingevoerde
tekst kan door het systeem ontleed worden. Een on-line versie van het systeem is
te vinden op de AGFL (affix grammars over finite
lattices) web-pagina. Deze versie werd gemaakt door Erik Oltmans
(Oltmans, 1994), en maakt gebruik van een
woordenboek van ongeveer 300.000 woorden dat uit CELEX werd
afgeleid. Voorbeeld uitvoer van het systeem is te vinden in figuur
2.5.
Beschikbaarheid: Geen gegevens.
Afbeelding 2.5:
Syntactische analyse in AMAZON.
 |
Er zijn geen producten voor spraakherkenning die zich speciaal op het
Nederlands richten.
- Fluent Dutch. Fluent Speech
Technology
ontwikkelt Fluent Dutch, een programma voor spraaksynthese. Men
maakt gebruik van de MBROLA (public domain) difoon
spraaksynthesizer.
Er is een difoon-model voor het Nederlands
beschikbaar (ook via MBROLA). Aan een
programma voor grafeem-naar-foneem conversie wordt nog gewerkt:
`` Fluent Dutch is a speech synthesis system for Dutch, which runs
under Windows 3.1 or higher. It is not (yet) a full-fledged
text-to-speech synthesizer, but generates synthetic speech of a
superior quality from a phonetic transcription. The system can be used
in multimedia applications such as "talking" dictionaries and
educational CD-ROMS, as well as in dialogue systems of various kinds.
At present, the system uses a male voice. A female voice is in
preparation.''
Beschikbaarheid:
Een deel van het materiaal is vrij beschikbaar via Mbrola.
- TreeTalk.
Omschrijving: TreeTalk
is een programma voor grafeem-naar-foneem
conversie dat is ontwikkeld binnen het inductive language
learning project aan de KUB
(Daelemans en van den Bosch, 1996; van den Bosch, 1997).
Het programma zet een reeks
woorden om in reeksen fonemen in DISC notatie (de notatie die
door CELEX wordt gebruikt). Het programma werkt op woordbasis
en houdt dus geen rekening met prosodische effecten op zinsniveau.
Beschikbaarheid:
Er is een on-line demo-versie van het
programma beschikbaar.
- Fonetische Alfabetten.
Het meest gebruikte fonetische alfabet
is IPA (international phonetic association. Voor
codering van corpora en elektronische lexica is
dit alfabet echter minder geschikt, omdat het gebruikt maakt van
symbolen die geen deel uitmaken van het ASCII alfabet. Om dit
probleem te omzeilen zijn verschillende ASCII fonetische
alfabetten ontwikkeld. Een algemeen aanvaard alfabet is SAMPA
(Wells, 1987).
In de CELEX database wordt bijvoorbeeld gebruik
gemaakt van SAMPA. Daarnaast zijn binnen CELEX nog drie
andere notaties beschikbaar (CELEX, CPA, en DISC),
waarvan er één (DISC) zo is ontworpen dat ieder fonetisch
symbool met precies één teken correspondeert (met name nuttig
voor computationele toepassingen). Merk overigens op dat het hier
steeds slechts notationele varianten van SAMPA en IPA
betreft, zodat de verschillende notaties eenvoudig naar elkaar
omgezet kunnen worden. Voor het FONILEX uitspraakwoordenboek
werd gebruik gemaakt van YAPA (yet another phonetic
alphabet). Dit alfabet wijkt op onderdelen af van de notatie die
in CELEX primair is (DISC), o.a. doordat het rekening
houdt met de uitspraak van (Franse) leenwoorden.
- Woordsoorten.
Corpora die zijn voorzien van informatie over
woordsoort en part of speech taggers die automatisch
woordsoorten toekennen maken gebruik van een vooraf gedefinieerde
verzameling woordsoorten, de tagset. In de WOTAN tagger wordt gebruik gemaakt van een tagset die is
ontwikkeld door de TOSCA groep in Nijmegen. Deze tagset bestaat
uit 243 verschillende tags (zie ook figuur
2.3). Uitgangspunt was de verdeling in hoofdwoordsoorten en
hun onderverdelingen zoals die is te vinden in de ANS. Een sterk
vereenvoudigde versie van deze tagset maakt alleen een onderscheid
in woordsoorten, en bevat slechts 12 elementen (ADJ, ADV, ART,
CONJ, INT, MISC, N, NUM, PREP, PRON, PUNC, V). Deze wordt
bijvoorbeeld gebruikt in de (online) MBT tagger. De Xerox
tagger maakt gebruik van een verzameling van 49 tags (zie ook figuur
2.2). De INL corpora maken gebruik van een
kleine tagset (dertien elementen: a(djectief), b(ijwoord),
c(onjunctie), e(igennaam), l(idwoord),
o(ngespecificeerd),
p(ronomen),
t(elwoord),
v(oorzetsel),
z(elfstandig naamwoord)), en soms van een grotere tagset, die werd
ontwikkeld door de TOSCA groep (KUN) in het kader van het
MECOLB-project. Deze tagset is waarschijnlijk identiek aan de
WOTAN tagset.
Binnen het reeds vaker genoemde EAGLES-project is een aanzet
gegeven voor een standaard voor morfosyntactische annotatie van
corpora.
Er worden vier typen tags onderscheiden:
- Verplichte tags.
- Hiertoe behoren de hoofdwoordsoorten (Zelfstandig
Naamwoord, Werkwoord, Voegwoord, ...
- Aanbevolen tags.
- Hiertoe behoren de tags die algemeen gebruikte
eigenschappen aanduiden als Geslacht, Getal, Persoon, ...
- Optionele tags.
- Voor bepaalde doeleinden kan het nodig zijn meer
specifieke woordsoorten, eigenschappen etc. te onderscheiden. Dit
wordt gedaan met optionele tags.
- Taalspecifieke tags.
- Bepaalde woordsoorten en eigenschappen komen
slechts in enkele (Europese) talen voor. Hiervoor zijn aparte tags
nodig. Voor het Nederlands zijn er bijvoorbeeld extra tags
voorgesteld voor
de waarden De, respectievelijk Het-woord bij Geslacht, en de
waarden Vol, respectievelijk Gereduceerd bij
Persoonlijk Voornaamwoord.
De volledige tagset is op bovengenoemde webpagina terug te vinden.
- Syntactische en semantische annotatie.
Binnen het hiervoor genoemde EAGLES-project is ook een voorstel gedaan voor
een standaard voor syntactische
annotatie. Ook
hier zijn er een aantal typen tags voorgesteld:
- Verplichte tags.
- Er zijn vele redenen om een corpus syntactisch te
annoteren. Er (b)lijkt geen type annotatie te zijn die voor alle
doeleinden voldoet.
- Aanbevolen tags:
- de bekende categorieën Zin, Niet-finiete Zin, Nominale
Constituent, Verbale Constituent, Adjectivische Constituent,
Adverbiale Constituent en Voorzetsel Constituent
- Optionele tags.
- Er worden verschillende typen optionele tags
onderscheiden waaronder:
- Syntactische tags.
- Hieronder vallen tags voor bijvoorbeeld het nader benoemen van Niet-finiete
Zinnen: afhankelijke zin, beknopte bijzin, enz. Of voor het aanduiden
van de grammatische functie: Onderwerp, Meewerkend Voorwerp, enz. De
keuze van de tags is in al deze gevallen voor een deel
taalspecifiek.
- Semantische tags.
- Voor nadere tags bij een NC valt hier te denken aan Definiet en
Indefiniet, bij een AdvC aan een nadere precisering als Tijd,
Plaats, Hoedanigheid, etc.
Het zal duidelijk zijn dat deze EAGLES-standaard nog niet de status heeft van
bijvoorbeeld die met betrekking tot morfosyntactische annotatie.
Er zijn niet of
nauwelijks voorbeelden van syntactisch geannoteerde corpora voor het
Nederlands. Binnen het ANNO project is hiertoe wel een aanzet
gegeven (zie figuur 2.6 voor een voorbeeld).
Binnen het OVIS project
is een deel van het corpus voorzien
van syntactische en semantische annotatie (zie figuur 2.7).
Afbeelding 2.6:
Syntactische annotatie in ANNO.
![\begin{figure}
\begin{verbatim}(2 [CLS [CLS [NP $SUBJ (''Het'' 1) (''KMI'' 2) ] ...
...lichte'' 31) (''voorjaarsbuien''32) ] ] ] (''.'' 33) )\end{verbatim}\end{figure}](img7.gif) |
Afbeelding 2.7:
Syntactisch/semantische annotatie in OVIS.
![\begin{figure}
\begin{verbatim}[van,middelburg,wil,ik,reizen,naar,groningen],
''...
...on.place/naar
NP\vert town.groningen/groningen))))
''\end{verbatim}\end{figure}](img8.gif) |
In deze sectie noemen we een aantal hulpmiddelen die voor andere talen
beschikbaar zijn, die van groot belang lijken voor onderzoek op TST-gebied, en die door onze interviewpartners genoemd werden als
voorbeelden en als hulpmiddelen waarvan men graag een Nederlandstalige
tegenhanger zou zien. Binnen het kader van dit onderzoek bleek het
niet mogelijk een uitputtend onderzoek te doen naar hulpmiddelen voor
talen anders dan het Nederlands, en ook onze gesprekspartners gaven
meermalen aan niet over zo'n overzicht te beschikken. Wel lijkt
men het eens te zijn over een aantal van de belangrijkste
producten. Het onderstaande overzicht is gebaseerd op voorbeelden die
in de interviews werden genoemd. Het is zeer onvolledig, en
beperkt zich tot het Engels.
Bij instanties als ELRA, LDC, het DFKI software registry is nog een veelvoud aan
vergelijkbaar materiaal te vinden.
- British National Corpus.
Omschrijving: Dit is een groot (100 miljoen) corpus
van gesproken en geschreven Engels.
Het corpus is samengesteld uit kortere
teksten (maximaal 45.000 woorden) en fragmenten (van maximaal 45.000)
woorden uit langere teksten. Ongeveer 10 miljoen woorden van het
corpus zijn transcripties van gesproken Engels.
Beschikbaarheid:
Het corpus is beschikbaar op CD-ROM en via het WWW.
De teksten uit het corpus mogen zelf
niet verder gedistribueerd of openbaar gemaakt worden, maar alle
resultaten die gebaseerd zijn op corpusonderzoek mogen gebruikt worden
voor onderzoeksdoeleinden en daarop gebaseerde producten.
- Brown Corpus, LOB Corpus.
Omschrijving: Het ICAME (International
Computer Archive of Modern and Medieval English)
distribueert
verschillende corpora, waaronder het Brown-corpus (1 miljoen
woorden) en het Londen-Oslo-Bergen-corpus (1 miljoen
woorden). Beide corpora zijn beschikbaar in verschillende
formaten, waaronder versies die voorzien zijn van woordsoort.
Beschikbaarheid: Distributie door ICAME.
- Penn Treebank.
Omschrijving: De Penn Treebank bestaat uit een aantal corpora
(o.a. 1,6 miljoen woorden uit de Dow Jones nieuwsdienst, 1 miljoen
woorden uit de Wall Street Journal, materiaal ontleend aan ATIS, MUC, en IBM handleidingen) die handmatig van
constituentstructuur zijn voorzien.
Beschikbaarheid:
Het corpus wordt gedistribueerd door het Linguistic Data
Consortium.
Het corpus is beschikbaar op
CD-ROM, en kan ook gedeeltelijk via het Web geraadpleegd
worden.
- UN Corpus.
Omschrijving: Het UN-corpus bestaat uit parallele teksten
voor het Engels, Frans, en Spaans met een omvang van 2,5 gigabyte
tekst.
Beschikbaarheid:
Het corpus wordt gedistribueerd door het Linguistic Data
Consortium.
- Crater.
Omschrijving: Het CRATER-corpus
is een 1 miljoen parallell (aligned) corpus voor het Engels,
Frans, en Spaans. Het corpus is voorzien van annotatie (lemma en
woordsoort, gecorrigeerd), en wordt geleverd met hulpmiddelen voor
extractie en alignment.
Beschikbaarheid: Distributie door ELRA.
- ATIS.
Omschrijving: Het ATIS (air travel information system)
corpus, verkrijgbaar bij LDC, bevat verschillende opnames van
interactie tussen gebruikers en een (echt of gesimuleerd) systeem
dat informatie geeft over verbindingen van
luchtvaartmaatschappijen. De corpora zijn aangemaakt en gebruikt in
het DARPA spoken language systems programma.
Beschikbaarheid: Distributie door het Linguistic Data
Consortium.
- CSR.
Omschrijving: De CSR (continuous speech recognition corpora,
verkrijgbaar bij LDC, bevatten gelezen fragmenten ontleend aan
het Wall Street Journal corpus (zie Penn Treebank). De fragmenten
zijn zo gekozen dat ze gebruik maken van een vocabulaire van 5.000 of
20.000 woorden. De corpora zijn gebruikt in het DARPA
Spoken Language Program.
Beschikbaarheid: Distributie door het Linguistic Data Consortium.
- Overige LDC Corpora. Naast bovengenoemde corpora zijn via
het Linguistic Data Consortium nog een groot aantal andere
spraakcorpora, zoals CALLFRIEND, CALLHOME,
en SWITSCHBOARD en tekstcorpora, zoals de BROADCAST NEWS
TRANSCRIPTS, het NORTH AMERICAN NEWS TEXT CORPUS, en TIPSTER, beschikbaar.
- COBUILD.
Omschrijving: Het Collins' Cobuild (learners)
woordenboek
is gebaseerd op intensief gebruik van corpusgegevens (waarvoor een Bank of English is samengesteld met een omvang van meer dan 320
miljoen woorden).
Beschikbaarheid: Distributie door Colbuild. Het corpus zelf is
deels on-line te raadplegen, en wordt deels meegeleverd op de Cobuild
CD-ROM, die het woordenboek, een grammatica, en verwijzingen
naar het corpus bevat.
- WordNet.
Omschrijving: WordNet is een semantische lexicale database
voor het Engels (Miller et al., 1990), met een omvang van meer dan 100.000
woorden, waarin voor zelfstandige naamwoorden, adjectieven, en
werkwoorden informatie over synoniemen (plank, board),
antoniemen (rise, fall), hyponiemen (maple, tree, ISA-relatie), en meroniemen
(tree, root) (HASA-relatie).
Beschikbaarheid: De database is vrij beschikbaar via
de Wordnet
web-pagina.
- Comlex.
Omschrijving:
Comlex is een woordenboek met ongeveer 38.000
trefwoorden dat gedetailleerde informatie bevat over
de syntactische eigenschappen van ieder woord, met name
valentie.
Beschikbaarheid: Distributie door het Linguistic Data Consortium.
- Brill-tagger.
Omschrijving: De POS-tagger van Eric Brill
(Brill, 1995) maakt gebruik van transformation-based
error-driven learning om uit een corpus voorzien van woordsoorten
een tagger af te leiden.
Beschikbaarheid: De tagger is vrij beschikbaar via
Brill's web-pagina.
- EngCG-2.
Omschrijving: EngCG-2 van het Finse
bedrijf Conexor is een snelle POS-tagger voor het Engels, die
gebruik maakt van constraint grammar, een regelformalisme
gebaseerd op finite state technologie
(Samuelson en Voutilainen, 1997).
Beschikbaarheid: Commerciële en
academische licenties zijn verkrijgbaar via
Conexor.
- XPOST.
Omschrijving: De Xerox Part-of-Speech Tagger XPOST
(Cutting et al., 1992) is een tagger geïmplementeerd in LISP,
getraind op
het Brown-corpus.
Beschikbaarheid: De tagger is beschikbaar voor
onderzoeksdoeleinden.
- XTAG.
Omschrijving: XTAG
is een wide-coverage grammatica en voor het Engels, gebaseerd
op Tree Adjoining Grammar ontwikkeld voor
onderzoeksdoeleinden. Het systeem bevat een tagger getraind op het
Wall Street Journal corpus, een woordenboek met meer dat 300.000
woordvormen, en meer dan 300
grammaticale regels (lexicalized trees).
Beschikbaarheid: De grammatica, documentatie, en bijbehorende
software is vrij beschikbaar.
- CLE.
Omschrijving: De
Core Language
Engine
(Alshawi, 1992) is een computationele grammatica, ontwikkeld door
SRI Cambridge, die is
bedoeld als general purpose natural language processing
system. De CLE is gebruikt voor natuurlijke taal interfaces
(ook voor gesproken taal), vertaalsystemen voor gesproken taal,
toepassingen waarbij controlled language een rol
speelt.
Beschikbaarheid: Licenties voor de CLE zijn mogelijk
voor onderzoeksdoeleinden en voor commerciële toepassingen.
- EngLite en FDG.
Omschrijving: De ENGLITE en FDG parsers van het
Finse bedrijf Conexor zijn wide-coverage parsers die een light (shallow) syntactic parse c.q. een full dependency
parse toe kennen aan zinnen.
Beschikbaarheid: Commerciële en academische licenties zijn
verkrijgbaar via Conexor.
- TSNLP.
Omschrijving: De TSNLP testsuite bevat geannoteerde data
voor het Engels, Duits, en Frans, bedoeld om te worden gebruikt bij
het testen en evalueren van taalverwerkende systemen. Per taal zijn
meer dan 4000 items
opgenomen.
Beschikbaarheid: Distributie via ELRA.
In deze sectie zal een overzicht worden gegeven van de
instellingen (onderzoek, onderwijs, beleid) die actief zijn op
het gebied van de Taal- en Spraaktechnologie. Hierbij wordt in een aparte
sectie aandacht besteed aan de rol van de industrie. Tenslotte zullen een
aantal initiatieven in het buitenland op een rijtje worden gezet.
In Nederland wordt aan de meeste universiteiten onderzoek
verricht op het gebied van TST voor het
Nederlands. Bijvoorbeeld in:2.5
- Amsterdam, UvA:
Alfa-informatica (t),
Instituut voor Fonetische
Wetenschappen (s)
- Amsterdam, VU: Lexicologie (t), Terminologie (t)
- Delft, TUD: Kennisgestuurde Systemen (s)
- Eindhoven, TUE: Instituut voor Onderzoek naar Mens-Systeem
Interactie (s)
- Groningen, RUG: Alfa-informatica (t)
- Leiden, RUL: Algemene Taalwetenschap (t)(s), Functieleer(t)
- Nijmegen, KUN: Taal- en Spraaktechnologie (t)(s)
- Tilburg, KUB: Taal en Informatica (t)
- Twente, UT: CTIT (Centrum voor Telematica en
Informatietechnologie) (t) (s)
- Utrecht, RUU: UIL/OTS (Utrecht Institute of Linguistics/
Onderzoeksinstituut voor Taal en Spraak) (t)(s)
In Vlaanderen vindt er bijvoorbeeld onderzoek plaats aan de universiteiten in:
en eveneens aan de Katholieke Vlaamse Hogeschool (Departement
Tolken en Vertalers) in Antwerpen.
Daarnaast zijn er in beide landen nog een aantal universitaire
onderzoekscentra binnen andere faculteiten,
die zich vooral op bijvoorbeeld het juridisch of het medisch
taalgebruik richten, bijvoorbeeld ICRI (Interdisciplinair
Centrum voor Recht en Informatica, KUL) en Medische Informatica
(Gent, Geneeskunde).
In Nederland zijn er een aantal onderzoekscholen opgericht,
zelfstandige organisatorische eenheden met een eigen
budgetverantwoordelijkheid. In zo'n onderzoekschool wordt
onderzoek van een
of meer universiteiten op een bepaald terrein gebundeld met het doel de kwaliteit van het
onderzoek te verbeteren en tot een samenhangend
onderzoeksprogramma te komen. De scholen kunnen interuniversitair
zijn. Enkele voor TST relevante
onderzoekscholen zijn:
- Onderzoekschool LOGICA,
- IPA (Instituut voor Programmatuurkunde en Algoritmiek),
- BCN (Behavioural and Cognitive Neurosciences),
- J.F. Schouten Institute for User-System Interaction
Research (opvolger van de onderzoekschool Perception and Technology),
- SIKS (School voor Informatie- en KennisSystemen),
- LOT (Landelijke Onderzoekschool Taalwetenschap),
- CLS (Centre for Language Studies),
- HIL (Holland
Institute of Generative Linguistics),
- IFOTT (Instituut voor
Functioneel Onderzoek van Taal en Taalgebruik)
2.6
In Vlaanderen werken de universiteiten van Antwerpen, Gent,
Brussel (VUB) en
Leuven samen in CLIF (Computational Linguistics and Language Technology), een FWO-onderzoeksgemeenschap. CLIF heeft zich tot
taak gesteld de Vlaamse taaltechnologie te coördineren en
internationaal te verankeren. Daarnaast worden er hulpbronnen
bijeen gebracht.
In Nederland zijn ook nog een aantal niet-universitaire
onderzoekscentra werkzaam, veelal gefinancierd door overheid,
bedrijfsleven en/of universiteiten samen:
Het TELEMATICA INSTITUUT is een consortium van bedrijven en
kennisinstellingen, met financiële steun van de overheid.
Er wordt vooral
contractonderzoek uitgevoerd. De deelnemers zijn IBM, KPN,
Lucent Technologies, ING en Rabofacet. Daarnaast contribueren
ABP/USZO, Cap Gemini, Ericsson, Océ en Syllogic. De bedrijven
ECT, Heidemij, NS, NOB, Origin en VNU zijn geassocieerd lid. Het
Telematica Consortium is nog in onderhandeling met andere bedrijven
over hun deelname. De Universiteit Twente, de Universiteit Delft,
CWI, TNO,
Multimedia en Telecommunicatie (TNO MET) nemen deel als
kennisinstellingen. Het vroegere Telematica Research Centre (TRC)
is in het Telematica Instituut opgegaan.
De vele TNO-onderzoeksinstituten voeren vooral contractonderzoek
(zowel meer fundamenteel als toegepast) voor de overheid en het
bedrijfsleven uit. TNO is een semi-overheidsinstelling (het is opgericht
door de overheid, maar kan tot op grote hoogte een eigen beleid
voeren).
Voor TST zijn vooral belangrijk het TNO Institute for Applied
Physics (TPD, Delft),
het TNO Fysisch en Elektronisch Laboratorium (Den
Haag), het TNO Human Factors Research
Institute (Soesterberg) en, op
beleidsniveau, TNO Strategie, Technologie en
Beleid (STB, Apeldoorn).
Het CWI (Centrum voor Wiskunde en
Informatica) Amsterdam is meer zijdelings bij het TST-onderzoek voor
het Nederlands betrokken.
Verder zijn er nog belangrijke instituten
die vooral toegepast onderzoek verrichten, of resources en
tools ter beschikking stellen:
- CELEX (Centrum voor Lexicale Informatie),
Nijmegen (Max Planck Instituut). In 1986 gesticht door 5 Nederlandse
onderzoekscentra, waaronder het Max Planck Instituut en de
Universiteit van Nijmegen (Taal en Spraak). Sinds 1989 is CELEX erkend als nationaal kenniscentrum.
CELEX
beschikt over een grote database met informatie met betrekking tot fonologie,
morfologie, syntaxis en frequentie voor Nederlandse, Duitse en
Engelse lemmata.
- SPEX, (Speech Processing EXpertise Centre), Nijmegen
(KUN). Opgericht in 1987, deelnemende
universiteiten: Amsterdam,
Utrecht, Nijmegen, Leiden en Eindhoven.
SPEX is een organisatie die zich bezighoudt met het ontwikkelen en
beschikbaar stellen van software, tools en databases op het
gebied van spraaktechnologie. Validatie (spraak) is momenteel een van de
belangrijkste activiteiten (bijvoorbeeld voor ELRA).
- STDH (Stichting Tekstcorpora en Databestanden in de
Humaniora). Opgericht in 1990.
De STDH is opgericht met
als doel het
onderzoek op het gebied van de tekstcorpora en
databestanden in de humaniora te bevorderen en de kennis op
dit gebied te verbreiden. Het is de intentie om de website
van het STDH uit te bouwen tot een centraal informatiepunt
op het gebied van het corpusonderzoek in Nederland en
Vlaanderen. Ook wil de STDH de activitieiten op het gebied
van corpusonderzoek bundelen en coördineren.
Het gaat in alle drie de gevallen om kleine organisaties
(0.5 - 3 fte). Vaak worden ook de subsidies slechts voor een korte termijn
toegezegd (zoals in geval van CELEX).
Hoewel de meeste onderzoekscentra puur Nederlands, dan wel Vlaams
zijn, is er toch een gezamenlijk NEDERLANDS-VLAAMS initiatief,
namelijk het INL (Instituut voor Nederlandse Lexicologie), te Leiden.
Het INL is in 1969 opgericht. Relevant voor TST is de
INL-Taalbank. Ook participeert het INL in
Europese TST projecten, zoals PAROLE.
De belangrijkste onderzoeksprojecten op het gebied van de
TST waren in Nederland het NWO prioriteitsprogramma voor
Taal- en Spraaktechnologie (1995-2000) en in Vlaanderen het Korte
termijn programma voor Taal- en Spraaktechnologie (1994-1997).
Er zijn tot dusverre ook een paar gezamenlijke
onderzoeksinitiatieven geweest op het gebied van TST, namelijk
EUROTRA (1982-1993) en het
Corpus Gesproken Nederlands (1998-2003).
In Nederland houdt het NIWI (Nederlands Instituut voor
Wetenschappelijke Informatiediensten)
een databank bij met informatie over wetenschappelijk onderzoek
in Nederland. In Vlaanderen wordt dat gedaan in de IWETO-databank (Inventaris van het Wetenschappelijk en
Technologisch Onderzoek in Vlaanderen) door het Ministerie van de Vlaamse Gemeenschap, afdeling
Wetenschap en Innovatie (AWI).
In Nederland en in Vlaanderen kan aan alle universiteiten die in
de vorige sectie werden genoemd als onderzoekscentra ook in een
of andere vorm TST worden gestudeerd.
In Vlaanderen maken de taaltechnologische richtingen deel uit
van de Letterenfaculteiten, terwijl de spraaktechnologische
richtingen zijn ondergebracht bij Toegepaste Wetenschappen. In Nederland is er niet zo'n verdeling te maken. Daar zijn de meeste taal-
èn spraaktechnologische richtingen ontstaan binnen de
Letterenfaculteiten. In Delft, Eindhoven en Twente, de drie technische
universiteiten, is TST ondergebracht bij de Faculteit (Technische)
Informatica.
In Nederland kan men aan elk van de onderstaande universiteiten
een studie in een TST-richting volgen. Men moet in de meeste
gevallen eerst een propedeuse hebben afgelegd voor men kan overstappen.
- Amsterdam, UvA: Alfa-informatica (t), Fonetische Wetenschappen (s)
- Delft, TUD: Kennisgestuurde
Systemen (KGS) (s)
- Eindhoven, TUE: Mens-Systeem Interactie (postdoctoraal) (s)
- Groningen, RUG: Alfa-informatica (t), Technische Cognitie
Wetenschap (TCW) (t)
- Nijmegen, KUN: Taal, Spraak en Informatica (t)(s)
- Tilburg, KUB: Taal en Kunstmatige Intelligentie (t)
- Twente, UT: Linguistic Engineering (t) (s)
- Utrecht, RUU: Documentaire
Informatiekunde (t),
Taal- en
Spraakautomatisering (t)(s), Cognitieve Kunstmatige Intelligentie (CKI) (t)
De Nederlandse onderzoekscholen (zie vorige sectie) verzorgen ook
opleidingsprogramma's van AIO's, OIO's (Assistent in Opleiding,
respectievelijk Onderzoeker in Opleiding: afgestudeerden die aan een
proefschrift schrijven.), en bursalen. Dergelijke opleidingsprogramma's
kunnen de vorm hebben van cursussen waaraan
promovendi uit de aangesloten universiteiten deelnemen. Een
onderzoekschool kan zowel binnen een universiteit worden
opgericht als tussen meer universiteiten, soms ook samen met
andere onderzoeksinstellingen, bijvoorbeeld TNO.
In Vlaanderen kan men Taal- en Spraaktechnologie studeren
als postgraduaatstudie, zoals de Master of Artificial
Intelligence opleiding in Leuven. Aspecten van taal- en
spraaktechnologie komen ook aan bod in de GGS Taalwetenschap
(interuniversitair) en de GAS (Toegepaste) Informatica,
oriëntatie Computerlinguïstiek. Geen van de hier vermelde opleidingen is
vergelijkbaar met de opleidingen in Nederland. Daarnaast is het
soms mogelijk zich door middel van TST-keuzevakken
gedurende de ingenieurs- of licentiaatstudie iets te
specialiseren in spraak- of
taaltechnologie (bijvoorbeeld zwaartepunt Taaltechnologie,
Germaanse UIA of de module Taaltheorie en Computerlinguïstiek,
Germaanse Leuven). In al die gevallen gaat het om een relatief
beperkt aanbod van vakken.
Naast de universitaire opleiding is er dit jaar ook een
specialisatiejaar Taal en Informatica (deeltijd-opleiding,
1 jaar) gestart door de Katholieke Hogeschool
Zuid-West-Vlaanderen (KATHO), in samenwerking met Flanders
Language Valley. Het onderdeel Computerlinguïstiek wordt
door CLIF verzorgd.
De industrie vervult een rol zowel met betrekking tot het onderwijs als met
betrekking tot het onderzoek. Wat het onderwijs betreft gaat het vooral om
het aanbieden van stageplaatsen. Daarnaast kan de industrie ook een grote
rol vervullen met betrekking tot het aanbieden van het onderwijs zelf. Een
treffend voorbeeld is de opleiding die sinds vorig jaar wordt aangeboden door de Katholieke Hogeschool
Zuid-West-Vlaanderen (KATHO), in samenwerking met Flanders
Language Valley.2.7 Daarnaast speelt de
industrie idealiter een rol bij het invullen van de grote lijnen van de
TST-opleidingen.
Ook met betrekking tot het onderzoek speelt de industrie een rol, als
vragende partij ten opzichte van de universiteiten of, met hun eigen
onderzoeksafdeling, als partner van die universiteiten in
(nationale of Europese) onderzoeksprojecten.
Hieronder volgen een aantal van de bedrijven die in dit opzicht een rol
spelen in Nederland en Vlaanderen:
In Nederland wordt het beleid op het gebied van TST
voornamelijk bepaald door
- Ministerie van Onderwijs, Cultuur en Wetenschappen,
afdeling OWB (Onderzoek en Wetenschapsbeleid)
- Ministerie van Economische Zaken
- NWO, Nederlandse Organisatie voor Wetenschappelijk
Onderzoek
Onder NWO hebben een aantal onderdelen2.8 te maken met
TST:
- TAAL, SPRAAK EN LOGICA, een van de clusters uit
het gebied Geesteswetenschappen
- WSA (Wetenschappelijk
Statistisch Agentschap), een
agentschap onder het Gebiedsbestuur voor de Maatschappij- en
Gedragswetenschappen
- STW ( Stichting voor de
Technische Wetenschappen), een zelfstandig onderdeel van NWO.2.9 Het STW
vormt de divisie Technische Wetenschappen.
In Vlaanderen zijn bij TST de volgende instanties
betrokken:
- Ministerie van de Vlaamse Gemeenschap/Wetenschappelijk onderwijs
- Ministerie van de Vlaamse Gemeenschap/Admistratie
Wetenschap en Innovatie (AWI)
- Kabinet van minister-president Van den Brande
(Wetenschapsbeleid en Technologie)
- FWO-Vlaanderen (Fonds voor Wetenschappelijk Onderzoek-Vlaanderen)
- IWT (Vlaams Instituut voor de Bevordering van het
Wetenschappelijk-Technologisch Onderzoek in de Industrie)
Het FWO stimuleert en financiert het fundamenteel
wetenschappelijk onderzoek aan de universiteiten in de Vlaamse
Gemeenschap en aan de instellingen voor wetenschappelijk
onderzoek. Het stelt zich in dit opzicht strikter op dan de
Nederlandse zuster-organisatie, die bijvoorbeeld het PRIORITEIT- programma
Taal- en Spraaktechnologie heeft gefinancierd. Het Vlaamse Korte
termijn programma ter zake is op ad hoc basis door het IWT
begeleid.
Op Vlaams-Nederlands gebied zijn dan nog actief:
- NTU (Nederlandse Taalunie)
- CLVV, de Commissie Lexicale Vertaalvoorzieningen
- COTERM (terminologie)
- VNC, het Vlaams-Nederlands Comité voor
Nederlandse Taal en Cultuur.
De hier genoemde instanties laten ieder onderzoek op hun
specifieke gebied uitvoeren door derden.
Op Europees vlak zijn de programma's met betrekking tot TST
(MLIS, LE, ESPRIT)
ondergebracht bij het directoraat DG XIII van de Europese
Commissie. Daarnaast is er nog het EUREKA-initiatief dat
'market-driven' onderzoek en ontwikkeling stimuleert. De fondsen
komen van de nationale overheden, niet van de EG.
In een aantal landen levert de overheid grote inspanningen
ten behoeve van een goede infrastructuur voor Taal- en
Spraaktechnologie.
In Duitsland loopt al sinds 1993 (tot 2000) het
megaproject VERBMOBIL. In Denemarken en Griekenland
zijn nationale centra voor Taal- en Spraaktechnologie opgericht, het
Center for Sprogteknologi (CST) in Kopenhagen en het Institute
for Language and Speech Processing (ILSP) in Athene. Zij krijgen een
ruime betoelaging van de nationale overheid, althans
gedurende de eerste jaren. Naast het CST is er in Denemarken ook nog
de DSN (Dansk Sprognævn). Deze instantie houdt
zich bezig met taalplanning, terwijl het CST zich bezighoudt met
taaltechnologie.
Ook in Spanje is er een instituut opgericht, het Observatorio Español de Industrias de la
Lengua (OEIL) door het
Ministerio de Industria y Energía. Dit instituut in Madrid is
onderdeel van het Instituto Cervantes en moet zorgen dat alle noodzakelijk basisvoorzieningen aanwezig
zijn, het publiek voorlichten, TST-producten promoten,
en contact houden met allerlei Europese initiatieven.
Dit instituut verschilt van de beide hiervoor genoemde doordat
het zelf geen onderzoeksprojecten uitvoert.
Een instituut van weer een iets ander type is het Research
Institute for the Languages of
Finland (RILF).
Het is opgericht in 1976 om het beheer van een aantal reeds bestaande
instituten te coördineren en te centraliseren. Het houdt zich
momenteel bezig
met onderzoek naar alle talen die in Finland worden gesproken, met de
financiering van dergelijk onderzoek door derden, met het beheer van
archieven/databestanden (al dan niet in elektronisch formaat) en met
taaladviezen. Het RILF maakt deel uit van het Ministerie van Onderwijs.
Voor de Franstalige landen zijn een aantal instanties2.10 actief, waaronder
AUPELF UREF (Association des universités partiellement ou entièrement de
langue française - Université des réseaux d'expression
française) en RIOFIL
(Réseau International des Observatoires Francophones de l'Inforoute et
du Traitement Informatique des Langues).2.11
Meer op de Romaanse talen in het algemeen gericht is er de UNION
LATINE.
In het buitenland zijn er een aantal grote organisaties die zich
bezig houden met het verspreiden van (linguïstische) hulpbronnen, waaronder:
- BAS (Bavarian Archive for Speech Signals),
München. Het BAS heeft tot taak databases
gesproken Duits op optimale (gestandaardiseerde) wijze beschikbaar te
maken voor zowel wetenschap als industrie.
- CSLU (Center for Spoken Language Understanding),
Oregon.
Het CSLU verzamelt en verspreidt spraakcorpora voor alle
geïnteresseerden. Voor universiteiten zijn de corpora gratis
beschikbaar.
- DEUTSCHE
SPRACHARCHIV (DSAv),
Mannheim. Er worden 32 Duitstalige corpora beheerd, slechts een deel
daarvan is voor externe onderzoeksdoeleinden beschikbaar (onder meer
op juridische gronden).
- ELRA (European Language Resources Association),
Parijs. Naast het verzamelen en verspreiden van resources (zowel
taal, spraak als terminologie) beschouwt ELRA vooral ook het
valideren van resources als een belangrijke taak.
- LDC
(Linguistic Data Consortium), Pennsylvania. Anders dan ELRA
produceert het LDC ook zelf corpora, databanken, lexica en
andere hulpbronnen voor zowel onderzoek als ontwikkeling van producten.
- SPRÅKBANKEN (Bank of
Swedish) , Göteborg. De Språkbanken stelt zich tot taak
linguistische data in machinaal leesbare vorm te verzamelen.
- ICAME Corpus Collectie. Een verzameling corpora,
vooral Engelstalige.
Instanties als ELRA, LDC, BAS zijn voor een groot deel
afhankelijk van financiering door de overheid (ministeries,
onderzoeksfondsen, Europese fondsen).
Naast instellingen die het verspreiden van hulpbronnen tot doel hebben,
zijn er ook een aantal die vooral de eigen hulpbronnen ter beschikking
stellen. Een belangrijke is:
- BRITISH NATIONAL CORPUS (BNC). Een collectie van 100
miljoen woorden hedendaags Engels, zowel gesproken als geschreven
Wat de TST-opleidingen betreft, zijn er momenteel een aantal
interessante ontwikkelingen, waaronder, binnen het SOCRATES
programma, die voor een European Masters in Language and Speech, i.e. voor
een opleiding die èn Taaltechnologie èn Spraaktechnologie omvat. Het
gaat hier om een opleiding die in vele landen gevolgd kan worden, en die
door gezaghebbende, internationale organisaties als ESCA en
EACL zou moeten worden
erkend.
Belangrijke netwerken voor TST
zijn
De drie eerste zijn ESPRIT netwerken, de andere SOCRATES
netwerken. Er worden initiatieven ontplooit die op termijn mogelijk gevolgen
hebben voor de TST-infrastructuur in het Nederlandse
taalgebied. Ook zouden deze netwerken kunnen optreden als
partners bij het aanvragen van projecten, bijvoorbeeld voor een
basiscollectie taaltechnologische hulpmiddelen. Het BLARK (Basic LAnguage Resource Kit) initiatief van ELSNET en
ELRA is hiervan een voorbeeld. Het idee hier is dat er onder het
Vijfde Framework
Programma voor gezorgd zou moeten worden dat men in alle Europese (EG en CEE) landen kan beschikken over een een minimale set
hulpmiddelen, voorlopig gedefinieerd als een algemeen tekstcorpus om alle soorten precompetatief onderzoek te
kunnen verrichten, met een omvang van ongeveer 10 miljoen woorden,
geannoteerd volgens een algemeen geaccepteerde standaard,
iets soortgelijks voor een spraakcorpus, en
een collectie tools om met deze corpora om te kunnen gaan.
Andere internationale organisaties waarin
mensen die werkzaam zijn in de taal- en
spraaktechnologie zich hebben verenigd:
- ACL (Association for Computational Linguistics)
- EACL
(European Chapter of the Association for Computational Linguistics)
- EAMT (The European
Association for Machine Translation)
- ESCA
(European Speech Communication Association)
- EURALEX
(European Association for Lexicography)
- FOLLI
(European Association for Logic, Language and Information)
Binnen ACL zijn er een aantal voor TST relevante SIGs
(Special Interest Groups):
- SIGDAT (Special Interest Group for linguistic data
and corpus-based approaches to natural language processing)
- SIGLEX
- SIGMEDIA (Special Interest Group on Multimedia Language
Processing)
- SIGNLL ( Special Interest Group on Natural Language Learning)
- SIGPHON (Special Interest Group for Computational Phonology)
Nog zo'n SIG, maar dan door de EU gefinancierd is EAGLES
(Expert Advisory Group on Language Engineering Standards)
Een elektronische nieuwsbrief voor taal, spraak en logica wordt verspreid
door COLIBRI, informatie over
nieuwe TSTpublicaties
(al dan niet officieel) is te vinden in
CMP-LG (Computation and
Language E-Print Archive).
Tot slot nog enkele (organisatoren) van de belangrijkste conferenties en
zomerscholen op TST-gebied:
- COLING (International Conference on Computational Linguistics)
- ACL
- EACL
- ESCA
(European Speech Communication Association)
- ESSLLI (European Summer Schools in Logic, Language
and Computation)
- ELSnet
Volgende: 3. Evaluatie
Naar boven: De positie van het
Vorige: 1. Inleiding en Uitgangspunten
Bouma G.
1998-10-13