3. Voorbeeld: Pennsylvania, lexicale afstanden
In dit deel van de tutorial gaan we verder met de data van Pennsylvania.
De bestanden hiervoor heb je gedownload in
deel 2.
In het vorige deel van de tutorial werd een indeling gemaakt in dialecten op
basis van uitspraak door reeksen fonetische tekens met elkaar te
vergelijken. Nu maken we in indeling in dialecten op basis van woordkeus.
Als je naar fonetische verschillen kijkt, dan kun je zeer gedetailleerd de
verschillen vergelijken. Er zijn vele minieme uitspraakverschillen
mogelijk van een enkel woord, en woorden kunnen heel weinig
verschillen, in een enkele klank, of juist heel veel. Als je kijkt naar
woordkeus, dan is de variatie veel minder. Soms heb je maar twee
varianten. In het oostelijk deel van een gebied wordt de ene benaming
voor een bepaald vogeltje gebruikt, in het westelijk deel een andere
benaming. Daardoor kan de indeling in dialecten op basis van lexicale
vergelijkingen niet zo precies zijn als een indeling op basis van
fonetische vergelijkingen. Je hebt wel keus uit meer manieren om de
verschillen te bepalen.
3.1 Drie meetmethoden
We gaan de lexicale verschillen in Pennsylvania meten met drie verschillende
methoden.
- 1. Levenshtein-afstand
- Dit is de methode die je ook gebruikt hebt om fonetische afstanden te
bepalen. De afstand tussen twee reeksen tekens wordt bepaald door
hoeveel tekens binnen de strings van elkaar verschillen. Het lijkt
een beetje vreemd om dit hier te gebruiken, omdat je geen individuele
klanken binnen woorden met elkaar vergelijkt, maar complete woorden.
Maar je hebt niet alleen te maken met verschil in woordkeus ("varken"
of "zwijn"), maar ook met verschil in vervoeging van een woord
("varken" of "varkens"). In het eerste geval is het verschil groter
dan in het tweede geval. (Woordlengte heeft weinig invloed, omdat het programma
leven daarvoor normaliseert.)
- 2. Binaire verschillen
- Met deze methode kijk je alleen maar of woorden identiek zijn of niet.
- 3. Gewichteter Identitätswert (G.I.W.)
- Ook bij deze methode wordt alleen gekeken of woorden identiek zijn of niet,
zonder te letten op hoeveel twee woorden van elkaar verschillen,
maar daarnaast wordt er gekeken hoe vaak een woord in de totale
verzameling van woorden voorkomt.
Stel, je hebt een set woorden A, waarin onder andere de varianten
A' en A'' voorkomen. De afstanden worden als volgt
bepaald:
| Levenshtein | binair | G.I.W.
|
|---|
| verschil A' en A' | 0 | 0 | n' / n
|
| verschil A' en A'' | Levenshtein(A', A'') | 1 | 1
|
Hierin geldt:
- Levenshtein(A', A'') :
- de Levenshtein-afstand, de voordeligste manier om de ene tekenreeks om te
zetten in de andere
- n' :
- het aantal keer dat variant A' voorkomt in de groep A
- n :
- het totaal aantal woorden (niet alleen varianten) in groep A
Merk op dat je de binaire meting en G.I.W. niet kunt gebruiken voor het bepalen
van fonetische afstanden. Deze methoden gaan ervan uit dat er veel
identieke vormen voorkomen.
3.2 Lexicale afstanden
We bepalen de lexicale afstanden op drie manieren. Voor het meten van binaire
afstanden kun je hetzelfde programma gebruiken als voor het bepalen van
de Levenshtein-afstanden, door gebruik te maken van de optie
-B.
Voor het bepalen van de Gewichteter Identitätswert gebruik je het
programma
giw:
leven -n 67 -l PA.lbl -o lex-lev.dif lex/*.lex
leven -B -n 67 -l PA.lbl -o lex-bin.dif lex/*.lex
giw -n 67 -l PA.lbl -o lex-giw.dif lex/*.lex
Je hebt nu drie tabellen met lexicale verschillen. Maak op basis van deze
tabellen drie clusterkaarten, zoals je dat in deel 2 voor fonetische
afstanden hebt gedaan:
cluster -wm -o lex-lev.clu lex-lev.dif
cluster -wm -o lex-bin.clu lex-bin.dif
cluster -wm -o lex-giw.clu lex-giw.dif
mapclust -o map-lev.ps PA.cfg lex-lev.clu 4
mapclust -o map-bin.ps PA.cfg lex-bin.clu 4
mapclust -o map-giw.ps PA.cfg lex-giw.clu 4
Je zult zien dat de drie kaarten niet identiek zijn. Hoe bepaal je welke kaart
het beste is? Die vraag wordt behandeld in
deel 6 van de tutorial.
3.3 Multidimensional scaling
Multidimensional scaling (MDS) is een techniek om aan
de hand van een afstandstabel elementen zo te plaatsen dat de onderlinge
afstanden in verhouding zo goed mogelijk overeenkomen met de afstanden in
de oorspronkelijke afstandstabel. Je kunt MDS uitvoeren op het platte
vlak (twee dimensies), in de ruimte (drie dimensies), of een ander aantal
dimensies.
Met MDS kun je een leuk trucje uithalen. Eerst doe je MDS in drie dimensies,
waardoor aan elke plaats drie coördinaten worden toegewezen.
Hiervoor gebruik je het programma
mds. Het programma kent een paar
verschillende methodes, waarvan Kruskal's Method
(optie: -K) gewoonlijk de beste resultaten geeft.
De drie coördinaten gebruik je vervolgens als kleurcomponenten (rood,
groen en blauw) om elke plaats een unieke, samengestelde kleur te
geven. Dit doe je met het programma maprgb.
Hieronder is een voorbeeld gegeven voor de fonetische verschillen uit
deel 2. Doe zelf hetzelfde voor de lexicale
verschillen.
mds -K -o fon.vec 3 fon.dif
maprgb -o map3.ps PA.cfg fon.vec
Dit is de kaart die je krijgt:
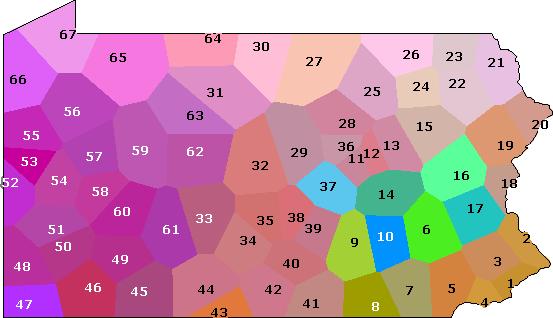
MDS-kaart van fonetische afstanden
Deze kaart laat dingen zien die niet te zien waren in de
clusterkaart. Links
zie je een gebied waar de kleuren sterk op elkaar lijken (het cyaankleurige
gebied op de clusterkaart). Dit duidt erop dat de dialectverschillen binnen het
gebied relatief klein zijn. Rechts zie je een klein gebied dat er nogal
uitspringt met grote contrasten (het blauwe gebied op de clusterkaart). Binnen dit
gebied zijn de verschillen groter.
Evenals de clusterkaart heeft de MDS-kaart z'n nadelen en beperkingen.
Dit wordt
elders
besproken.
Als je de uitvoer van het programma
mds wilt importeren in software die geen deel
uitmaakt van
RuG/L04, dan kun je het met het programma
vec2tab omzetten in een formaat
dat vrij algemeen wordt gebruikt.
3.4 MDS en clusters
In de rest van dit deel wordt
mdsplot gebruikt, een
programma dat op dit moment nog niet beschikbaar is
als losstaand C-programma, maar alleen als Perl-script. Dat betekent dat je
Perl nodig hebt om het te kunnen gebruiken. Voor Windows kun je bijvoorbeeld
ActivePerl downloaden.
Download het script:
mdsplot
Voor Unix: verander de eerste regel van het script voor de juiste lokatie van
Perl op je computer. Maak het script executable.
Voor Windows: wanneer hieronder in voorbeelden het commando mdsplot
gebruikt wordt, vervang dat dan door
perl mdsplot
(en zorg ervoor dat perl in je PATH staat).
We gaan nog even verder met de fonetische afstanden uit het
deel 2 van de
tutorial en vergelijken die met de lexicale verschillen uit dit deel.
3.4.1 Fonetische verschillen
We doen MDS in twee dimensies, en laten het resultaat in een diagram zien,
waarbij we elke plaats de kleur geven van de groep waarin de plaats
door clustering was ingedeeld. Voor de fonetische verschillen ziet dat
er zo uit:

Fonetische afstanden
Zo'n afbeelding als hierboven maak je met
mdsplot.
Dit programma leest alle opties uit een configuratiebestand. Het volgende
bestand bevat alle opties om bovenstaande afbeelding te maken:
mdsplot.cfg
Download bovenstaand bestand, en geef dan het volgende commando:
mdsplot mdsplot.cfg
Het resultaat is de afbeelding die je hierboven ziet.
Wat kun je zien in bovenstaande afbeelding? Het blauwe cluster bestaat uit
slechts zes plaatsen, maar neemt een groot deel van de ruimte in. Dat
betekent dat deze zes plaatsen nogal sterk verschillen van de rest, en
omdat ze ook onderling ver uit elkaar liggen verschillen ze ook sterk
van elkaar.
Dit soort diagrammen zijn een bruikbaar hulpmiddel bij het toetsen van een
clustering en het kiezen van de juiste clustermethode. Dit wordt
elders
toegelicht.
3.4.2 Fonetische verschillen, een subset
Laten we het blauwe cluster eens verwijderen, en de rest nader bekijken. We
verwijderen de zes punten uit de data, en passen op de overgebleven
punten opnieuw MDS toe. Dit gaat als volgt in z'n werk. Kopieer het bestand
mdsplot.cfg naar
mdsplot2.cfg, en open de kopie met een
tekstbewerker. In dat bestand maak je een aantal veranderingen. Verander de
naam van het bestand waarin het resultaat terecht komt:
outfile: mdsplot2.ps
Verander hoe de plaatsen worden weergegeven:
markers: clnums
Bewaar het bestand, en geef het commando:
mdsplot mdsplot2.cfg
Bekijk het resultaat. Je ziet dat plaatsen nu niet meer worden weergegeven met
hun eigen plaatsnummer, maar met een nummer van het cluster waartoe ze
behoren. Je ziet dat blauw nummer 1 is. Dit betekent dat je MDS wilt
toepassen op alleen de plaatsen uit clusters 2, 3 en 4. Bewerk de kopie van
configuratiebestand verder. Herstel de manier waarop plaatsen worden
weergegeven:
markers: numbers
En geef aan welke groepen je wilt hebben:
plot: 2 3 4
Bewaar het bestand, en geef opnieuw het commando:
mdsplot mdsplot2.cfg
Het resultaat is zoals hieronder:

Fonetische afstanden, drie van de vier clusters
Je kunt hierboven zien dat de drie overgebleven groepen redelijk goed van
elkaar gescheiden zijn, en dus daadwerkelijk als drie aparte dialectgebieden
aan te wijzen zijn.
3.4.3 Fonetische verschillen vergeleken met lexicale verschillen
Nu gaan we MDS toepassen op de lexicale afstanden, en dan eens kijken wat er
met de clusters gebeurt die we gevonden hebben voor fonetische afstanden. Om
dit te zien geven we elke plaats dezelfde kleur als bij de fonetische
afstanden.
Kopieer het oorspronkelijke configuratiebestand mdsplot.cfg naar
mdsplot3.cfg en open het met een tekstbewerker. Verander de
naam van het bestand waarin het resultaat wordt opgeslagen:
outfile: mdsplot3.ps
We gebruiken nu een tabel met lexicale verschillen:
diffile: lex-lev.dif
We veranderen de clustermethode. In plaats van intern te clusteren gebruiken we
een groepsindeling uit een extern bestand:
cluster: idx
idxfile: fon.idx
Bewaar het configuratiebestand.
Maak een groepsindeling gebaseerd op fonetische afstanden, en bewaar dat in een
apart bestand (zie manpage clgroup):
clgroup -i -n 4 -o fon.idx fon.clu
En maak een nieuwe afbeelding:
mdsplot mdsplot3.cfg
Het resultaat zie je hieronder:
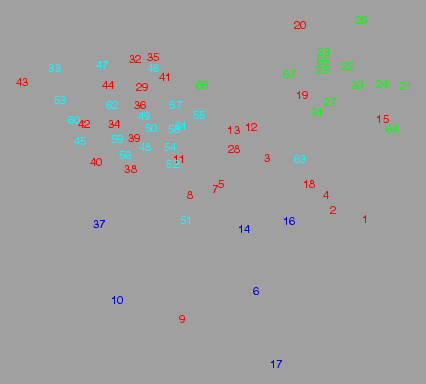
MDS van lexicale verschillen, clusterkleuren van fonetische verschillen.
Wat opvalt in bovenstaande afbeelding is dat de rode en cyaankleurige plaatsen
door elkaar staan. Met fonetische metingen was een onderscheid tussen twee
dialecten te zien dat bij lexicale metingen niet meer terug is te vinden.