Hieronder zie je de kaart van Pennsylvania, verdeeld in 67 gemeenschappen. Elke gemeenschap heeft een nummer. Deze nummers vind je terug in de database van LAMSAS, voorafgegaan door de letters PA, als Informant ID Number (informid).
Hieronder zie je de kaart van Pennsylvania, verdeeld in 67 gemeenschappen. Elke gemeenschap heeft een nummer. Deze nummers vind je terug in de database van LAMSAS, voorafgegaan door de letters PA, als Informant ID Number (informid).
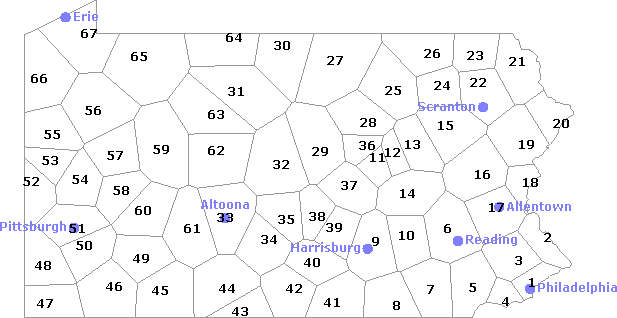
Pennsylvania, VS, verdeeld in 67 gemeenschappen.
1 Philadelphia Co. 18 Northampton Co. 35 Mifflin Co. 52 Beaver Co. 2 Bucks Co. 19 Monroe Co. 36 Union Co. 53 Lawrence Co. 3 Montgomery Co. 20 Pike Co. 37 Snyder Co. 54 Butler Co. 4 Delaware Co. 21 Wayne Co. 38 Juniata Co. 55 Mercer Co. 5 Chester Co. 22 Lackawanna Co. 39 Perry Co. 56 Venango Co. 6 Berks Co. 23 Susquehanna Co. 40 Cumberland Co. 57 Clarion Co. 7 Lancaster Co. 24 Wyoming Co. 41 Adams Co. 58 Armstrong Co. 8 York Co. 25 Sullivan Co. 42 Franklin Co. 59 Jefferson Co. 9 Dauphin Co. 26 Bradford Co. 43 Fulton Co. 60 Indiana Co. 10 Lebanon Co. 27 Tioga Co. 44 Bedford Co. 61 Cambria Co. 11 Northumberland Co. 28 Lycoming Co. 45 Somerset Co. 62 Clearfield Co. 12 Montour Co. 29 Clinton Co. 46 Fayette Co. 63 Elk Co. 13 Columbia Co. 30 Potter Co. 47 Greene Co. 64 McKean Co. 14 Schuylkill Co. 31 Cameron Co. 48 Washington Co. 65 Warren Co. 15 Luzerne Co. 32 Centre Co. 49 Westmoreland Co. 66 Crawford Co. 16 Carbon Co. 33 Blair Co. 50 Allegheny Co. 67 Erie Co. 17 Lehigh Co. 34 Huntingdon Co. 51 Pittsburgh Adams Co. (41) Clinton Co. (29) Lancaster Co. (7) Pittsburgh (51) Allegheny Co. (50) Columbia Co. (13) Lawrence Co. (53) Potter Co. (30) Armstrong Co. (58) Crawford Co. (66) Lebanon Co. (10) Schuylkill Co. (14) Beaver Co. (52) Cumberland Co. (40) Lehigh Co. (17) Snyder Co. (37) Bedford Co. (44) Dauphin Co. (9) Luzerne Co. (15) Somerset Co. (45) Berks Co. (6) Delaware Co. (4) Lycoming Co. (28) Sullivan Co. (25) Blair Co. (33) Elk Co. (63) McKean Co. (64) Susquehanna Co. (23) Bradford Co. (26) Erie Co. (67) Mercer Co. (55) Tioga Co. (27) Bucks Co. (2) Fayette Co. (46) Mifflin Co. (35) Union Co. (36) Butler Co. (54) Franklin Co. (42) Monroe Co. (19) Venango Co. (56) Cambria Co. (61) Fulton Co. (43) Montgomery Co. (3) Warren Co. (65) Cameron Co. (31) Greene Co. (47) Montour Co. (12) Washington Co. (48) Carbon Co. (16) Huntingdon Co. (34) Northampton Co. (18) Wayne Co. (21) Centre Co. (32) Indiana Co. (60) Northumberland Co. (11) Westmoreland Co. (49) Chester Co. (5) Jefferson Co. (59) Perry Co. (39) Wyoming Co. (24) Clarion Co. (57) Juniata Co. (38) Philadelphia Co. (1) York Co. (8) Clearfield Co. (62) Lackawanna Co. (22) Pike Co. (20)
PA.zip
Unzip de data. Je krijgt dan de volgende directory's:
PA/
PA/fon/
PA/lex/
De directory PA/ bevat de volgende bestanden:
| PA.cfg | Configuratie voor het tekenen van kaarten |
| PA.clp | Deelbestand voor kaarten |
| PA.coo | Coördinaten (longitude/latitude) en namen van plaatsen |
| PA.geo | De grens van Pennsylvania |
| PA.lbl | Nummers en namen van plaatsen |
| PA.map | Deelbestand voor kaarten |
| PA.trn | Deelbestand voor kaarten |
De directory PA/fon/ bevat bestanden met data over de uitspraak. In deze set zijn alleen varianten van uitspraak opgenomen. Varianten in woordkeus zijn weggelaten. In tegenstelling tot de andere bestanden zijn deze bestanden niet gewoon te lezen, omdat er een codering voor een specifiek font gebruikt is. De inhoud van al deze bestanden samen is in een leesbare vorm opgenomen in het volgende PDF-bestand (met regelnummers toegevoegd):
phonetic.pdf
De directory PA/lex/ bevat bestanden met data over de woordkeus. Deze bestanden zullen pas in deel 3 van deze tutorial worden gebruikt.
Voor de meting gebruiken we het programma leven. Alle details over het gebruik van dit programma vind je in de leven manpage.
Ga eerst naar de directory PA:
cd PA
Bereken daarna de verschillen door het volgende commando te gebruiken:
leven -n 67 -l PA.lbl -o fon.dif fon/*.fon
cluster -wm -o fon.clu fon.dif
We kunnen het resultaat van de clustering zichtbaar maken in een dendrogram,
door het volgende commando te gebruiken (zie manpage
den):
den -o dendrogram.ps fon.clu
Het resultaat is een afbeelding die in het bestand dendrogram.ps is
opgeslagen.
Je kunt het uiterlijk van het dendrogram aanpassen door opties te gebruiken:
den -b .1 -C -e .3333 -n 4 -o dendrogram.ps -p fon.clu
Het resultaat is gelijk aan het dendrogram dat je hieronder ziet afgebeeld,
maar zonder plaatsnummers. Zie de manpage voor de betekenis van alle
opties. Een enkele optie, -e .3333 wordt
hier toegelicht. Clustering met Ward's Method
heeft als effect dat wanneer het gebied twee keer zo groot wordt, de
afstanden niet twee, maar acht keer zo groot worden. (Andere
clustermethoden hebben dat niet.) Je kunt dit corrigeren door de
afstanden te verheffen tot de macht 1/3 (want 8 tot de macht 1/3 is 2),
zodat de verhoudingen in het
dendrogram de werkelijke afstanden reflecteren. Aan de x-as onder het
dendrogram kun je zien dat de afstanden zijn aangepast.
mapclust -o map.ps PA.cfg fon.clu 4
Het resultaat wordt bewaard in het bestand map.ps, en ziet er uit zoals
de kaart hieronder:
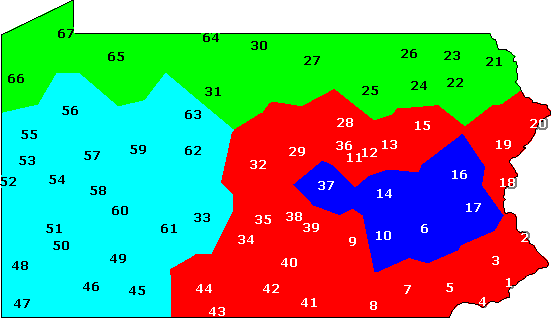
Clustering in vier groepen, gebaseerd op fonetische afstanden.
De meeste opties die bepalen hoe de kaart er uit komt te zien staan in een configuratiebestand. Dat is het eerste bestand dat je als argument meegeeft aan het programma mapclust, of een van de andere programma's waarmee kaarten worden getekend.
Kopieer het configuratiebestand PA.cfg naar PA2.cfg, en open de kopie met een tekstbewerker. Alle regels in dat bestand die beginnen met een hekje (#) zijn commentaar, en worden genegeerd. De rest zijn opties. Zoek de optie markers, en verwijder daarachter het woord number. Hierdoor zullen geen plaatsnummers meer in de kaart verschijnen. Maak nu een nieuwe kaart met:
mapclust -b -s -o map2.ps PA2.cfg fon.clu 4
En maak een bijpassend dendrogram met:
den -Q -b .1 -e .3333 -n 4 -o dendro2.ps fon.clu
Zie de manpages voor mapclust
en den voor de opties op de commandline, en
de aparte manpage voor de opties in het
configuratiebestand.
