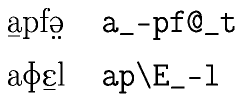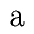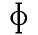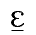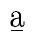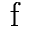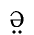Data waarmee het een ander wordt gedemonstreerd is nog niet aanwezig. Zodra dat
wel het geval is zal de tekst op deze pagina worden bijgewerkt.
Het Levenshtein-algoritme in de eenvoudigste vorm vergelijkt twee reeksen
lettertekens waarbij het er alleen toe doet of twee lettertekens hetzelfde zijn
of niet. Wanneer je afstanden wilt bepalen op basis van fonetische verschillen dan valt
er wel wat te verbeteren. Je wilt dan klankreeksen met elkaar
vergelijken. Er is weliswaar een relatie tussen een klankreeks en de reeks
letters waarmee die klankreeks is opgetekend, waardoor je met een simpele
Levenshtein-meting een goede indruk kunt krijgen van dialectverschillen (zie
deel 2 van deze tutorial), maar het is niet de
nauwkeurigste methode die denkbaar is.
Er spelen twee dingen:
- Een klank wordt vaak niet opgetekend met een enkel teken, maar met een
reeks van tekens.
- De mate waarin twee klanken verschillen kan nogal variëren.
Hieronder staan twee woorden, links opgetekend in fonetisch schrift, rechts de
transcriptie in X-Sampa, een codering die bruikbaar is om fonetisch schrift met
een gewoon toetsenbord in te voeren, zonder gebruik te maken van een
tekenset die afwijkt van het simpele US-ASCII. (zie:
IPA/X-SAMPA chart by Andrew Mutchler)
Beide woorden bestaan uit een reeks van vier klanken, maar zijn in
elektronische vorm opgeslagen als reeksen van acht en zeven tekens, in dit
voorbeeld met één tot drie lettertekens per klank. Niet alleen accenten
worden gecodeerd door extra tekens toe te voegen, ook basisklanken zelf
worden nogal eens met meer dan één teken gecodeerd, zoals de combinatie
p\ voor de tweede klank in het onderste woord.
Wat er gebeurt als je deze twee reeksen in deze vorm met elkaar vergelijkt met
het Levenshtein-algoritme zie je in onderstaand diagram. (zie ook:
Levenshtein-demonstratie)
De eerste stap om te komen tot een nauwkeuriger meting is het opdelen van de
reeks lettertekens in tokens. Elke groep van letters die staat voor één fonetisch
basisteken of voor één accent wordt samengevoegd. Hiervoor kun je het programma
xstokens gebruiken.
Hoe na de samenvoeging de
Levenshtein-vergelijking verloopt kun je hieronder zien:
Helaas is het in dit geval nog geen verbetering. Je zult nog een stap verder
moeten gaan.
Klanken hebben allerlei kenmerken. Je zou kunnen zeggen dat hoe meer kenmerken
tussen twee klanken van elkaar verschillen, hoe groter het verschil is tussen
die twee klanken. In plaats van klanken als eenheid met elkaar te vergelijken,
zou je de klank kunnen opsplitsen in een reeks kenmerken, en dus reeksen van kenmerken
met elkaar vergelijken.
Klinkers verschillen onder andere van elkaar door de plaats in de mond van
het hoogste deel van de tong: voorin, in het midden, of achterin. Je kunt
deze plaats coderen als een reeks van twee tokens:
| tong | codering
|
|---|
| voor | Ta1 Tb1
|
| midden | Ta0 Tb1
|
| achter | Ta0 Tb0
|
Een voor-klinker verschilt dan met één token van een midden-klinker, en met
twee tokens van een achter-klinker.
Hetzelfde kun je doen voor positie van de kaak:
| kaak | codering
|
|---|
| gesloten | Ka1 Kb1 Kc1
|
| half gesloten | Ka0 Kb1 Kc1
|
| half open | Ka0 Kb0 Kc1
|
| open | Ka0 Kb0 Kc0
|
En voor de stand van de lippen:
| lippen | codering
|
|---|
| gerond | L1
|
| niet gerond | L0
|
Dan wordt een enkele klank vervangen door een hele reeks tokens, bijvoorbeeld de "i":
i: Ta1 Tb1 Ka1 Kb1 Kc1 L0
| | | | | |
| | | | | +---> niet gerond
| | | | |
| | +---+---+---> gesloten
| |
+---+---> voor
Dit verschilt maar weinig (1 token) van de "y":
y: Ta1 Tb1 Ka1 Kb1 Kc1 L1
| | | | | |
| | | | | +---> gerond
| | | | |
| | +---+---+---> gesloten
| |
+---+---> voor
Maar het verschil met de "o" is een stuk groter (4 tokens):
o: Ta0 Tb0 Ka0 Kb1 Kc1 L1
| | | | | |
| | | | | +---> gerond
| | | | |
| | +---+---+---> half gesloten
| |
+---+---> achter
Al dit soort hercoderingen van fonetische transcripties kun je
uitvoeren met het programma xstokens,
waarna je gewoon het programma leven kunt
gebruiken om de verschillen te meten.
Deze methode is redelijk eenvoudig, en is nauwkeuriger dan een simpele Levenshtein-meting
direct op de oorspronkelijke tekenreeksen. Maar perfect is het niet:
- Hoe zwaar een bepaalde eigenschap weegt wordt bepaald door het aantal
tokens waarin je die eigenschap codeert. Je moet dus zien de juiste balans te
vinden.
- De codering van basisklanken in combinatie met de codering van accenten kan
onvoordelig uitpakken. Stel, je hebt een voor-klinker met een accent "ietsje naar
achteren" en een midden-klinker met een accent "ietsje naar voren". Deze twee
klanken staan dichter bij elkaar dan vergelijkbare tekens zonder deze accenten,
maar in deze meting zal het verschil juist groter uitvallen dan wanneer de
accenten er niet waren.
- De gecodeerde reeksen zijn een flink stuk langer dan de oorspronkelijke
reeksen, en het aantal berekeningen nodig voor het bepalen van de
Levenshtein-afstand tussen twee reeksen is evenredig met het product van de lengte van
de twee reeksen, dus de complete meting kan erg tijdrovend worden.
We gaan nog een stap verder. We splitsen een reeks letters in basisklanken en
accenten, en voegen daarna elke basisklank met bijbehorende accenten
samen in één token. Een simpele Levenshtein-meting op basis van zulke tokens
verloopt zo:
Twee reeksen van elk vier klanken, een geen van de klanken uit het ene woord
komt overeen met een klank uit het andere woord, dus de gemeten afstand is
maximaal. Dat is niet wat we willen. We willen dat een substitutie van twee
ongelijke klanken niet de maximale afstand geeft, maar een afstand die
gebaseerd is op de verschillen van beide klanken. Zoals hieronder:
Je ziet eerst de vergelijking van twee a-klanken, dan de verwijdering van een p, dan
de vergelijking van twee soorten f-klanken, dan de vergelijking tussen
twee e-achtige klanken, en tenslotte de invoegen van een l.
De procedure om tot zo'n meting te komen bevat de volgende stappen:
- Het maken van een nauwkeurige omschrijving van tokens en hun bijbehorende
eigenschappen, en hoe de eigenschappen van accenten combineren met de
eigenschappen van basisklanken.
- Het omzetten van de dialectbestanden waarbij elke reeks tekens (basisklank
plus accenten samen) die
een unieke klank beschrijven wordt vervangen door een uniek token.
- Het bepalen van afstanden tussen tokens op basis van hun verschillen in
eigenschappen (fonetische features). Stap 2 en 3 worden
door het programma features
uitgevoerd op basis van de definitie die je in stap 1 hebt
gemaakt.
- Het bepalen van Levenshtein-afstanden met het programma
leven van de opnieuw gecodeerde
dialectgegevens, gemaakt in stap 2, waarbij de afstanden tussen
tokens die in stap 3 zijn berekend worden gebruikt.
Stap 1 is helaas niet eenvoudig. Of deze procedure lonend is hangt deels af van de
conditie van de data. Je kunt streven naar een wetenschappelijk zo verantwoord
mogelijke definitie van features en feature-vergelijkingen, maar wanneer de data niet
zeer zorgvuldig is verzameld, als er teveel ruis in zit, dan heeft het geen zin
om hier nog tot het uiterste te gaan.