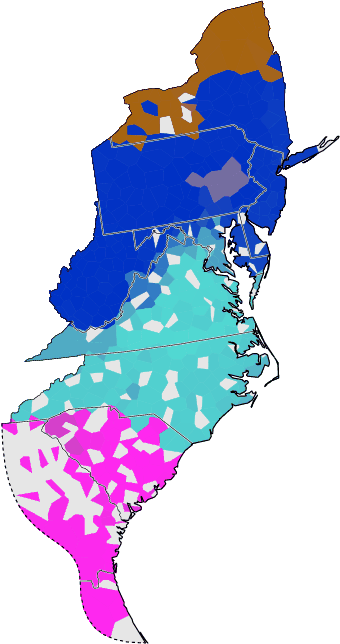
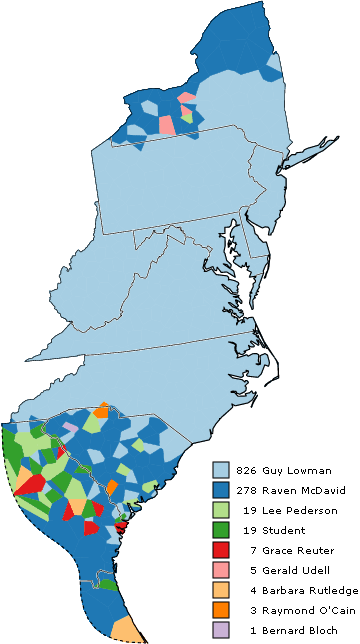
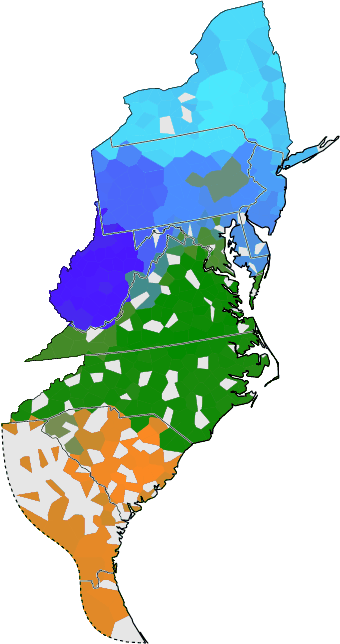
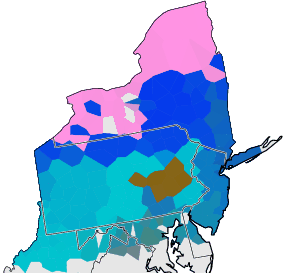
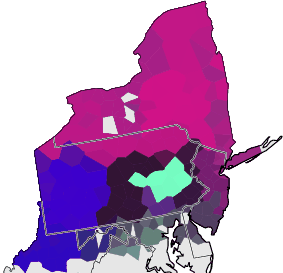
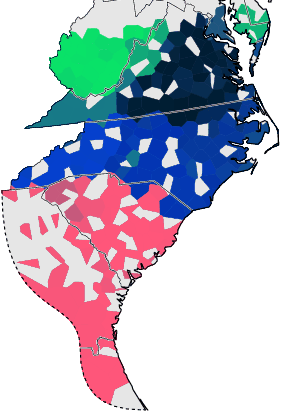
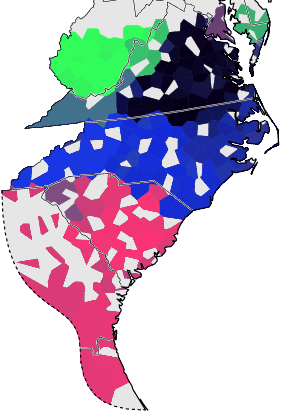
Fieldworker effect
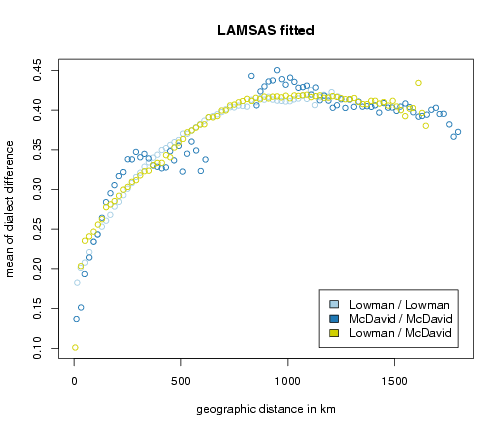
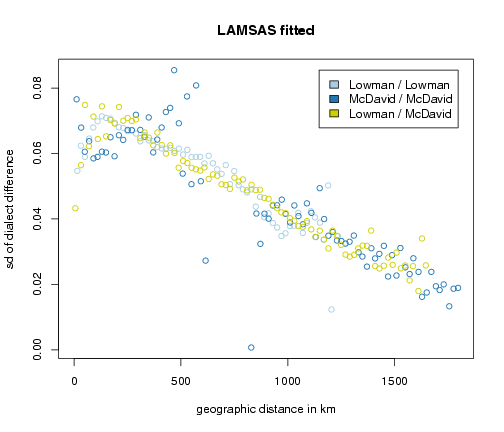
Fitting
This page describes an attempt to compensate for the fieldworker effect.
data: raw phonetic strings, no lexical variants
subset: fieldworkers: Lowman, McDavid
worksheets: Middle Atlantic, South Atlantic
1030 informants
grouping: fieldworker + worksheet + community: 461 locations
(two locations merged because of identical coordinates)
method: Levenshtein
maps: stochastic clustering, group average + weighted average,
followed by classical MDS on cophenetic differences
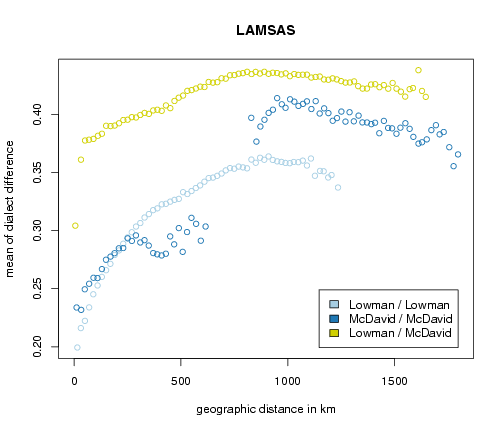
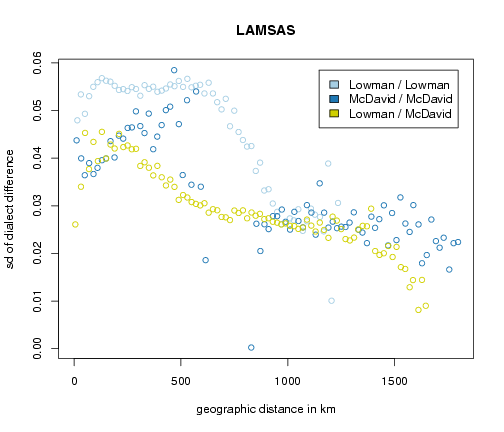
The plot below shows the average phonetic difference as a function of geographic distance. There are three sets of differences: differences within data collected by Lowman, differences within data collected by McDavid, and differences between data from Lowman and data from McDavid.
The phonetic differences between Lowman data and McDavid data is consistently higher than differences within each set of data. This strongly suggest that Lowman and McDavid transcribed identical sound in a different manner.