 |
The NWO Priority Programme Language and Speech Technology is a research programme aiming at the development of spoken language information systems. Its immediate goal is to develop a demonstrator of a public transport information system, which operates over ordinary telephone lines. This demonstrator is called OVIS, Openbaar Vervoer Informatie Systeem (Public Transport Information System). The language of the system is Dutch. Refer to [3,16] for further information of this Programme.
 |
The natural language understanding component of OVIS analyses the output of the speech recognizer (a word graph) and passes this analysis to the dialogue manager (as an update expression). Word graphs are weighted acyclic finite-state automata which represent in a compact format the hypotheses of a speech recognizer. Each path through the word graph is a possible analysis of the user utterance; weights indicate the confidence of the speech recognizer.
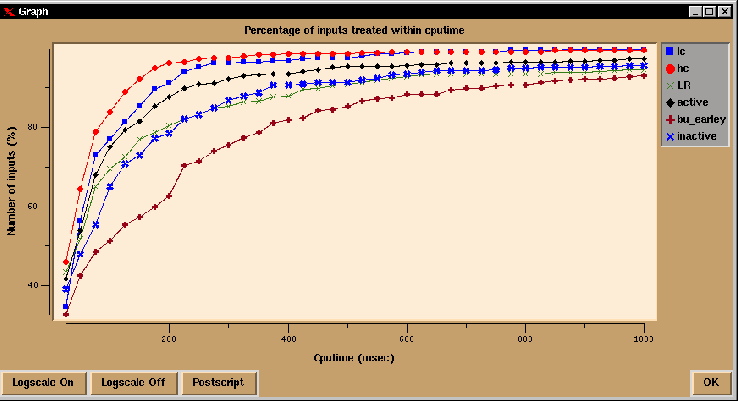
The relation between such word graphs and update expressions is defined by means of a Definite Clause Grammar of Dutch. This DCG and a number of parsers have been developed with the Hdrug system. The functionality of Hdrug has been used to compare the different parsers with respect to efficiency on sets of sentences and word graphs. For example, upon loading a specific set of such word graphs, the system can be asked to parse each of the word graphs with a specified subset of the available parsers, and to display information concerning parse times and memory usage for each of those parsers. For example, figure 5 is the result of a test run of 5000 word graphs for four different parsers. For slower parsers it is useful to implement a time-out to make sure that test sets can be treated within a reasonable amount of time. In such cases mean cputime does not make sense; therefore, it is also possible to obtain a graph in which the percentage of inputs that can be completed within a certain amount of cputime is displayed. This is supported in Hdrug as well; an example is given in figure 6. Similar support is provided for the analysis of a given test-set of sentences with respect to input size and with respect to the number of readings assigned.
The functionality of Hdrug has been extended in various ways for the OVIS application. For example, a procedure has been implemented which can be used to generate random sentences, as a means to find errors in the grammar. The menu bar is extended with a new menu-button which provides an interface to this new feature. Incorporating such new features in the user interface is very straightforward.
Furthermore, similar to the VIEW menu of Ale it is also possible to obtain visualisation of datastructures such as lexical entries and grammar rules. This menu also provides an interface for the visualisation of word graphs by piping these word graphs to either the VCG [12] or dotty [6] graph drawing tools.
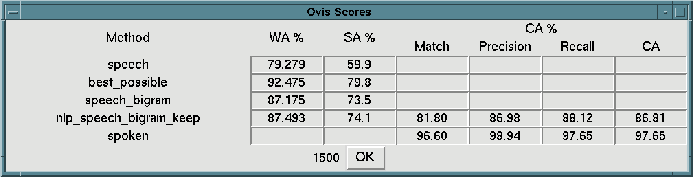
Apart from adding new menu buttons it is also easy to add items to existing pull-down menus. For example, in OVIS we are not only interested in the speed of the parser, but also in the accuracy. A component has been implemented which measures word accuracy, sentence accuracy and concept accuracy (by comparing the results of analysis with a given annotation). This functionality is available through a number of new items on the TEST-SUITE menu. If a test suite has been loaded, then we can use this component to measure word accuracy and sentence accuracy of a number of difference analysis methods. Information is displayed in a window which is updated every now and then (the interval can be set by the user). Such an information window looks as in figure 7.
 |