

Next: Parsing word-graphs
Up: Robust parsing of word-graphs
Previous: Robust parsing of word-graphs
The input to the NLP module consists of word-graphs produced by the
speech recogniser [33]. A word-graph is a compact
representation for all sequences of words that the speech recogniser
hypothesises for a spoken utterance. The states of the graph represent
points in time, and a transition between two states represents a word that
may have been uttered between the corresponding points in time. Each
transition is associated with an acoustic score representing a measure
of confidence that the word perceived there was
actually uttered. These scores are negative logarithms of
probabilities and therefore require addition as opposed to
multiplication when two scores are combined. An example of a typical
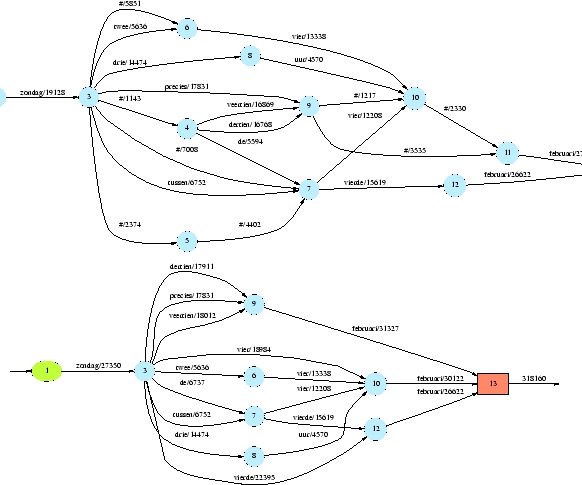
word-graph is given as the first graph in figure 19.
At an early stage, the word-graph is normalised to eliminate the
pause transitions. Such transitions represent periods of time for
which the speech recogniser hypothesises that no words are uttered.
After this optimisation, the word-graph contains exactly one start
state and one or more final states, associated with a score,
representing a measure of confidence that the utterance ends at that
point. The word-graphs in figure 19 provide an example.
From now on, we will assume word-graphs
are normalised in this sense. Below, we refer to transitions in the
word-graph using the notation
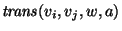 for a
transition from state vi to vj with symbol w and acoustic
score a. Let
for a
transition from state vi to vj with symbol w and acoustic
score a. Let
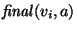 refer to a final state vi with
acoustic score a.
refer to a final state vi with
acoustic score a.
Figure 19:
Word-graph and normalized word-graph
for the utterance Zondag vier
februari (Sunday Februari fourth). The special label #
in the first graph indicates a pause transition. These transitions
are eliminated in the second graph.
 |
Next: Parsing word-graphs
Up: Robust parsing of word-graphs
Previous: Robust parsing of word-graphs
2000-07-10