The grammar for OVIS2 contains the grammatical knowledge required to analyse a word graph and to determine what the meaning of the utterance corresponding to the word graph is.
Ideally, in order to construct such a grammar one would take a general-purpose computational grammar of Dutch, and adapt it to the current domain and application. Unfortunately, however, we do not know of any computational grammar for Dutch that could easily be adapted to the present task (which, among others, requires processing of spoken language, extensive coverage of locative and temporal expressions, and the construction of fine-grained semantic representations).
The OVIS-grammar is being developed especially for the purposes of this project. On the one hand this has the advantage that the grammar can be tailored to the specific requirements of the present project. On the other hand, we want to adopt general solutions as much as possible, as this increases the chances that the grammar can be used in other domains as well. Thus, in designing the grammar we seek a balance between short-term goals (a grammar which covers utterances typical for the OVIS-domain and is reasonably robust and efficient) and long-term goals (a grammar which covers the major constructions of Dutch in a general way).
The grammar currently covers some of the more common verbal subcategorization types (intransitives, transitives, verbs selecting a PP, and modal and auxiliary verbs), NP-syntax (including pre- and postnominal modification, with the exception of relative clauses), PP-syntax, the distribution of VP-modifiers, various clausal types (declaratives, yes/no and WH-questions, and subordinate clauses), all temporal expressions and locative phrases relevant to the domain, and various typical spoken language constructs.
From a linguistic perspective, the OVIS-grammar can be characterized as a constraint-based grammar, which makes heavy use of lexical information. The design of the grammar was inspired to a certain extent by Head-driven Phrase Structure Grammar (HPSG) [18].
The OVIS-grammar formalism is essentially equivalent to Definite Clause Grammar (DCG) [17]. The choice for DCG is motivated by the fact that this formalism provides a balance between computational efficiency and linguistic expressiveness, and the fact that it is closely related to constraint-based grammar formalisms, such as HPSG, Categorial Unification Grammar, and Lexical Functional Grammar. Another important reason to choose DCG instead of a more restricted formalism such as context-free grammar, is the fact that DCG allows the kind of integration of syntax and semantics that is standard in constraint-based formalisms such as HPSG.
Grammar rules consist of a context-free skeleton to which feature-constraints are added. The context-free skeleton is important, as it ensures a reasonable level of processing efficiency and facilitates experimentation with different parsing techniques.
The central formal operation in constraint-based grammar formalisms is unification of (typed or untyped) feature-structures [19]. The OVIS-formalism employs typed feature-structures in the definition of rules as well as lexical entries. During the construction of the parser, feature-structures are translated into Prolog terms. Because of this translation step, parsing can make use of Prolog's built-in term-unification, instead of the more expensive feature-unification.
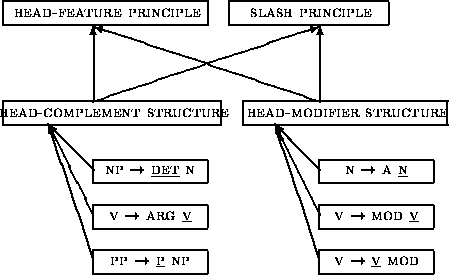
As in HPSG, generalizations about rules are captured by means of
principles. For instance, most rules introduce a kind of head-complement or head-modifier structure. Both structures
inherit from the head-feature principle (which states that the
HEAD-features of the head-daughter and the mother must be
unified) and the slash-principle (which governs the percolation
of the feature SLASH, used to account for
unbounded-dependencies). Figure 2 illustrates part of the
rule hierarchy. An arrow from a box A to a box B indicates that
A inherits information from B, where inheritance amounts to
unification. In the rules shown in figure 2, the
underlined daughter is the head of the rule. Note that we assume that
DET is the head of NP. The rules V
Note that the OVIS-grammar does not use the general
rule-schemata of HPSG and thus there is no need for linear
precedence statements. On the other hand, the requirement that all
rules must have a context-free skeleton implies that the number of
rules is larger than in most HPSG fragments. As the
rule-set is structured as an inheritance network, this does not give
rise to unacceptable redundancy.
As is the case in most lexicalist grammar formalisms,
subcategorization is handled lexically. Thus, all major categories
(verbs, nouns, prepositions, and determiners) have a feature
SUBCAT, whose value is the list of complements they subcategorize
for. Expressing this information lexically, instead of using more
detailed syntactic rules, has the advantage that idiosyncratic
subcategorization requirements need not
be stated in the rules
(such as the restriction that denken (to think), if it selects a PP-complement,
requires this complement to be headed by
aan (about); or the fact that komen (to come)
may combine with the particle aan (the combination of which
means to arrive)). Similarly, all constraints having to do
with case marking and agreement can be expressed lexically. Finally,
the semantic relation between a head and its dependents can be
expressed lexically.
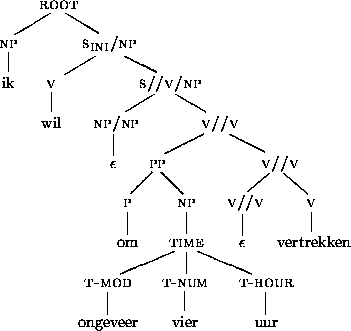
Figure 3 illustrates the grammatical analysis for ik wil
om ongeveer vier uur vertrekken (I want to leave
around four o'clock).
The subject ik combines with a verb-initial clause missing an
NP (indicated as S
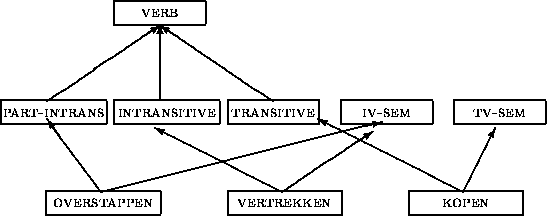
Lexicalist grammar formalisms tend to store lots of syntactic
information inside the lexicon. To avoid massive reduplication of
identical information in the lexicon, the use of inheritance is
essential. A fragment of the lexical inheritance hierarchy is shown in
figure 4. The lexical entry for a verb such as vertrekken
(to leave) is defined in terms of the templates intransitive and iv-sem; intransitive in its turn is
defined in terms of a template verb, which defines the
properties common to all verbs.
Lexical rules provide another means for capturing lexical
generalizations. While inheritance can be used to express information
present in various lexical entries succinctly, lexical rules are used
to express relations that are of an implicational nature (if a lexical
entry satisfies constraints C, it is valid to infer the existence of
a lexical entry
C
Temporal expressions occur very frequently in the OVIS
domain. It is therefore essential that the grammar provides extensive
coverage of these expressions. Some examples of temporal expressions
of category NP covered by the grammar are presented in below.
These expressions can be combined with prepositions such as op
(on), om (at), voor (before), na (after) to form a temporal
expression of category PP.
At the moment, the grammar of temporal expressions is accounted for in
a separate module of the grammar. Thus, the general principles which
hold for other parts of the grammar (such as the head-feature principle
and the slash principle) need not apply within this module. We believe
that such an approach is motivated by the fact that the grammar of
temporal expressions contains many idiosyncrasies (such as the fact
that drie uur combines a singular noun with a plural numeral, or
the fact that vijf over drie combines two numerals and a
preposition) which seem to be limited to this type of expression
only. Note that this does not imply that no principled account of the
syntax of temporal expressions could be given (see
[10] for instance). However, as
general principles of the grammar do seem to play only a minor role in the
grammar of temporal expressions, we are satisfied with providing a few
simple, but idiosyncratic, rules and lexical entries to account for
these expressions.
The output of the grammatical analysis is a semantic, linguistically
motivated and domain-independent, representation of the
utterance. This representation is translated into one or more domain-specific
updates, which are passed on to the pragmatic interpretation
module and dialogue manager (DM) for further processing. Below,
we motivate our choice for quasi logical forms (QLF's) as
semantic representation language and we discuss how these forms are
translated into updates.
Predicate logic is often used to represent the meaning of sentences.
Due to its long tradition in describing semantics of natural languages
it is now a well-established and well-understood technique.
Nevertheless, it often seems helpful to extend the predicate calculus
with more advanced techniques, such as generalised quantifiers
or discourse markers. For OVIS we use the QLF-formalism [1], whose most important feature is that
it makes extensive use of underspecification to represent ambiguities.
A property of artificial languages like predicate logic is
that they are unambiguous. An ambiguous natural language utterance
will therefore correspond with more than one expression in predicate
logic, one for each reading of the utterance. The disadvantage of this
approach is that for very ambiguous inputs, expensive computations
must be carried out to compute all readings.
The alternative adopted in the QLF-formalism is to represent
ambiguity by means of underspecification and to postpone the
computation of all possible readings to the disambiguation component.
A QLF is a description of one or more predicate logical
formulas. While building a QLF
for an utterance, information is added monotonically
[8]. Whenever information is added, the amount of
underspecification will decrease and, consequently, the resulting QLF
will describe a smaller set of logical formulas. After grammatical
processing of an utterance is completed, several knowledge
sources (such as an algorithm for generating quantifier scope or
for finding referents for anaphoric expressions) may be used to
further reduce the amount of underspecification.
In figure 5 we give the (simplified) QLF which the
current grammar produces for the example in
figure 3. Remember that the grammar manipulates
feature-structures, so the QLF is represented as a feature-value
matrix. Note that the arguments of the predicates willen and vertrekken are (generalized) quantifiers that are unscoped with
respect to each other. Furthermore, we assume that verbs introduce an
(existentially quantified) event-variable.
The QLF in figure 5 represents the
domain-independent meaning of the utterance. If we want to reuse the
present grammar for other domains, or for extensions of the present
domain, it is essential to have representations that are not based on
domain-specific assumptions.
Representing ambiguity by means of
underspecification is particularly important in the present setting,
as the system must deal with highly ambiguous input (i.e. word
graphs). Furthermore, it turns out to be the case that the computation
of the domain-specific meaning of an utterance can be carried out without
resolving all the sources of ambiguity in the QLF for that utterance.
For instance, the
scope of quantifiers seems to be to a large extent irrelevant for the
computation of (domain-specific) updates, and thus a
representation in which quantifier-scope is undetermined is sufficient
for our purposes.
The dialogue manager (DM) expects the linguistic module to
produce so-called updates representing the domain- and
context-specific meaning of the user-utterance. The DM keeps track of
the information provided by the user by maintaining an
information state or form. This form is a hierarchical
structure, in which there are slots for the origin and destination of
a connection, for the time at which the user wants to arrive or leave,
etc. Updates specify the values of these slots. For example, the QLF in figure 5 is translated into the following update:
As the user responds to the system's questions, responses will usually
not be a complete sentence, but an NP or PP, or a sequence
of such constituents. In such cases, the QLF produced by the
grammar will be severely underspecified. An update can be constructed,
however, by adding information from the question to the semantic
representation of the answer. The response in (b), for
instance, can be translated into the update in (c) by taking
into account the fact that this was a response to the question in
(a).
The Lexicon
![]() ). At the moment, lexical rules are used to
encode inflectional morphology and, to a limited extent, to account for
unbounded dependencies.
). At the moment, lexical rules are used to
encode inflectional morphology and, to a limited extent, to account for
unbounded dependencies.
The Grammar of Temporal Expressions
a.
drie januari
January, 3
b.
de derde (januari)
the third (of January)
c.
maandag, maandagmiddag
Monday, Monday afternoon
d.
overmorgen
the day after tomorrow
e.
drie uur, drie uur vijftien
three o'clock,
three fifteen
f.
kwart over drie
quarter past three
g.
vijftien minuten over (drie)
fifteen minutes past (three)
Semantics
The semantic representation language
Domain-specific interpretation
a.
Naar welk station wilt u vanuit Groningen reizen?
To which station do you want to travel from Groningen
b.
Amsterdam
Amsterdam
c.
userwants.travel.destination.place[=Amsterdam]
![]()
![]()
![]()
Next: Parsing
Up: Grammatical Analysis in a
Previous: Introduction
Noord G.J.M. van
1998-09-25
![\includegraphics[width=\textwidth]{qlf.ps}](img7.png)