In this section, I will present a simple variant of a head driven, bottom-up generator, called BUG, which was originally described in [97], and shares many characteristics with the approaches presented in [12], [86] and [87]. These generation algorithms are characterized by a bottom-up style of processing, where top-down prediction is applied through the use of the notion `(semantic)-head'. Bottom-up processing can be motivated from the desire to use lexical information to guide the search, as much as possible. Head-driven processing can be motivated by the desire to use the semantics (the input) as an important source of information to guide the search.
I require that all non-unit rules have a head. Moreover, the logical form of this head must be identical with the logical form of the mother node; i.e. the mother node and the head share their logical form. Note, that for each non-unit rule in the Dutch example grammar, it is possible to choose a daughter as the head, that satisfies this requirement. As before, the head of the rule will be the first element of the list of daughters in the representation used by the meta-interpreter. Lexical entries are represented, for the meta-interpreter, as rules with an empty list of daughters.
The algorithm BUG proceeds as follows. Its input will be some node N that is associated with some semantic structure S. First BUG tries to find the lexical head, a lexical entry of which the semantics unifies with S. This part is called the prediction step. Now, BUG is going to build from this lexical head larger units as follows. It selects a rule of which the head unifies with the lexical head. The other daughters of this rule are generated recursively. For the mother node of this rule, this procedure will be repeated: selecting a rule of which the head unifies with the current node, generate the daughters of this rule and connect the mother node upward. This part of the algorithm ends if a mother node has been found that unifies with node N. This is defined in figure 3.8.
As an example, consider what happens if this algorithm is activated by the following query (again, I leave the empty verb out of consideration for the moment):
![\begin{displaymath}
\prologq \mbox{\it bug}(\avm[\mbox{\rm C}]{ \mbox{\it cat}:\...
...\
\mbox{\it sem}:\mbox{\rm omdat(vertelt(arie,leugens))}
}).
\end{displaymath}](img222.png)
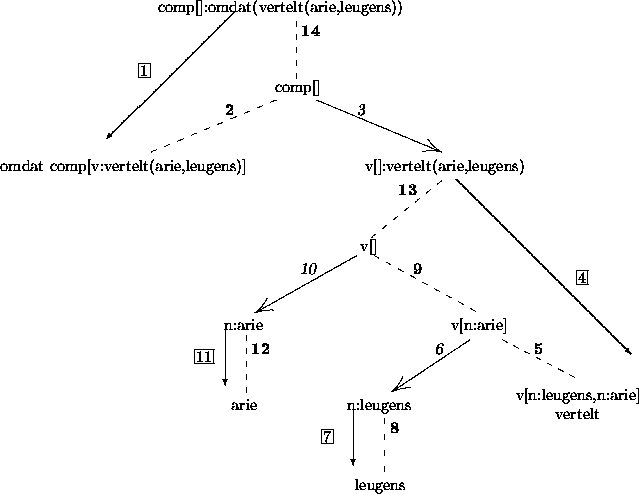
In figure 3.9 the flow of control of the generation process is illustrated. The integers refer to the steps in the generation process. Framed integers on arrows with a small arrow head represent prediction steps, bold face integers on dashed lines represent connection steps, and slanted integers on arrows with a large arrow head represent recursive generation steps.
Firstly, the clause predict_head will select the lexical head, a lexical entry with a logical form that unifies with ` omdat(vertelt(arie, leugens))'. The definition of omdat (rule 8) is the only candidate (step 1). The prediction step instantiates this entry into:

It is important to note here, that not only the semantics of the lexical
entry is instantiated, but also the semantics of the element on its
subcategorization list. This entry needs to be connected upwards to
the top-goal. To this end a rule is selected of which the head unifies with
the feature structure of the complementizer. Rule 7
clearly is the only candidate (step 2). The next goal, therefore, is to
generate the non-head daughter of this rule (3). Because of the
subcategorization technique, this non-head daughter is unified with
the element of the subcat list of the head. Therefore, the semantics
of this non-head daughter is instantiated as well:
![\begin{displaymath}\avm[\mbox{\rm T}]{
\mbox{\it cat}: \mbox{\rm vp}\\ \mbox{\i...
...rm vertelt(arie,leugens)}\\ \mbox{\it v2}:
\mbox{\rm no\_v2} }
\end{displaymath}](img225.png)
Again, the algorithm predicts a lexical entry for this goal. The
definition for vertelt (rule 3) is a possible
candidate, obtaining the following feature structure (step 4):
![\begin{displaymath}\avm[\mbox{\rm S}]{
\mbox{\it cat}: \mbox{\rm vp} \\ \mbox{\i...
...m vertelt} \vert \mbox{\rm P}_{2} \rangle - \mbox{\rm P}_{2} }
\end{displaymath}](img226.png)
Note again, that the logical form of the elements of
the subcat list of this entry get instantiated as a result of the
unification of the logical form of the goal, and the logical form of the
verb.
The feature structure S is going to be connected to T by the sem_head clauses. To be able to connect the lexical VP to (ultimately) the saturated VP node, a rule will be selected of which this lexical verb phrase can be the head. Rule 1 is a possible candidate (5). If this rule is selected, the following feature structure represents the non-head daughter of the rule (again with instantiated semantics):
![\begin{displaymath}
\avm[\mbox{\rm D}]{ \mbox{\it cat}: \mbox{\rm np} \\ \mbox{\...
...ns} \\
\mbox{\it phon}: \mbox{\rm P}_{1} - \mbox{\rm P}}_{2}
\end{displaymath}](img227.png)
The mother of the rule is instantiated as:
![\begin{displaymath}
\avm[\mbox{\rm M}]{
\mbox{\it cat}: \mbox{\rm vp} \\
\mbox...
...m vertelt} \vert \mbox{\rm P}_{1} \rangle - \mbox{\rm P}_{2}
}
\end{displaymath}](img228.png)
The daughter
D is generated recursively (6, 7, 8), instantiating
P1 - P2 into
![]() leugens|P3
leugens|P3![]() - P3. Therefore the next task is to connect
- P3. Therefore the next task is to connect
![\begin{displaymath}
\avm[\mbox{\rm M}]{
\mbox{\it cat}: \mbox{\rm vp} \\
\mbox...
...rm vertelt}\vert \mbox{\rm P}_{3} \rangle - \mbox{\rm P}_{3}
}
\end{displaymath}](img229.png)
upwards to the saturated verb phrase
T. Again it is possible to
choose rule 1 (step 9). In this case, the non-head daughter of the
rule consists of the feature structure that results in the phonology
`arie' by a recursive application of BUG (10, 11, and 12);
hence the mother node of this instantiation of rule 1 will become:
![\begin{displaymath}
\avm[{\mbox{\rm M}}_{2}]{
\mbox{\it cat}: \mbox{\rm s} \\
...
...m vertelt} \vert \mbox{\rm P}_{3} \rangle - \mbox{\rm P}_{3}
}
\end{displaymath}](img230.png)
This node can easily be connected to the top node
T by the
first clause for sem_head, because it can be unified with the
top node (step 13);
thereby finishing the generation goal of the argument of the
complementizer. The resulting complementizer phrase can also be
connected trivially to the ultimate top goal
C (14); the answer to
the query, therefore, is:
![\begin{displaymath}\avm[\mbox{\rm C}]{
\mbox{\it cat}: \mbox{\rm comp} \\
\mb...
...m vertelt} \vert \mbox{\rm P}_{6} \rangle - \mbox{\rm P}_{6}
}
\end{displaymath}](img231.png)
As another example, consider the case where the logical form is built in a semantically non-monotonic way:

Again, the generation process can be illustrated as in figure 3.10.
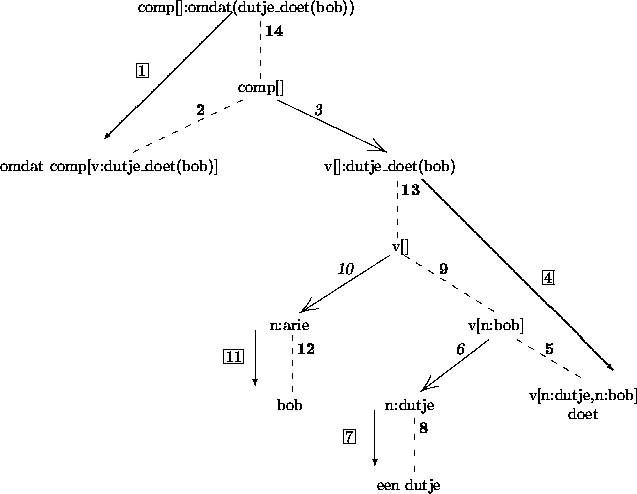 |
After the selection of the complementizer rule 7, the generator again tries to generate a saturated verb phrase recursively. For this generation goal, the predictor step selects the lexical entry doet (rule 13), after which the generator will try to connect the verb phrase:

to the saturated verb phrase goal, as in the foregoing example (step 5
in the illustration). Note,
that the semantics of the two elements of the subcat list of `doet'
both are instantiated. Hence the algorithm proceeds exactly as in the
preceding example, generating `een dutje' and `bob' both recursively.
This results in the correct answer:

The algorithm BUG defines a simple bottom-up head-driven generation procedure. Note that the search is guided by the input because of the definition of the predict step. The definition of this step uses the knowledge that heads always share the logical form with their mother (remember this is how we defined the notion `head'). Therefore, for any given top-goal it is possible and correct to share this information with the `lexical head' immediately. The resulting system implements, therefore, an attractive compromise between bottom-up and top-down approaches; the order of processing is bottom-up, but there is an important information flow in top-down direction. Furthermore the recursive bug calls also provide for an important flow of information in top-down direction especially in the case of rules that dominate subcategorized-for elements as in the verb phrase rule 1. Later in this chapter I discuss extensions to BUG, for grammars in which other ways to construct semantic structures are assumed.
Note that the order of processing of the algorithm is not left-to-right, but bi-directionally because the algorithm always starts from the head of a rule. The logical form of this head is always known by the prediction step. This constitutes the top-down information of the algorithm. Apart from the top-down logical form information, the algorithm is directed by the information of the lexicon because the order of processing is bottom-up. Head driven bottom-up generators are thus geared towards the semantic content of the input on the one hand and lexical information on the other hand. Of course this is especially useful for grammars that are written in the spirit of lexicalistic linguistic theories such as CUG, UCG and HPSG.
Apart from considerations of efficiency the major reason for constructing bottom-up generators has been the left-recursion problem summarized in section 3.3. If the base case of the recursion resides in the lexicon the bottom-up approach does not face these problems. Typically in grammars that are based on the lexicalist theories mentioned above, these cases occur frequently, but are handled by BUG without any problems: the subcat lists are sufficiently instantiated to restrict the otherwise unlimited search.
[18] define a grammatical formalism (called `Lexical Grammars') in which the use of subcategorization lists and lexical construction of semantics as sketched above, is built in. This enables them to ensure, that generation terminates for grammars in which each of the lexical entries are defined in such a way, that the semantic structures of each of the elements on the subcat list is `smaller' than the semantic structures of the lexical entry itself. The generation algorithm discussed here always terminates for this class of grammars.
Some possible extensions and some problems of BUG are discussed in the next sections.