I will restrict the attention to a class of constraint-based
formalisms, in which operations on strings are defined that are more
powerful than concatenation, but which operations are restricted to be
non-erasing, and linear. The resulting class of systems
has an obvious relation to Linear Context-Free Rewriting Systems
(LCFRS), [107], except for the addition of constraints. For a
discussion of the properties of LCFRS without feature-structures, see
[107] and [110]. We will not discuss these
properties, as these properties do not carry over to the current
system. The proposals discussed in the previous section can be seen
as examples of linear and non-erasing constraint-based grammars.
As in LCFRS, the operations on strings are characterized as follows. First, derived structures will be mapped onto a string of words; i.e. each derived structure `knows' which string it `dominates'. For example, each derived feature structure may contain an attribute `string' of which the value is a list of atoms representing the string it dominates. I will write w(F) for the set of occurrences of words that the derived structure F dominates. Rules combine structures D1...Dn into a new structure M. Non-erasure requires that the union of w applied to each daughter is a subset of w(M):
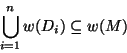
Linearity requires that, for each rule, the difference of the
cardinalities of these sets is a constant factor; i.e. a rule may only
introduce a fixed number of words syncategorematically:
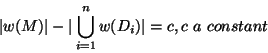
CF-based formalisms clearly fulfill this requirement, as do Head
Grammars, grammars using sequence union, Johnson's Australian grammar,
and TAG's. Unlike in the definition of LCFRS I do not require that
these operations are operations in the strict sense, i.e. the
operations do not have to be functional, nor do I require that these
operations are defined as operations on sequences of strings. Note
that sequence union is relational; the others are functional. For a
discussion of the consequences of this difference, cf.
[73].
Furthermore, I will assume that some rules have a designated daughter, called the head. Although I will not impose any restrictions on the head, it will turn out that the parsing strategy to be proposed will be very sensitive to the choice of heads, with the effect that grammars in which the notion `head' is defined in a systematic way (Pollard's Head Grammars, Reape's version of HPSG, Dowty's version of Categorial Grammar), may be much more efficiently parsed than other grammars. The notion head corner of a parse tree is defined recursively in terms of the head. The head-corner of a node without a head (eg. a frontier node) will be this node itself. The head corner of a node with a head, will be the head corner of this head node.
Remember that a grammar is a set of definite clauses, defining the relation `sign'. Hence a grammar rule will be something like
![]()
where ![]() are constraints on the variables.
However, to make the ways in which strings are combined explicit, I
will allow that a rule is associated with an extra
relation-call
cp/2 (for `construct-phonology), of which the arguments
are resp. the mother node, and the sequence of daughter nodes.
This extra relation is thought of as defining how the
string of the mother node is built from the strings of the daughters.
are constraints on the variables.
However, to make the ways in which strings are combined explicit, I
will allow that a rule is associated with an extra
relation-call
cp/2 (for `construct-phonology), of which the arguments
are resp. the mother node, and the sequence of daughter nodes.
This extra relation is thought of as defining how the
string of the mother node is built from the strings of the daughters.
For example, to implement a simple grammar rule using concatenation, we may write
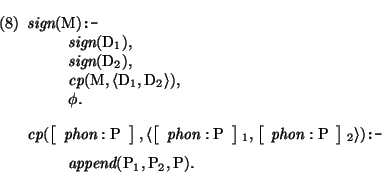
where the relation `cp' states that the string of the mother is the
concatenation of the strings of the daughters. The extra relation
should be defined in such a way that given the instantiated daughter
signs, the extra relation is guaranteed to terminate (assuming the
procedural semantics defined in chapter 2). Thus, we
think of the definition of such extra predicates as an (innocent)
sub-program.
Furthermore, each grammar should provide a definition of the predicate head/2 and yield/2. The first one defines the relation between the mother sign of a rule and its head; the second one defines the phonology (as a list of atoms) associated with a sign.
Finally, for each rule it should be known which terminals are introduced by it.
A rule
sign(Mother):-sign(D1)...sign(Dn),cp(...),![]() . which consumes words
Words, and which has no head, is called a `non-chain-rule',
and is represented as follows:
. which consumes words
Words, and which has no head, is called a `non-chain-rule',
and is represented as follows:
![\pr\pred
\head{\mbox{\it ncr}(\mbox{\rm Mother},[\mbox{\rm D}_{1} \dots \mbox{\r...
...{ ~\mbox{\it cp}(\dots) ~\}],\mbox{\rm Words}) \mbox{\tt :-} \phi .}
\epr\epred](img292.png)
Note that lexical entries are non-chain-rules of which the list of daughters
is presumably the empty list. Also note that the call to the relation
`cp' is added to the list of daughters.
A rule
sign(Mother):-sign(D1)...sign(Di),sign(Head),sign(Di + 1)...Dn,cp(...),![]() .
with head
Head, and which consumes words
Words, is
called a `chain-rule', and is represented for the meta-interpreter as
follows (hence we allow for terminal symbols to be introduced
syncategorematically):
.
with head
Head, and which consumes words
Words, is
called a `chain-rule', and is represented for the meta-interpreter as
follows (hence we allow for terminal symbols to be introduced
syncategorematically):
![\pr\pred
\head{\mbox{\it cr}(\mbox{\rm Head},\mbox{\rm Mother},[\mbox{\rm D}_{1}...
...
\{~ \mbox{\it cp}(\dots)~\}],\mbox{\rm Words}) \mbox{\tt :-} \phi.}
\epred\epr](img293.png)