This situation has already been exemplified in section 4 fig. 1. In this example, parsing of S (`Remove the folder with the system tools') has lead to two readings LF' and LF''. The multiple semantic forms are then paraphrased by means of the utterances S' and S'' (`Do you mean ``Remove the folder by means of the systems tools'' or ``Remove the folder that contains the system tools''?').
is computed. Now LF' and LF'' are respectively given as input to the generator to compute possible paraphrases. The sets{(S, LF'), (S, LF'')}
and{(LF', S'), (LF', S)}
result. By means of comparison of the elements of the sets obtained during generation with the set obtained during parsing one can easily determine the two paraphrases S' and S'' because of the relationship between strings and logical forms defined by the grammar. Note that if this relationship is effectively reversible (see section 2) then this problem is effectively computable.{(LF'', S), (LF'', S'')}
This `generate-and-test' approach is naive because of the following reasons. Firstly, it assumes that all possible paraphrases are generated at once. Although `all-parses' algorithms are widely used during parsing in natural language systems a corresponding `all-paraphrases' strategy is not practical because in general the search space during generation is much larger (which is a consequence of the modular design discussed in section 3). Secondly, the algorithm only guarantees that an ambiguous utterance is restated differently. It is possible that irrelevant paraphrases are produced because the source of the ambiguity is not used directly.
In order to be able to take into account the source of ambiguity obtained during parsing the basic idea of the proposed approach is to generate paraphrases along `parsed' structures. Suppose that parsing of an utterance has yielded two interpretations LF' and LF'' with corresponding derivations trees d1 and d2. It is now possible to generate a new utterance for each logical form LFi by means of the monitored generation algorithm described in the previous section. In this case, the corresponding derivation tree di of LFi is marked by means of the others. The so marked tree is then used to `guide' the generation step as already known.
The predicate find_all_parse computes all possible parses of a given string Str, where TreeSet are all corresponding derivation trees extracted from the set of the parsed structures SignSet. If the parser obtains multiple interpretations then for each element of SignSet a paraphrase has to be generated. This is done by means of the predicate generate_paraphrases, whose definition will be given below. All computed Paraphrases are then given to the user who has to choose the appropriate paraphrase. The corresponding logical form of the chosen Sign determines the result of the paraphrasing process. For each parsed sign of the form sign(LF,Str,Syn,D) a paraphrase is generated in the following way: First its derivation tree D is marked by means of the set of derivations trees contained in TreeSet. The resulting marked derivation tree Guide is then used in order to guide the generation of the sign's logical form LF using the predicate mgen. Note, that this directly reflects the definition of the predicate revision, which definition was given in the previous section. Therefore we can simply specify the definition of the predicate generate_paraphrases as follows: generate_paraphrases([Sign|ParsedSigns], TreeSet, [Paraphrased|T]):- revision(Sign,TreeSet,Paraphrased), !, % one alternative for each reading generate_paraphrases(ParsedSigns, TreeSet, T).

the parser has determined the derivation trees
in figure 4 with corresponding (simplified) semantic representations:
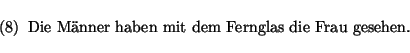
is generated in the same way described in section 5.
In this case the left tree of figure 4 is marked by means of the
right one.
In order to yield a paraphrase for the second reading, the right derivation tree of figure 4 is marked by means of the left one. In this case markers are placed in the right tree at the nodes named `pp_mod' and `gesehen'. If the grammar allows to realize `mit(frau, fernglas)' using a relative clause then the paraphrase

is generated.
Otherwise, the markers are pushed up successively to the root node `topic' of
that tree yielding the paraphrase:

Now, the produced paraphrases are given to the user who has to choose the appropriate one. In the current implementation this is simply done by entering the corresponding number of the selected paraphrase.

is ambiguous because it is not clear who developed the program.
If a paraphrase is to be generated, which expresses that the student developed
the program, then this can be done by means of the utterance:

But this utterance has still the same ambiguity. This means, that
one has to check also the ambiguity of the paraphrase. An unambiguous
solution for the example is, e.g., the utterance:

The advantage of our approach is that only one paraphrase for each interpretation is produced and that the source of the ambiguity is used directly. Therefore, the generation of irrelevant paraphrases is avoided.
Furthermore, we do not need special predefined `ambiguity specialists', as proposed by [Meteer and Shaked1988], but rather use the parser to detect possible ambiguities. Hence our approach is much more independent of the underlying grammar.