Below is a map of Pennsylvania, divided into 67 communities. Each community has a number. These numbers are the same as the numbers of the Informant ID Number (informid) used in the LAMSAS database, where they are prefixed with the letters PA.
Below is a map of Pennsylvania, divided into 67 communities. Each community has a number. These numbers are the same as the numbers of the Informant ID Number (informid) used in the LAMSAS database, where they are prefixed with the letters PA.
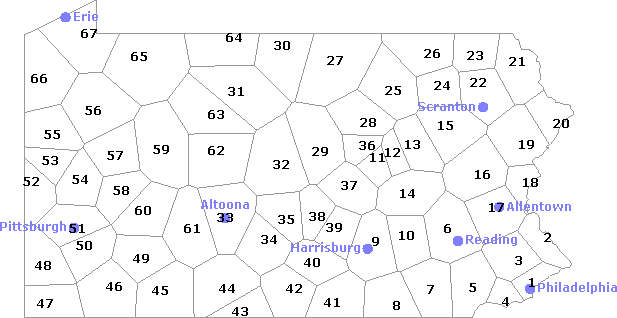
Pennsylvania, USA, divided into 67 communities.
1 Philadelphia Co. 18 Northampton Co. 35 Mifflin Co. 52 Beaver Co. 2 Bucks Co. 19 Monroe Co. 36 Union Co. 53 Lawrence Co. 3 Montgomery Co. 20 Pike Co. 37 Snyder Co. 54 Butler Co. 4 Delaware Co. 21 Wayne Co. 38 Juniata Co. 55 Mercer Co. 5 Chester Co. 22 Lackawanna Co. 39 Perry Co. 56 Venango Co. 6 Berks Co. 23 Susquehanna Co. 40 Cumberland Co. 57 Clarion Co. 7 Lancaster Co. 24 Wyoming Co. 41 Adams Co. 58 Armstrong Co. 8 York Co. 25 Sullivan Co. 42 Franklin Co. 59 Jefferson Co. 9 Dauphin Co. 26 Bradford Co. 43 Fulton Co. 60 Indiana Co. 10 Lebanon Co. 27 Tioga Co. 44 Bedford Co. 61 Cambria Co. 11 Northumberland Co. 28 Lycoming Co. 45 Somerset Co. 62 Clearfield Co. 12 Montour Co. 29 Clinton Co. 46 Fayette Co. 63 Elk Co. 13 Columbia Co. 30 Potter Co. 47 Greene Co. 64 McKean Co. 14 Schuylkill Co. 31 Cameron Co. 48 Washington Co. 65 Warren Co. 15 Luzerne Co. 32 Centre Co. 49 Westmoreland Co. 66 Crawford Co. 16 Carbon Co. 33 Blair Co. 50 Allegheny Co. 67 Erie Co. 17 Lehigh Co. 34 Huntingdon Co. 51 Pittsburgh Adams Co. (41) Clinton Co. (29) Lancaster Co. (7) Pittsburgh (51) Allegheny Co. (50) Columbia Co. (13) Lawrence Co. (53) Potter Co. (30) Armstrong Co. (58) Crawford Co. (66) Lebanon Co. (10) Schuylkill Co. (14) Beaver Co. (52) Cumberland Co. (40) Lehigh Co. (17) Snyder Co. (37) Bedford Co. (44) Dauphin Co. (9) Luzerne Co. (15) Somerset Co. (45) Berks Co. (6) Delaware Co. (4) Lycoming Co. (28) Sullivan Co. (25) Blair Co. (33) Elk Co. (63) McKean Co. (64) Susquehanna Co. (23) Bradford Co. (26) Erie Co. (67) Mercer Co. (55) Tioga Co. (27) Bucks Co. (2) Fayette Co. (46) Mifflin Co. (35) Union Co. (36) Butler Co. (54) Franklin Co. (42) Monroe Co. (19) Venango Co. (56) Cambria Co. (61) Fulton Co. (43) Montgomery Co. (3) Warren Co. (65) Cameron Co. (31) Greene Co. (47) Montour Co. (12) Washington Co. (48) Carbon Co. (16) Huntingdon Co. (34) Northampton Co. (18) Wayne Co. (21) Centre Co. (32) Indiana Co. (60) Northumberland Co. (11) Westmoreland Co. (49) Chester Co. (5) Jefferson Co. (59) Perry Co. (39) Wyoming Co. (24) Clarion Co. (57) Juniata Co. (38) Philadelphia Co. (1) York Co. (8) Clearfield Co. (62) Lackawanna Co. (22) Pike Co. (20)
PA.zip
Unzip the data. You end up with the following directories:
PA/
PA/fon/
PA/lex/
The directory PA/ has the following files:
| PA.cfg | Configuration for drawing maps |
| PA.clp | Include file for maps |
| PA.coo | Coordinates (longitude/latitude) and names of communities |
| PA.geo | The border of Pennsylvania |
| PA.lbl | Numbers and names of communities |
| PA.map | Include file for maps |
| PA.trn | Include file for maps |
The directory PA/fon/ has files with data on pronunciation. This set has only pronunciation variants. Lexical variants are removed from the data. Unlike all other files, these files are not in human readable form, because a font-specific coding is used. The contents of all these files, translated into human readable form is available as a single PDF file (with line numbers added):
phonetic.pdf
The directory PA/lex/ has files with data on choice of words. These files will be used in part 3 of the tutorial.
Measuring the differences is done with the leven program. All details on the use of this program is available in the leven manual page.
Change to the directory PA:
cd PA
Calculate the differences with the following command:
leven -n 67 -l PA.lbl -o fon.dif fon/*.fon
cluster -wm -o fon.clu fon.dif
We can visualise the results in a dendrogram, by using the following command
(see den manual page):
den -o dendrogram.ps fon.clu
The resulting image is stored in the file dendrogram.ps.
You can change the appearance of the dendrogram by using command line options:
den -b .1 -C -e .3333 -n 4 -o dendrogram.ps -p fon.clu
The result is identical to the dendrogram displayed below, except for missing location
numbers. Refer to the manual page for the meaning of the options.
One option, -e .3333, is explained here.
Clustering using Ward's Method has the effect that
when the area doubles in size, the differences are not doubled, but
multiplied by eight. (Other clustering algorithms don't have this property.)
You can compensate for this effect by raising the differences to the power of
1/3 (since 8 raised by 1/3 gives 2), and as a result, the relative differences in
the dendrogram will reflect the true differences. On the x-as below the
dendrogram, you can see that the differences are adjusted.
mapclust -o map.ps PA.cfg fon.clu 4
The result is stored in the file map.ps, and looks like the map below:
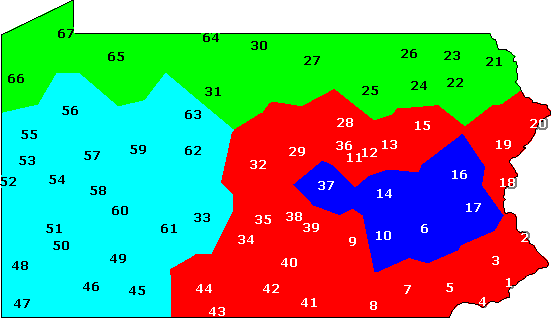
Clustering into four groups, based on phonetic distances.
Most options that determine the overall appearance of maps are stored in a configuration file. That is the file you pass as the first command line argument to the mapclust program, or to one of the other map drawing programs.
Copy the file PA.cfg to PA2.cfg, and open the copy with a text editor. All lines in the file starting with a hash (#) are comments, and ignored by the programs. All other lines are options. Locate the option markers, and remove the word number. Line numbers will no longer appear in the map. Create a new map with:
mapclust -b -s -o map2.ps PA2.cfg fon.clu 4
And make a matching dendrogram with:
den -Q -b .1 -e .3333 -n 4 -o dendro2.ps fon.clu
Refer to the manual pages for mapclust
and den for the meaning of command line
arguments, and the separate manual page for the use of options in the
configuration file.
