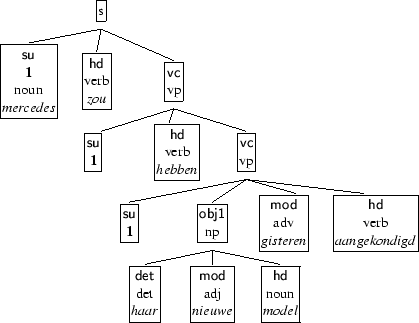
Within the CGN-project [14], guidelines have been developed for syntactic annotation of spoken Dutch [13], using dependency structures similar to those used for the German Negra corpus [18].
Dependency structures make explicit the dependency relations between constituents in a sentence. Each non-terminal node in a dependency structure consists of a head-daughter and a list of non-head daughters, whose dependency relation to the head is marked. A dependency structure for (1) is given in figure 1. Control relations are encoded by means of co-indexing (i.e. the subject of hebben is the dependent with index 1). Note that a dependency structure does not necessarily reflect (surface) syntactic constituency. The dependent haar nieuwe model gisteren aangekondigd, for instance, does not correspond to a (surface) syntactic constituent in (1).
The Alpino grammar produces dependency structures compatible with the CGN-guidelines. We believe this is a useful output format for a number of reasons. First of all, annotating a text with dependency structures is relatively straightforward and independent of the particular grammatical framework assumed. Thus, a dependency treebank can be used to debug and test various versions of the Alpino grammar. Second, as we adopt the CGN-guidelines, a considerable amount of annotated material will be available within the near future which can be used for development and testing. Third, it has been suggested that dependency relations provide a convenient level of representation for evaluation of computational grammar based on radically different grammatical theories [7]. Finally, statistics for dependency relations between head words can be used to develop accurate models for parse-selection [9]; preliminary experiments are described in section 6.
 |