- ... head.1
- Later we will also allow the use of rules with an empty
right-hand-side. These will simply be represented by the predicate
gap/1.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... negation.2
-
This approach also solves another potential problem: the linking table
may give rise to (undesired) cyclic terms due to the absence of the
occur check. The double negation takes care of this potential problem
too.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... avoided.3
- For example, in the Alvey NL Tools
grammar in only 3 (out of more than 700) rules the head of the rule
could be gapped. These rules are of the form
x
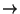 not x.
Arguably, in such rules the second daughter should not be gapped.
In the MiMo2 grammar of English, no heads can be gapped. Finally, in
the Dutch OVIS grammar (in which verb-second is implemented by
gap-threading) no hidden head-recursion occurs, as long as the
head-corner table includes information about the feature
vslash, which encodes whether or not a v-gap is expected.
not x.
Arguably, in such rules the second daughter should not be gapped.
In the MiMo2 grammar of English, no heads can be gapped. Finally, in
the Dutch OVIS grammar (in which verb-second is implemented by
gap-threading) no hidden head-recursion occurs, as long as the
head-corner table includes information about the feature
vslash, which encodes whether or not a v-gap is expected.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... anymore.4
- Note that
such items are not removed, because in that case the item reference
becomes available for later items, which is unsound.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... input.5
- The tree substitution grammar is lexicalized in the sense
that each of the trees has an associated anchor, which is a pointer
to either a lexical entry or a gap.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... table.6
- A complication is needed for
those cases where items are removed later because a more general
item has been found.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... machine.7
- Experiments suggest
that the load on the machine in fact does influence the timings
somewhat. However, the experiments were performed at times when the
load of the machine was low. It is believed, therefore, that no such
artifacts are present in the numbers below.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... Kbytes).8
- These sizes are
obtained using the SICStus prolog built-in predicate
statistics(program_space,X). This only measures the size of
the internal database, but not the size of the stacks. The size of
stacks has never been a problem for any of the parsers; the size
of the internal database has occasionally led to problems for the
bottom-up chart parsers.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... performed.9
- The SPECINT92 figures for the
Ultra 1/140 and HP 735/125 confirm this: 215 and 136 respectively.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... 1/140.10
- Note that Carroll reports on recognition times only, whereas
our results include the construction of all individual parse trees.
For this experiment the left-corner parser used about 163 seconds on
recognition. However, in the recognition phase the parser ignores a
number of syntactic features and therefore this number cannot be
compared fairly with Carroll's number either.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.