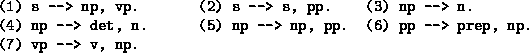Often a distinction is made between recognition and parsing. Recognition checks whether a given sentence can be generated by a grammar. Usually recognizers can be adapted to be able to recover the possible parse trees of that sentence (if any).
In the context of Definite-clause Grammar this distinction is often blurred because it is possible to build up the parse tree as part of the complex non-terminal symbols. Thus the parse tree of a sentence may be constructed as a side-effect of the recognition phase. If we are interested in logical forms rather than in parse trees a similar trick may be used. The result of this however is that already during recognition ambiguities will result in a (possibly exponential) increase of processing time.
For this reason we will assume that parse trees are not built by
the grammar, but rather are the responsibility of the parser. This
allows the use of efficient packing techniques. The result of
the parser will be a parse forest: a compact representation of
all possible parse trees rather than an enumeration of all parse
trees.
The structure of the `parse-forest' in the head-corner parser is rather unusual, and therefore we will take some time to explain it. Because the head-corner parser uses selective memoization, conventional approaches to construct parse forests [2] are not applicable. The head-corner parser maintains a table of partial derivation-trees which each represent a successful path from a lexical head (or gap) up to a goal category. The table consisting of such partial parse trees is called the history table; its items are history-items.
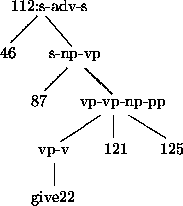
More specifically, each history-item is a triple consisting of a result-item reference, a rule name and a list of triples. The rule name is always the name of a rule without daughters (i.e. a lexical entry or a gap): the (lexical) head. Each triple in the list of triples represents a local tree. It consists of the rule name, and two lists of result-item references (representing the list of daughters left of the head in reverse, and the list of daughters right of the head). An example will clarify this. Suppose we have a history-item:
![\begin{figure}\begin{verbatim}'HISTORY_ITEM'(112,give22,
[rule(vp_v,[],[]), rul...
...25]),
rule(s_np_vp,[87],[]), rule(s_adv_s,[46],[])]).\end{verbatim}\end{figure}](img22.png)
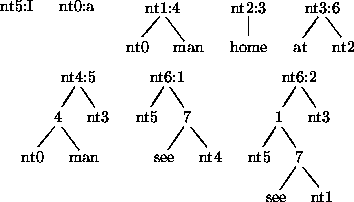
The history table is a lexicalized tree substitution grammar, in which all nodes (except substitution nodes) are associated with a rule identifier (of the original grammar). This grammar derives exactly all derivation trees of the input. 5 As an example, consider the grammar which is used by [24] and [2], given here in (4) and (4).
The sentence `I see a man at home' has two derivations, according to this grammar. The lexicalized tree substitution grammar in figure 5, which is constructed by the head-corner parser, derives exactly these two derivations.
 |
Note that the item references are used in the same manner as the
computer generated names of non-terminals in the approach of
[2]. Because we use chunks of parse trees
less packing is possible than in their approach. Correspondingly, the
theoretical worst-case space requirements are worse too. In practice,
however, this doesn't seem to be problematic at all: in our
experiments the size of the history table is always much smaller than
the size of the other tables (this is expected because the latter
tables have to record complex category information).
Let us now look at how the parser of the previous section can be adapted
to be able to assert history-items. Firstly we add an (output-)
argument to the parse predicate. This sixth argument is the
reference to the result-item that was actually used. The predicates to
parse a list of daughters are augmented with a list of such
references. This enables the construction of a term for each local
tree in the head_corner predicate consisting of the name of the rule
that was applied and the list of references of the result-items used
for the left and right daughters of that rule. Such a local tree
representation is an element of a list that is maintained for each
lexical head upward to its goal. Such a list thus represents in a
bottom-up fashion all rules and result-items that were used to show
that that lexical entry indeed was a head-corner of the goal. If a
parse goal has been solved then this list containing the history
information is asserted in a new kind of table: the 'HISTORY_ITEM'/3 table. 6
We already argued above that parse trees should not be explicitly defined in the grammar. Logical forms often implicitly represent the derivational history of a category. Therefore, the common use of logical forms as part of the categories will imply that you will hardly ever find two different analyses for a single category, because two different analyses will also have two different logical forms. Therefore, no packing is possible and the recognizer will behave as if it is enumerating all parse trees. The solution to this problem is to delay the evaluation of semantic constraints. During the first phase all constraints referring to logical forms are ignored. Only if a parse tree is recovered from the parse-forest we add the logical form constraints. This is similar to the approach worked out in CLE [1].
This approach may lead to a situation in which the second phase actually filters out some otherwise possible derivations, in case the construction of logical forms is not compositional in the appropriate sense. In such cases the first phase may be said to be unsound in that it allows ungrammatical derivations. The first phase combined with the second phase is of course still sound. Furthermore, if this situation arose very often, then the first phase would tend to be useless, and all work would have to be done during the recovery phase. The present architecture of the head-corner parser embodies the assumption that such cases are rare, and that the construction of logical forms is (grosso modo) compositional.
The distinction between semantic and syntactic information is compiled into the grammar rules on the basis of a user declaration. We simply assume that in the first phase the parser only refers to syntactic information, whereas in the second phase both syntactic and semantic information is taken into account.
If we assume that the grammar constructs logical forms, then it is not clear that we are interested in parse trees at all. A simplified version of the recover predicate may be defined in which we only recover the semantic information of the root category, but in which we don't build parse trees. The simplified version may be regarded as the run-time version, whereas parse trees will still be very useful for grammar development.