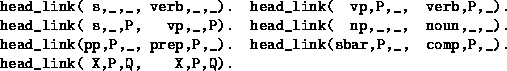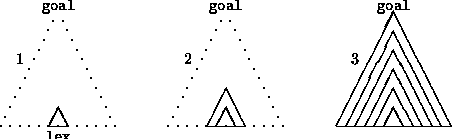 |
Head-corner parsing is a radical approach to head-driven parsing in that it gives up the idea that parsing should proceed from left to right. Rather, processing in a head-corner parser is bidirectional, starting from a head outward (`island'-driven). A head-corner parser can be thought of as a generalisation of the left-corner parser [16,11,14]. As in the left-corner parser, the flow of information in a head-corner parser is both bottom-up and top-down.
In order to explain the parser I first introduce some terminology. I assume that grammars are defined in the Definite Clause Grammar formalism [15]. Without any loss of generality I assume that no external Prolog calls (the ones that are defined within { and }) are used, and that all lexical material is introduced in rules which have no other right-hand-side members (these rules are called lexical entries). The grammar thus consists of a set of rules and a set of lexical entries. For each rule an element of the right-hand-side is identified as the head of that rule. The head-relation of two categories h, m holds with respect to a grammar iff the grammar contains a rule with left hand side m and head daughter h. The relation `head-corner' is the reflexive and transitive closure of the head relation.
The basic idea of the head-corner parser is illustrated in figure 1. The parser selects a word (1), and proves that the category associated with this word is the head-corner of the goal. To this end, a rule is selected of which this category is the head daughter. Then the other daughters of the rule are parsed recursively in a bidirectional fashion: the daughters left of the head are parsed from right to left (starting from the head), and the daughters right of the head are parsed from left to right (starting from the head). The result is a slightly larger head-corner (2). This process repeats itself until a head-corner is constructed which dominates the whole string (3).
Note that a rule is triggered only with a fully instantiated
head-daughter. The `generate-and-test' behaviour observed in the
previous section (examples 1.1 and 1.1)
is avoided in a head-corner parser, because in the cases discussed
there, the rule
would be applied only if the VP is found, and hence Arg is
instantiated. For example if Arg = np(sg3,[],Subj), the parser
continues to search for a singular NP, and need not consider
other categories.
To make the definition of the parser easier, and to make sure that rules are indexed appropriately, grammar rules are represented by the predicate headed_rule/4 in which the first argument is the head of the rule, the second argument is the mother node of the rule, the third argument is the reversed list of daughters left of the head, and the fourth argument is the list of the daughters right of the head. 1 This representation of a grammar will in practice be compiled from a friendlier notation.
As an example, the DCG rule
x(A,E) --> a(A), b(B,A), x(C,B), d(C,D), e(D,E).of which the third daughter constitutes the head, is represented now as:
headed_rule( x(C,B), x(A,E), [b(B,A), a(A)], [d(C,D), e(D,E)]).
It is assumed furthermore that lexical lookup has been performed already by another module. This module has asserted clauses for the predicate lexical_analysis/3 where the first two arguments are the string positions and the third argument is the (lexical) category. For an input sentence `Time flies like an arrow' this module may produce the following set of clauses:
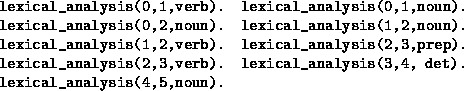
A simple definite-clause specification of the head-corner parser is given in figure 2. The predicate visible to the rest of the world will be the predicate parse/3. This predicate is defined in terms of the parse/5 predicate. The extra arguments introduce a pair of indices which represent the extreme positions between which a parse should be found. This will be explained in more detail below. A goal category can be parsed if a predicted lexical category can be shown to be a head-corner of that goal. The head-corner predicate constructs (in a bottom-up fashion) larger and larger head-corners. To parse a list of daughter categories we have to parse each daughter category in turn. A predicted category must be a lexical category that lies somewhere between the extreme positions. The predicate smaller_equal is true if the first argument is a smaller or equal integer than the second. The use of the predicates head_link and lex_head_link is explained below.
Note that unlike the left-corner parser, the head-corner parser may need to consider alternative words as a possible head-corner of a phrase, e.g. when parsing a sentence which contains several verbs. This is a source of inefficiency if it is difficult to determine what the appropriate lexical head for a given goal category is. This problem is somewhat reduced because of:
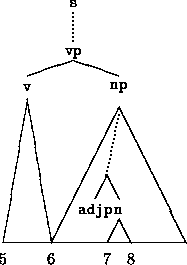
Observe that each parse-goal in the left-corner parser is provided with a category and a left-most position. In the head-corner parser a parse-goal is provided either with a begin or end position (depending on whether we parse from the head to the left or to the right) but also with the extreme positions between which the category should be found. In general, the parse predicate is thus provided with a category and two pairs of indices. The first pair indicates the begin and end position of the category, the second pair indicates the extreme positions between which the first pair should lie. In figure 3 the motivation for this technique is illustrated with an example.
 |
As in the left-corner parser, a `linking' table is maintained which represents important aspects of the head-corner relation. For some grammars, this table simply represents the fact that the HEAD features of a category and its head-corner are shared. Typically, such a table makes it possible to predict that in order to parse a finite sentence, the parser should start with a finite verb; to parse a singular noun-phrase the parser should start with a singular noun, etc.
The table is defined by a number of clauses for the predicate head_link/2 where the first argument is a category for which the second argument is a possible head-corner. A sample linking table may be:
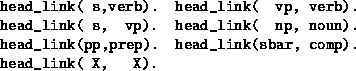
The head-corner table also includes information about begin and end
positions, following an idea in [21]. For example,
if the goal is to parse a phrase with category sbar from
position 7, and within positions 7 and 12, then for some grammars it
can be concluded that the only possible lexical head-corner for this goal
should be a complementizer starting at position 7. Such information is
represented in the table as well. This can be done by defining the
head relation as a relation between two triples, where each triple
consists of a category and two indices (representing the begin and end
position). The head relation
![]()
![]() cm, pm, qm
cm, pm, qm![]() ,
,![]() ch, ph, qh
ch, ph, qh![]()
![]() holds iff there
is a grammar rule with mother cm and head ch. Moreover, if the
list of daughters left of the head of that rule is empty, then the
begin positions are identical, i.e. ph = pm. Similarly, if the
list of daughters right of the head is empty, then qh = qm. As
before, the head-corner relation is the reflexive and transitive
closure of the head relation.
holds iff there
is a grammar rule with mother cm and head ch. Moreover, if the
list of daughters left of the head of that rule is empty, then the
begin positions are identical, i.e. ph = pm. Similarly, if the
list of daughters right of the head is empty, then qh = qm. As
before, the head-corner relation is the reflexive and transitive
closure of the head relation.
The previous example now becomes:
Obviously, the nature of the grammar determines whether it is useful to represent such information. In order to be able to run a head-corner parser in left-corner mode, this technique is crucial. On the other hand, for grammars in which this technique does not provide any useful top-down information no extra costs are introduced either.
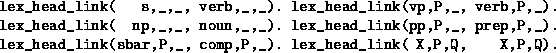
A few potential problems arise in connection with the use of linking tables. Firstly, for constraint-based grammars of the type assumed here the number of possible non-terminals is infinite. Therefore, we generally cannot use all information available in the grammar but rather we should compute a `weakened' version of the linking table. This can be accomplished for example by replacing all terms beyond a certain depth by anonymous variables, or by other restrictors [19].
Secondly, the use of a linking table may give rise to spurious ambiguities. Consider the case in which the category we are trying to parse can be matched against two different items in the linking table, but in which case the predicted head-category may turn out to be the same.
Fortunately, the memoization technique discussed in section 3 takes care of this problem. Another possibility is to use the linking table only as a check, but not as a source of information, by encapsulating the call within a double negation. 2
The solution implemented in the head-corner parser is to use, for each pair of functors of categories, the generalization of the head-corner relation. Such functors typically are major and minor syntactic category labels such as NP, VP, S, SBAR, VERB .... As a result there will always be at most one matching clause in the linking table for a given goal category and a given head category (thus there is no risk of obtaining spurious ambiguities). Moreover, this approach allows a very efficient implementation technique which is described in the following paragraph.
In the implementation of the head-corner parser we use an efficient implementation of the head-corner relation by exploiting Prolog's first argument indexing. This technique ensures that the lookup of the head-corner table can be done in (essentially) constant time. The implementation consists of two step. In the first step the head-corner table is weakened such that for a given goal category and a given head category at most a single matching clause exists. In the second step this table is encoded in such a way that first argument indexing ensures that table lookup is efficient.
As a first step we modify the head-corner relation to make sure that for all pairs of functors of categories, there will be at most one matching clause in the head-corner table. This is illustrated with an example. Suppose a hypothetical head-corner table contains the following two clauses relating categories with functor x/4 and y/4:
head_link(x(A,B,_,_),_,_,y(A,B,_,_),_,_). head_link(x(_,B,C,_),_,_,y(_,B,C,_),_,_).In this case, the modified head-corner relation table will consist of a single clause relating x/4 and y/4 by taking the generalization (or `anti-unification') of the two clauses:
head_link(x(_,B,_,_),_,_,y(_,B,_,_),_,_).As a result, for a given goal and head category, table lookup is deterministic.
In the second and final step of the modification we re-arrange the information in the table such that for each possible goal category functor g/n there will be a clause:
head_link(g(A1..An),Pg,Qg,Head,Ph,Qh) :-
head_link_G_N(Head,Ph,Qh,g(A1..An),Pg,Qg).
Moreover, all the relations head_link_G_N now contain the
relevant information from the head-corner table. Thus, for
clauses of the form:
head_link(x(_,B,_,_),_,_,y(_,B,_,_),_,_).we now have:
head_link_x_4(y(_,B,_,_),_,_,x(_,B,_,_),_,_).First argument indexing now ensures that table lookup is efficient.
The same technique is applied for the lex_head_link relation. This technique significantly improved the practical time efficiency of the parser (especially if the resulting code is compiled).
In the preceding paragraphs we have said nothing about empty
productions (epsilon rules). A possible approach is to compile the
grammar into an equivalent grammar in which no such epsilon rules are
defined. It is also possible to deal with epsilon rules in the
head-corner parser directly. For example, we could assert
empty productions as possible `lexical analyses'. In
such an approach the result of lexical analysis may contain clauses
such as the following, in case there is a rule np/np --> [].
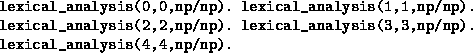
There are two objections to this approach. The first objection may be that this is a task that can hardly be expected from a lexical lookup procedure. The second, more important, objection is that empty categories are hypothesized essentially everywhere.
In the general version of the head-corner parser gaps are inserted by a special clause for the predict/8 predicate (2.3) where shared variables are used to indicate the corresponding string positions. The gap_head_link relation is a subset of the head_link relation in which the head category is a possible gap.
In order for this approach to work other predicates must expect string positions which are not instantiated. For example, Prolog's built-in comparison operator cannot be used, since that operator requires that its arguments are ground. The definition of the smaller_equal predicate therefore reflects the possibility that a string position is a variable (in which case calls to this predicate should succeed).For some grammars it turns out that a simplification is possible. If it is never possible that a gap can be used as the head of a rule, then we can omit this new clause for the predict predicate, and instead use a new clause for the parse/5 predicate, as follows:
This will typically be much more efficient because in this case gaps are hypothesized in a purely top-down manner.It should be noted that the general version of the head-corner parser is not guaranteed to terminate, even if the grammar defines only a finite number of derivations for all input sentences. Thus, even though the head-corner parser proceeds in a bottom-up direction, it can run into left-recursion problems (just like the left-corner parser can). This is because it may be possible that an empty category is predicted as the head, after which trying to construct a larger projection of this head gives rise to a parse goal for which a similar empty category is a possible candidate head .... This problem is sometimes called `hidden left-recursion' in the context of left-corner parsers.
This problem can be solved in some cases by a good (but relatively expensive) implementation of the memoization technique, e.g. along the lines of [32] or [7]. The simplified (and more efficient) memoization technique that I use (cf. section 3) however does not solve this problem.
A quite different solution, which is often applied for the same
problem if a left-corner parser is used, is to compile the grammar
into an equivalent grammar without gaps. For left-corner parsers this
can be achieved by partially evaluating all rules which can take
gap(s) as their left-most daughter(s). Therefore, the parser only
needs to consider gaps in non-leftmost position by a clause similar to
the clause in 2.3. Obviously, the same compilation technique can
be applied for the head-corner parser too. However, there is a
problem: it will be unclear what the heads of the newly created rules
will be. Moreover and more importantly, the head-corner relation will
typically become much less predictive. For example, if there is a rule
vp --> np verb where the verb can be realized as a gap,
then after compilation a rule of the form vp -> np will exist.
Therefore, a np will be a possible head-corner of vp. The
effect will be that head-corners are difficult to predict, and hence
efficiency decreases.
Experience suggests that grammars exhibiting `hidden head-recursion' can often be avoided. 3