In this section I present a simple F-LCFR grammar for a (tiny)
fragment of Dutch. As a caveat I want to stress that the purpose of
the current section is to provide an example of possible input
for the parser to be defined in the next section, rather than to
provide an account
that is completely satisfactory from a linguistic point of view.
There is only one parameterized, binary branching, rule in the grammar:
![\pr\pred
\head{sign(\avm[M]{ syn: Syn \\
sc: Tail \\
sem: Sem)
} {\mbox{\tt ...
...\rangle\\
sem: Sem} ) , }
\body{sign(Arg) ,}
\body{cb(M, H, Arg).}
\epred\epr](img26.png)
In this grammar rule, heads select arguments using a subcat list. Argument structures are specified lexically and are percolated from head to head. Syntactic features are shared between heads (hence I make the simplifying assumption that head = functor, which may have to be revised in order to treat modification). The relation `cb' defines how the string of the mother is constructed from its daughters. In the grammar I use revised versions of Pollard's head wrapping operations to analyse cross serial dependency and verb second constructions. For a linguistic background of these constructions and analyses, cf. [6], [14] and many others. The value of the attribute phon consists of three parts, to implement the idea of Pollard's `headed strings'. The parts left and right represent the strings left and right of the head. The part head represent the head string. Hence, the string associated with such a term is the concatenation of the three arguments from left to right. The predicate cb is defined as follows:

Here, the values of the attribute phon associated with the two daughters of the rule are to be combined by the wrap predicate. Several versions of this predicate will be defined below. The value of `string' of the mother node is defined with respect to its `phon' value by the predicate phon_string. This predicate is defined in terms of the predicate append /3. As an abbreviation I write A . B for C such that append (A, B, C). The definitions of both predicates follow:
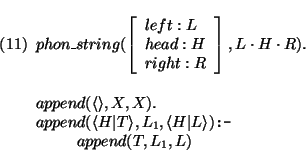
There are a few versions of the predicate wrap to illustrate the idea that different string operations can be defined. Each version of the predicate will be associated with an atomic identifier to allow lexical entries to subcategorize for their arguments under the condition that a specific version of this predicate be used. The purpose of this feature is similar to the `order' feature found in UCG [33]. For example, a verb may select an object to its left, and an infinite verb phrase which has to be raised. For simple (left or right) concatenation the predicate is defined as follows:

In the first case the string associated with the argument is appended to the left of the string left of the head; in the second case this string is appended to the right of the string right of the head. Lexical entries for intransitive verbs such as `ontwaakt' (wakes up) are defined as follows:
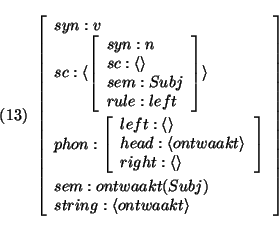
I assume that lexical entries also specify that their string-value is functionally dependent of the phon value. Furthermore, the values of the left and right attributes of phon are the empty list. Henceforth, I will not specify the value of string explicitly, but assume that each lexical entry extends
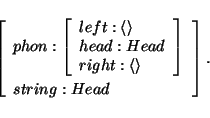
Hence, bitransitive verbs such as `vertelt' (tells) are abbreviated as follows:

A different version of this lexical entry selects an SBAR to the right:

Proper nouns such as `Arie' are simply defined as:

For the sake of the example I assume several other NP's to have such a
definition.
The choice of datastructure for the value of the attribute phon allows a simple definition of the verb raising (vr) version of the wrap predicate that may be used for Dutch cross serial dependencies:
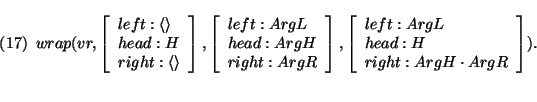
Here the head and right string of the argument are appended to the right, whereas the
left string of the argument is appended to the left.
A raising verb, eg. `hoort' (hears) is defined as:
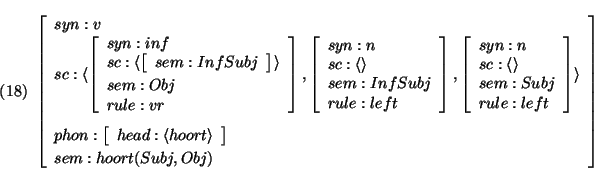
In this entry `hoort' selects -- apart from its NP-subject -- two objects, a NP
and a VP (with category INF).
The INF still has an element in its subcat list; this element is
controlled by the NP (this is performed by the sharing of InfObj).
To derive the subordinate phrase
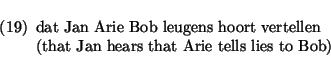
the main verb `hoort' first selects
the infinitival `bob leugens vertellen'. These two
strings are combined into `bob leugens hoort vertellen' (using the vr version
of the wrap predicate). After the selection of the object, resulting in `arie bob
leugens hoort vertellen',
the subject is selected
resulting in the string `jan arie bob leugens hoort vertellen'. This string is selected by
the complementizer, resulting in `dat jan arie bob leugens hoort vertellen'. The argument
structure will be instantiated as dat(hoort(jan,vertelt(arie,bob,leugens))).
In Dutch main clauses, there usually is no overt complementizer; instead the finite verb occupies the first position (in yes-no questions), or the second position (right after the topic; ordinary declarative sentences). In the following analysis an empty complementizer selects an ordinary (finite) v; the resulting string is formed by the following definition of wrap:
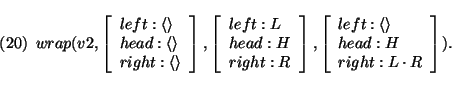
The `empty' finite complementizer is defined as:

whereas an ordinary complementizer, eg. `dat' (that) is defined as:

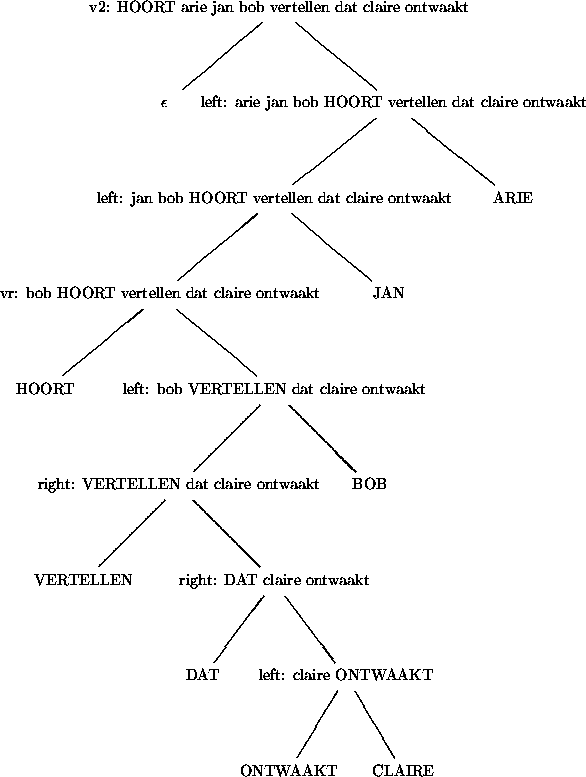
Note that this analysis captures the special relationship between complementizers and (fronted) finite verbs in Dutch. The sentence

is derived as in
figure 5 (where the head of a string is represented in capitals).
What remains to be done is to define the two grammar specific predicates head/2 and string/2. These are simply defined as follows: