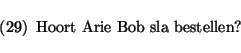This section describes the head-driven parsing algorithm for the type of grammars described above.
The parser is a generalization of Kay's head-driven parser, which in turn is a modification
of a left-corner parser.
The parser, which may be called a `head-corner' parser,1 proceeds in a
bottom-up way. Because the parser proceeds from head to head it is easy to use powerful
top-down predictions based on the usual head feature percolations, and subcategorization
requirements that heads require from their arguments.
In fact, the motivation for this approach to parsing discontinuous constituency is already
hinted at by Mark Johnson [11]:
My own feeling is that the approach that would bring the most immediate results would be to adopt some of the ``head driven'' aspects of Pollard's (1984) Head Grammars. In his conception, heads contain as lexical information a list of the items they subcategorize for. This strongly suggests that one should parse according to a ``head-first'' strategy: when one parses a sentence, one looks for its verb first, and then, based on the lexcial form of the verb, one looks for the other arguments in the clause. Not only would such an approach be easy to implement in a DCG framework, but given the empirical fact that the nature of argument NP's in a clause is strongly determined by that clause's verb, it seems a very reasonable thing to do.It is clear from the context that Johnson believes this strategy especially useful for non-configurational languages.
In left-corner parsers [15] the first step of the algorithm is to select the left-most word of a phrase. The parser then proceeds by proving that this word indeed can be the left-corner of the phrase. It does so by selecting a rule whose leftmost daughter unifies with the category of the word. It then parses other daughters of the rule recursively and then continues by connecting the mother category of that rule upwards, recursively. The left-corner algorithm can be generalized to the class of grammars under consideration if we start with the lexical head of a phrase, instead of its leftmost word. Furthermore the head_corner predicate then connects smaller categories upwards by unifying them with the head of a rule. The first step of the algorithm consists of the prediction step: which lexical entry is the lexical head of the phrase? The first thing to note is that the words introduced by this lexical entry should be part of the input string, because of the nonerasure requirement. Therefore we use the bag of words as a `guide' [5] as in a left-corner parser, but we change the way in which lexical entries `consume the guide'. For the moment I assume that the bag of words is simply represented with the string, but I introduce a better datastructure for bags in the next section. Hence to get things going I define the predicate start_parse/1 as follows:

Furthermore in most linguistic theories it is assumed that certain features are shared between the mother and the head. I assume that the predicate head/2 defines these feature percolations; for the grammar of the foregoing section this predicate was defined as:
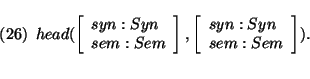
As we will proceed from head to head these features will also be shared between the lexical head and the top-goal; hence we can use this definition to restrict lexical lookup by top-down prediction. 2 The first step in the algorithm is defined as:

Instead of taking the first word from the current input string, the
parser may select a lexical entry dominating a subset of the words
occuring in the input string, provided this lexical entry can be the
lexical head of the current goal. The predicate
subset(L1, L2, L3) is true in case L1 is a subset of L2 with
complement L3.
Later we will improve on the indexing of lexical entries.
The second step of the algorithm, the head_corner part, is identical to the left_corner part of the left-corner parser, but instead of selecting the leftmost daughter of a rule the head-corner parser selects the head of a rule. Remember that nonunit rules are represented as:

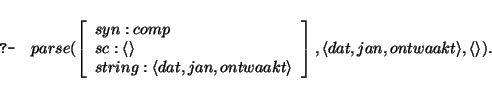
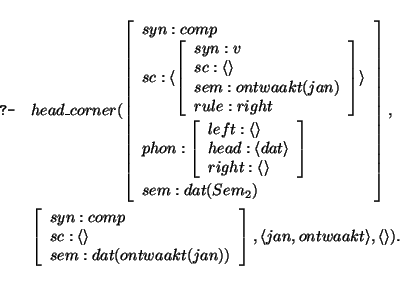
The prediction step selects the lexical entry `dat'. The next goal is to show
that this lexical entry is the lexical head of the top goal; furthermore the string
that still has to be covered is now
![]() jan, ontwaakt
jan, ontwaakt![]() . Leaving details out
the head_corner clause looks as :
. Leaving details out
the head_corner clause looks as :

The category of dat has to be matched with the head of a rule. Notice that
dat subcategorizes for a v with rule feature right. Hence the right version
of the wrap predicate applies, and the next goal is to parse the v for which this
complementizer subcategorizes, with input `jan, ontwaakt':
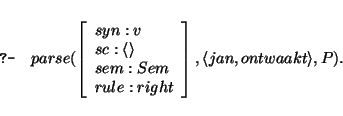
Lexical lookup selects the word ontwaakt from this string. The word ontwaakt has to be shown to be the head of this v node, by the head_corner predicate:
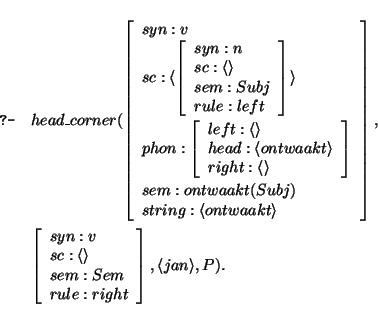
This time the left combination rule applies and
the next goal consists in parsing a NP (for which ontwaakt subcategorizes) with input
string jan. This goal succeeds with an empty output string. Hence the argument of
the rule has been found successfully and hence we need to connect the
mother of the rule up to the v node. This succeeds trivially, instantiating the
head_corner call above to:
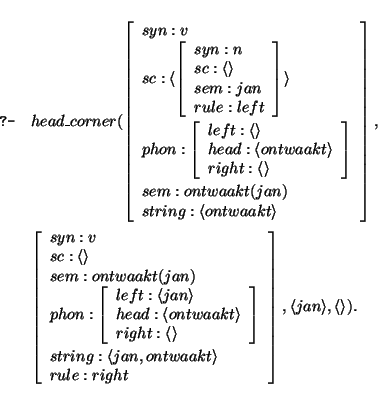
and therefore we now have found the v for which dat subcategorizes, instantiating the parse goal above to:

Hence the next goal is to connect
the complementizer with an empty subcat list up to the topgoal; again this succeeds
trivially. Hence we obtain the instantiated version of the first
head_corner call:
and the first call to parse will succeed, yielding:

The flow of control of the parsing process for this example is shown in figure 6.
In this picture, the integers associated with the arrows indicate the order of the steps of the parsing process. Predict steps are indicated with a framed integer, head_corner steps are indicated with a bold face integer, and recursive parse steps are indicated with a slanted integer. The nodes represent (some of) the information available at the moment this step is performed.A slightly more complex example is shown in figure 7, for the sentence
![\includegraphics[scale=0.6]{aresla.ps}](img58.png)
![\begin{figure}
\begin{Tree}
\node{\type{text}\external\cntr{dat,comp[v]}}
\node{...
...}}
\put(204,530){\bf 10}\put(200,557){\vector(0,1){0}}
\end{picture}\end{figure}](img56.png)